Clear Sky Science · en
Grammar as a behavioral biometric: using cognitively motivated grammar models for authorship verification
Why Your Writing Style Is Like a Fingerprint
Every time you write—whether it’s an email, a review, or a social media post—you reveal more about yourself than you might think. Beyond the topics you choose, the tiny building blocks of your sentences, such as little words and punctuation, form patterns that are surprisingly personal. This article explores a new way to use those patterns to tell whether two texts were written by the same person, with potential implications for law, security, and our understanding of how language lives in the mind.
How Investigators Decide Who Wrote What
In digital text forensics, experts often face questions like: Did the same person write this threatening email and this earlier message? Are two online accounts controlled by one individual? Traditional approaches to these authorship problems fall into three camps. Some compare only texts from the known author with the disputed text. Others train a classifier on many examples of matching and non-matching pairs. A third group, which this paper focuses on, brings in an outside “reference population” of texts to understand how unusual a particular writing style is compared with many other writers. Over the last decade, powerful but opaque techniques—especially those based on character snippets and deep neural networks—have dominated shared tasks and benchmarks. However, they can be slow, hard to interpret, and sometimes driven more by topic than by a writer’s true stylistic habits.
From Phrases to Habits in the Mind
The authors ground their new method in Cognitive Linguistics, a field that treats grammar not as a set of rigid rules, but as a network of learned patterns. According to this view, our brains “chunk” frequently repeated sequences—like “of the” or “I don’t know”—into units that become automatic, much like well-practiced dance steps. These units sit on a continuum from fixed expressions to flexible templates and more abstract structures. Because our experiences and reading histories differ, the particular combinations that become deeply entrenched in our minds are also different. This “principle of linguistic individuality” suggests that no two people share exactly the same internal grammar. The paper argues that this individualized grammar can function as a kind of behavioral biometric, comparable in spirit to handwriting or gait.
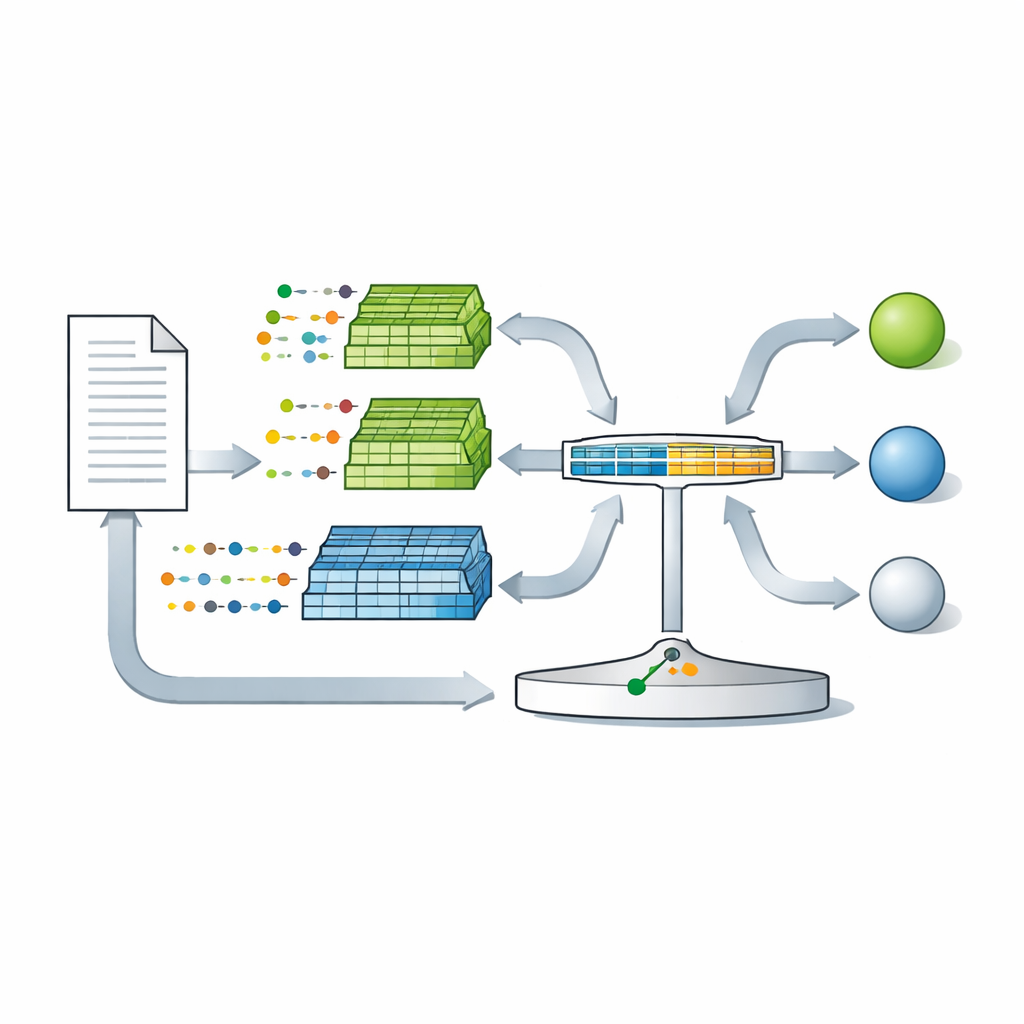
Turning Hidden Grammar into a Measurable Signal
Building on this theory, the authors introduce LambdaG, a method that models an author’s grammar while deliberately ignoring topics and content words. First, texts are passed through a filter that keeps only function words, punctuation, and a few abstract categories, stripping away names and specific content. These filtered texts are split into sentences and fed into a statistical “n-gram” model that learns how likely each small sequence of grammatical tokens is for that author. A second set of models, trained on many other writers, plays the role of the comparison population. For every token in a disputed text, LambdaG asks: how much more natural is this token in this context for the candidate author than for the reference writers? These comparisons are combined into a single score that reflects both similarity to the candidate and rarity in the broader population. A simple logistic regression then calibrates this score so it can be interpreted like a graded strength of evidence in forensic settings.
How Well the New Method Stacks Up
The authors test LambdaG on twelve datasets that mimic real-world situations: emails, chat logs, reviews, news articles, and more, often with relatively short texts. They compare it against seven strong baselines, including the influential Impostors Method, a compression-based approach, a topic-agnostic ensemble, and several deep neural systems. Across measures such as accuracy and area under the ROC curve, LambdaG ranks first on most datasets and second on several others, often outpacing neural models even when those models are allowed to exploit full content. It is also less sensitive than earlier methods to changes in the reference population: performance does drop when the reference texts come from a very different genre, but not to the point of becoming useless. Because LambdaG’s score can be broken down sentence by sentence and even token by token, analysts can produce heat maps that visually highlight which patterns in a text were most influential in the decision.
What It Means for Identity and Privacy
The study concludes that an individual’s grammar—the way they habitually weave together small words, punctuation, and recurring patterns—acts much like a behavioral biometric. Even in as few as one to two thousand words, LambdaG can often uncover idiosyncratic sequences that strongly distinguish one person from others, and the authors argue that many such units are not consciously controlled by writers themselves. This has clear benefits for forensic work: it offers a method that is relatively simple, empirically strong, and anchored in a well-developed linguistic theory, making its reasoning easier to explain in court. At the same time, it underscores a privacy-relevant point: our everyday writing quietly carries a stable, identifiable signature, rooted not in what we say, but in how our minds have learned to say it.
Citation: Nini, A., Halvani, O., Graner, L. et al. Grammar as a behavioral biometric: using cognitively motivated grammar models for authorship verification. Humanit Soc Sci Commun 13, 455 (2026). https://doi.org/10.1057/s41599-025-06340-3
Keywords: authorship verification, stylometry, forensic linguistics, behavioral biometrics, grammar modeling