Clear Sky Science · fr
La grammaire comme biométrie comportementale : utiliser des modèles de grammaire motivés cognitivement pour la vérification d’auteur
Pourquoi votre style d’écriture est comme une empreinte digitale
Chaque fois que vous écrivez — qu’il s’agisse d’un courriel, d’un avis ou d’un message sur les réseaux sociaux — vous révélez plus de choses sur vous que vous ne le pensez peut‑être. Au‑delà des sujets que vous abordez, les petites unités de vos phrases, comme les mots fonctionnels et la ponctuation, forment des motifs étonnamment personnels. Cet article explore une nouvelle manière d’utiliser ces motifs pour déterminer si deux textes ont été écrits par la même personne, avec des implications possibles pour le droit, la sécurité et notre compréhension de la façon dont le langage est représenté dans l’esprit.
Comment les enquêteurs décident qui a écrit quoi
En informatique légale des textes, les experts se confrontent souvent à des questions du type : la même personne a‑t‑elle écrit ce courriel menaçant et ce message antérieur ? Deux comptes en ligne appartiennent‑ils à un seul individu ? Les approches classiques de ces problèmes d’attribution se répartissent en trois groupes. Certaines ne comparent que des textes de l’auteur connu avec le texte contesté. D’autres entraînent un classifieur sur de nombreux exemples de paires concordantes et non concordantes. Un troisième groupe, sur lequel cet article se concentre, fait appel à une « population de référence » externe de textes pour évaluer à quel point un style d’écriture est inhabituel par rapport à de nombreux autres écrivains. Au cours de la dernière décennie, des techniques puissantes mais opaques — notamment celles fondées sur des fragments de caractères et des réseaux neuronaux profonds — ont dominé les tâches partagées et les bancs d’essai. Elles peuvent toutefois être lentes, difficiles à interpréter et parfois davantage influencées par le sujet que par les véritables habitudes stylistiques de l’auteur.
Des locutions aux habitudes mentales
Les auteurs ancrent leur nouvelle méthode dans la linguistique cognitive, un domaine qui considère la grammaire non pas comme un ensemble de règles rigides, mais comme un réseau de schèmes appris. Selon cette perspective, notre cerveau « regroupe » des séquences répétées — comme « of the » ou « I don’t know » — en unités qui deviennent automatiques, à l’image de pas de danse bien rodés. Ces unités se situent sur un continuum allant d’expressions figées à des modèles flexibles et à des structures plus abstraites. Parce que nos expériences et nos habitudes de lecture diffèrent, les combinaisons particulières qui s’enracinent profondément dans nos esprits varient aussi d’une personne à l’autre. Ce « principe d’individualité linguistique » suggère qu’aucun individu ne partage exactement la même grammaire interne qu’un autre. Les auteurs défendent l’idée que cette grammaire individualisée peut fonctionner comme une sorte de biométrie comportementale, comparable en esprit à l’écriture manuscrite ou à la manière de marcher.
Transformer la grammaire cachée en signal mesurable
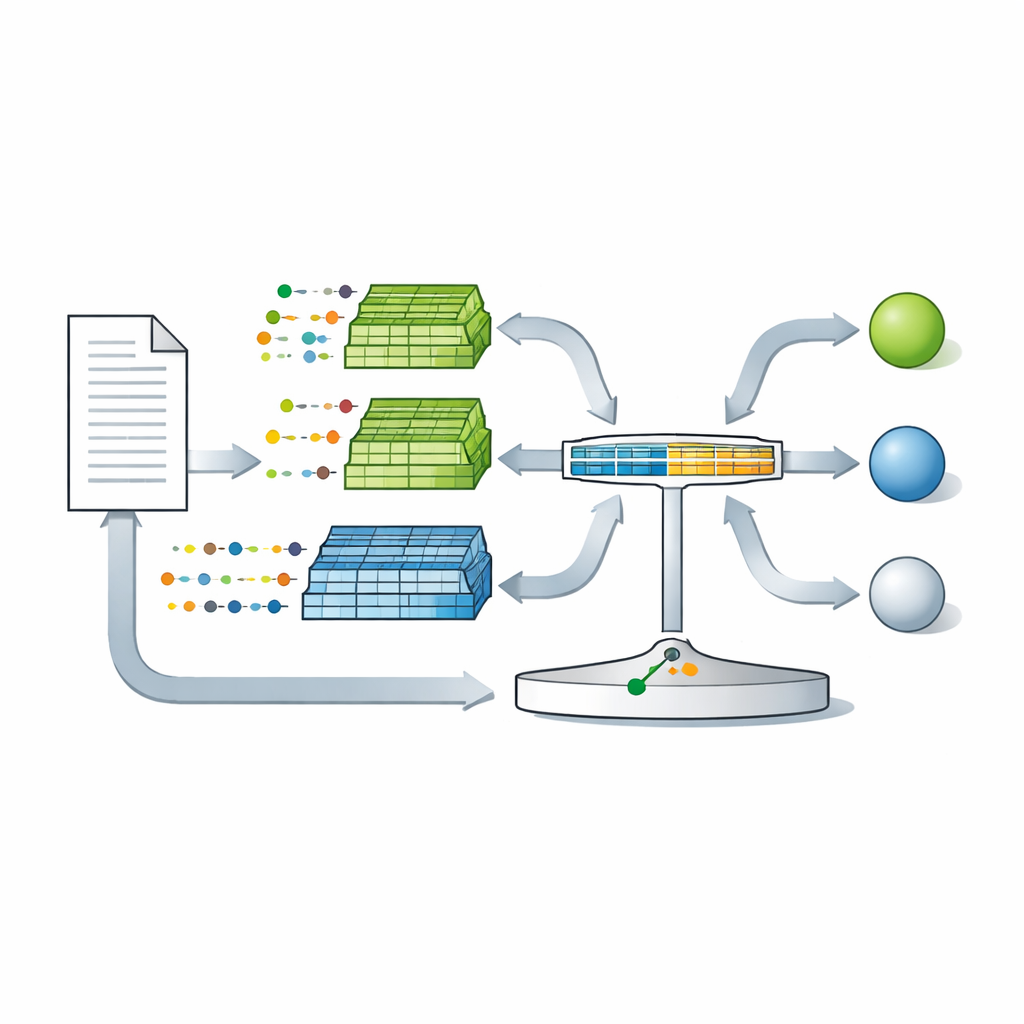
À partir de cette théorie, les auteurs présentent LambdaG, une méthode qui modélise la grammaire d’un auteur en ignorant délibérément les sujets et les mots lexicaux. D’abord, les textes sont filtrés pour ne conserver que les mots fonctionnels, la ponctuation et quelques catégories abstraites, écartant les noms propres et le contenu spécifique. Ces textes filtrés sont découpés en phrases puis introduits dans un modèle statistique « n‑gramme » qui apprend la probabilité de chaque petite séquence de tokens grammaticaux pour cet auteur. Un second ensemble de modèles, entraîné sur de nombreux autres écrivains, joue le rôle de population de comparaison. Pour chaque token d’un texte contesté, LambdaG demande : dans quelle mesure ce token est‑il plus naturel dans ce contexte pour l’auteur candidat que pour les auteurs de référence ? Ces comparaisons sont agrégées en un score unique reflétant à la fois la similarité avec le candidat et la rareté dans la population plus large. Une régression logistique simple calibre ensuite ce score afin qu’il puisse être interprété comme une force de preuve graduée dans un contexte médico‑légal.
Quelle est l’efficacité de la nouvelle méthode
Les auteurs testent LambdaG sur douze jeux de données reproduisant des situations réelles : courriels, historiques de chat, avis, articles de presse, etc., souvent avec des textes relativement courts. Ils le comparent à sept solides méthodes de référence, dont l’influente Impostors Method, une approche basée sur la compression, un ensemble indépendant du sujet et plusieurs systèmes neuronaux profonds. Selon des mesures telles que la précision et l’aire sous la courbe ROC, LambdaG arrive en tête sur la plupart des jeux de données et en deuxième position sur plusieurs autres, dépassant souvent les modèles neuronaux même lorsque ces derniers peuvent exploiter le contenu complet. Il est également moins sensible que les méthodes antérieures aux changements dans la population de référence : les performances chutent lorsque les textes de référence proviennent d’un genre très différent, mais pas au point de devenir inutilisables. Parce que le score de LambdaG peut être décomposé phrase par phrase et même token par token, les analystes peuvent produire des cartes thermiques qui mettent visuellement en évidence les motifs d’un texte ayant le plus influencé la décision.
Conséquences pour l’identité et la vie privée
L’étude conclut que la grammaire d’un individu — la manière dont il assemble habituellement petits mots, ponctuation et motifs récurrents — agit en grande partie comme une biométrie comportementale. En aussi peu que mille à deux mille mots, LambdaG peut souvent révéler des séquences idiosyncratiques qui distinguent fortement une personne des autres, et les auteurs soutiennent que nombre de ces unités ne sont pas contrôlées consciemment par les écrivains. Cela présente des avantages évidents pour le travail médico‑légal : la méthode est relativement simple, empiriquement performante et ancrée dans une théorie linguistique bien développée, ce qui rend son raisonnement plus facile à expliquer devant un tribunal. En même temps, cela souligne un enjeu de confidentialité : notre écriture quotidienne porte discrètement une signature stable et identifiable, fondée non sur ce que nous disons, mais sur la façon dont nos esprits ont appris à le dire.
Citation: Nini, A., Halvani, O., Graner, L. et al. Grammar as a behavioral biometric: using cognitively motivated grammar models for authorship verification. Humanit Soc Sci Commun 13, 455 (2026). https://doi.org/10.1057/s41599-025-06340-3
Mots-clés: vérification d’auteur, stylométrie, linguistique médico-légale, biométrie comportementale, modélisation grammaticale