Clear Sky Science · sv
En exempelmodell för att tillämpa funktionsurval och maskininlärning för att uppskatta och hantera signalkräftbestånd
Varför räkning av kräftor nu kräver smarta verktyg
När världens aptit på skaldjur växer finns det ett ökat tryck på förvaltare att bevara vilda bestånd samtidigt som man förser människor med mat. Signalkräfta är ett näringsrikt, fettsnålt delikatesskött som kan odlas med relativt måttliga vattenresurser, men sjukdomar, överfiske och föroreningar har gjort deras populationer svårare att förutsäga. Denna studie visar hur moderna datatekniker, lånade från artificiell intelligens, kan förvandla enkla kroppsmått på kräftor till kraftfulla ledtrådar om tillväxt, köttutbyte och beståndsstorlek — vilket hjälper fiskerier att vara både lönsamma och hållbara.
Kräftor som en framtida matkällan
Signalkräfta är rik på protein och viktiga mineraler men låg i fett och kalorier, vilket gör dem till ett attraktivt alternativ där högkvalitativ animalisk protein är knapp eller dyr. De tolererar dessutom en rad miljöförhållanden och kan odlas i dammar, vattenreservoarer eller till och med risfält med relativt låga insatser. Samtidigt förväntas global klimatförändring och en växande befolkning driva upp efterfrågan på mat kraftigt under de kommande decennierna. Eftersom kräftbestånd redan visat upp- och nedgångar till följd av epidemier, intensivt fiske och vattenföroreningar finns ett akut behov av bättre verktyg för att följa deras status och planera skördar utan att uttömma denna värdefulla resurs.
Att omvandla fältmätningar till användbar data
Forskarna koncentrerade sig på en stor signalkräftpopulation i Turkiets Atikhisar-reservoar, där de samlade in detaljerade mätningar från 6 470 smalklövade kräftor. För varje individ registrerades 20 egenskaper, inklusive total längd, bredder och längder på viktiga kroppsdelar samt vikter för huvud, bakkropp och klor, liksom det ätbara köttet inuti. Dessa mätningar togs med precisa skjutmått och vågar och rengjordes sedan genom en enkel medelvärdesmetod för att fylla i eventuella saknade värden. Teamet använde också klassiska längd-vikt-formler som används inom fiskeri för att se hur totallängd relaterar till totalvikt och för att verifiera hur djuren växer över tid.
Att hitta de mest avslöjande kroppsparametrarna
Inte varje mätning tillför användbar information, och extra, svagt relaterade egenskaper kan sakta ner eller förvirra datoriserade modeller. För att sålla signal från brus använde författarna ett statistiskt verktyg som poängsätter hur starkt varje egenskap rör sig med totalvikt. De behöll endast de mätningar som visade åtminstone en måttlig koppling, såsom totallängd, huvudets längd och bredd, bakkroppens längd och bredd samt de olika del- och köttvikterna. Detta steg minskade kraftigt antalet indata modellerna behövde beakta, samtidigt som nästan all information som behövdes för att beskriva hur tung en kräfta sannolikt är bevarades.
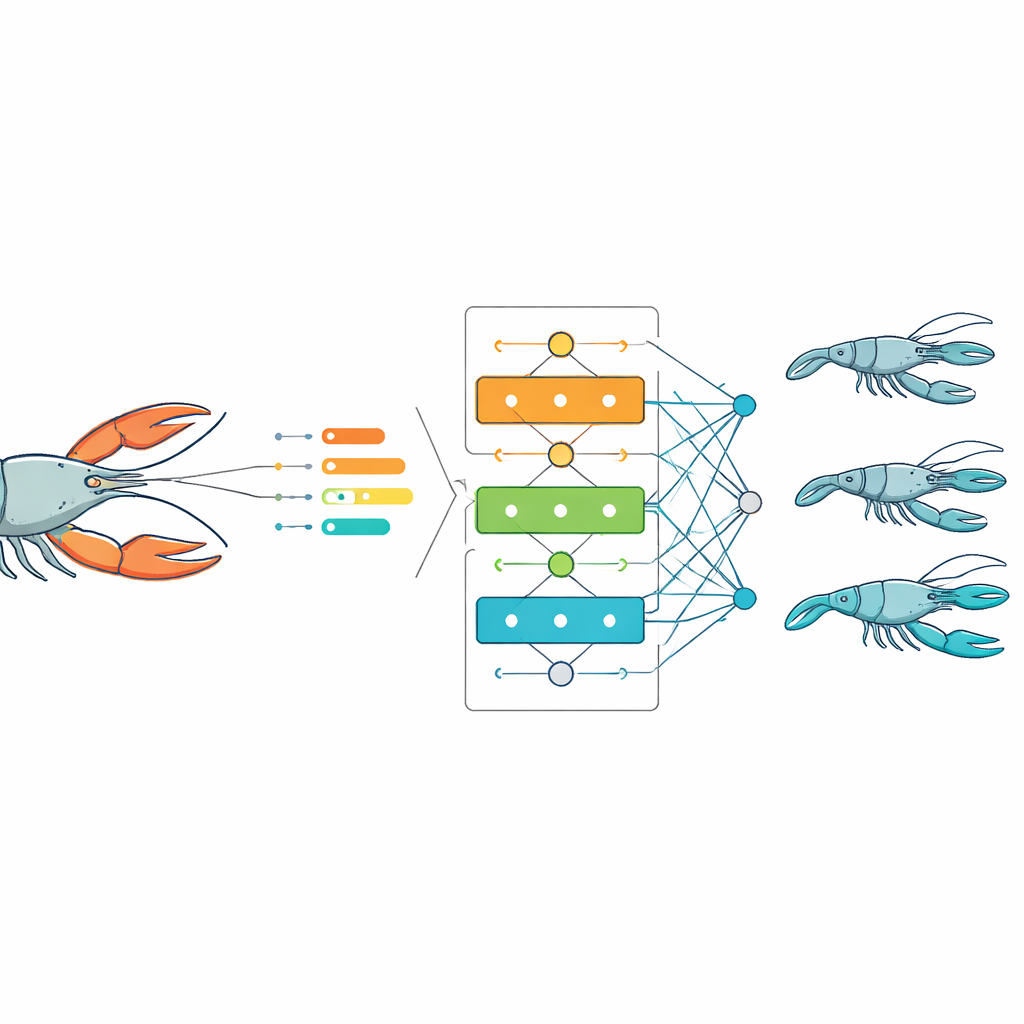
Låta algoritmer lära av fångsten
Med de viktigaste egenskaperna i handen tränade teamet flera vanliga prediktionsmetoder som faller under maskininlärningens paraply. Genom att använda 70 % av datan för att lära modellerna och 30 % för att testa dem jämförde de hur väl varje metod kunde uppskatta en enskild kräftas totalvikt utifrån dess kroppsmått. Över honor, hanar och hela populationen gav tre metoder — multipel linjär regression, random forest och särskilt gradient boosting — konsekvent mycket precisa förutsägelser, med fel som var små i förhållande till den naturliga variationen i datan. En annan vanligt använd metod, support vector regression, halkade efter eftersom den hade svårt att fånga de subtila, kurviga relationerna mellan storlek och vikt hos dessa djur.
Vad detta betyder för framtida fiskerier
För icke-specialister är huvudbudskapet att enkla kroppsmått på kräftor, i kombination med väl utvalda maskininlärningsverktyg, kan ge en snabb och tillförlitlig bild av hur mycket skörbart kött ett bestånd innehåller. Studien fann att kräftorna i reservoaren uppvisar en form av tillväxt där vikten ökar något snabbare än längden, och att gradient boosting-modeller, matade med noga utvalda egenskaper, kan förutsäga detta mönster med nästan perfekt noggrannhet. I praktiken innebär detta att förvaltare skulle kunna uppskatta beståndsstorlek och utforma fångstregler utan att behöva väga varje individ, vilket sparar tid och kostnader samtidigt som risken för överfiske minskar. När liknande metoder appliceras på andra arter kan datadrivna modeller som dessa bli en hörnsten i hållbar akvakultur och förvaltning av vilda bestånd.
Citering: Gültepe, Y., Gültepe, N. A sample model for applying feature selection and machine learning techniques to estimate and manage crayfish populations. Sci Rep 16, 14540 (2026). https://doi.org/10.1038/s41598-026-45535-9
Nyckelord: hållbara fiskerier, signalkräfta akvakultur, maskininlärning, beståndsbedömning, funktionsurval