Clear Sky Science · nl
Een voorbeeldmodel voor het toepassen van featureselectie en machine learning-technieken om rivierkreeftenpopulaties te schatten en te beheren
Waarom het tellen van rivierkreeften nu slimme hulpmiddelen nodig heeft
Naarmate de wereldwijde vraag naar zeevruchten groeit, staat het beheer onder druk om wilde bestanden gezond te houden en tegelijk voedsel te leveren. Rivierkreeften zijn een voedzame, vetarme delicatesse die met relatief bescheiden waterbehoefte gekweekt kan worden, maar ziekte, overbevissing en vervuiling maken hun aantallen moeilijker voorspelbaar. Deze studie laat zien hoe moderne datatechnieken, ontleend aan kunstmatige intelligentie, eenvoudige lichaamsmetingen van rivierkreeften kunnen omzetten in sterke aanwijzingen over hun groei, vleesopbrengst en populatiegrootte — wat helpt om visserijen zowel winstgevend als duurzaam te houden.
Rivierkreeften als toekomstige voedselbron
Rivierkreeften zitten vol eiwitten en essentiële mineralen en zijn tegelijkertijd laag in vet en calorieën, waardoor ze aantrekkelijk zijn op plaatsen waar dierlijke eiwitten schaars of duur zijn. Ze verdragen bovendien uiteenlopende omgevingscondities en kunnen worden gekweekt in vijvers, reservoirs of zelfs rijstvelden met relatief lage input. Tegelijkertijd zullen klimaatverandering en bevolkingsgroei de vraag naar voedsel de komende decennia waarschijnlijk sterk doen toenemen. Omdat rivierkreeftenbestanden al schommelingen laten zien door epidemieën, intensieve visserij en waterverontreiniging, is er een dringende behoefte aan betere instrumenten om hun status te volgen en oogsten te plannen zonder deze waardevolle bron uit te putten.
Veldmetingen omzetten in bruikbare data
De onderzoekers richtten zich op een grote rivierkreeftenpopulatie in het Atikhisar-reservoir in Turkije, waar ze gedetailleerde metingen verzamelden van 6.470 smalklauwrivierkreeften. Voor elk dier noteerden ze 20 kenmerken, waaronder totale lengte, breedtes en lengtes van belangrijke lichaamsdelen, en de gewichten van kop, abdomen en scharen, evenals het eetbare vlees. Deze metingen werden uitgevoerd met nauwkeurige schuifmaten en weegschalen en vervolgens opgeschoond door ontbrekende waarden in te vullen met een eenvoudige gemiddelde-methode. Het team paste ook klassieke lengte-gewichtformules uit de visserij toe om te onderzoeken hoe totale lengte samenhangt met totaalgewicht en om te verifiëren hoe de dieren in de loop van de tijd groeien.
De meest sprekende lichaamskenmerken vinden
Niet elke meting levert nuttige informatie op, en extra, zwak gerelateerde kenmerken kunnen computermodellen vertragen of verwarren. Om signaal van ruis te scheiden, gebruikten de auteurs een statistisch instrument dat beoordeelt hoe sterk elk kenmerk samen beweegt met het totaalgewicht. Ze behielden alleen die metingen die ten minste een matige samenhang lieten zien, zoals totale lengte, koplengte en -breedte, abdomenlengte en -breedte, en de verschillende deelgewichten en vleesgewichten. Deze stap verminderde het aantal invoervariabelen dat de modellen moesten overwegen sterk, terwijl bijna alle informatie behouden bleef die nodig is om te beschrijven hoe zwaar een rivierkreeft waarschijnlijk is.
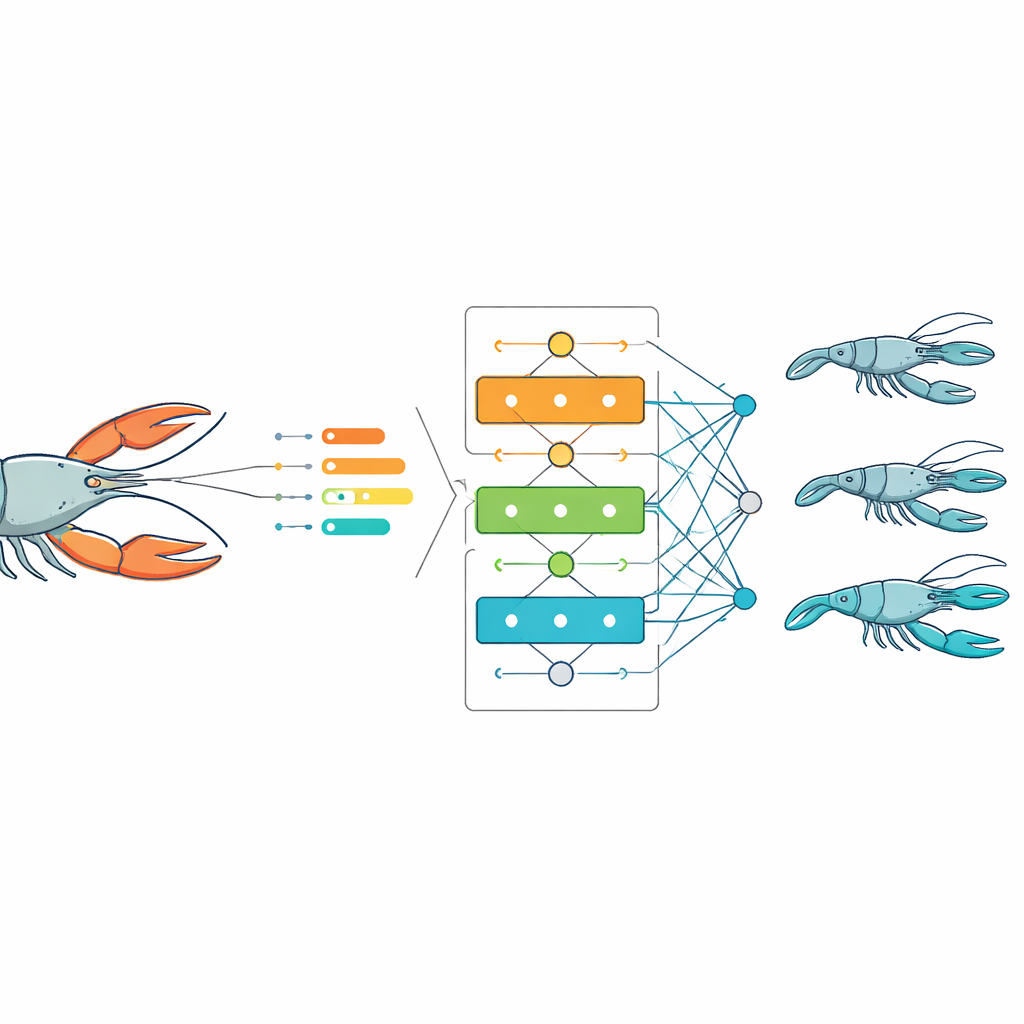
Algoritmen laten leren van de vangst
Met de belangrijkste kenmerken in handen trainde het team meerdere veelgebruikte voorspellingsmethoden die onder de paraplu van machine learning vallen. Met 70% van de data om de modellen te trainen en 30% om ze te testen, vergeleken ze hoe goed elk model het totale gewicht van een individuele rivierkreeft kon schatten op basis van lichaamsmetingen. Bij vrouwelijke, mannelijke en de gecombineerde populatie leverden drie methoden — meervoudige lineaire regressie, random forest en vooral gradient boosting — consequent zeer nauwkeurige voorspellingen op, met fouten die klein waren vergeleken met de natuurlijke variatie in de data. Een andere veelgebruikte methode, support vector regression, bleef achter omdat die moeite had de subtiele, gekromde relaties tussen grootte en gewicht in deze dieren vast te leggen.
Wat dit betekent voor toekomstige visserijen
Voor niet‑specialisten is de belangrijkste boodschap dat eenvoudige lichaamsmetingen van rivierkreeften, gecombineerd met zorgvuldig gekozen machine learning-hulpmiddelen, een snelle en betrouwbare inschatting kunnen geven van hoeveel bruikbaar vlees een populatie bevat. De studie vond dat rivierkreeften in het reservoir een groeivorm laten zien waarbij het gewicht iets sneller toeneemt dan de lengte, en dat gradient boosting-modellen, gevoed met zorgvuldig geselecteerde kenmerken, dit patroon met bijna perfecte nauwkeurigheid kunnen voorspellen. In de praktijk betekent dit dat beheerders de bestandsgrootte kunnen schatten en vangstregels kunnen opstellen zonder elk individu te hoeven wegen, waardoor tijd en kosten worden bespaard en het risico op overbevissing afneemt. Naarmate vergelijkbare methoden op andere soorten worden toegepast, kunnen datagestuurde modellen als deze een hoeksteen worden van duurzame aquacultuur en beheer van wilde bestanden.
Bronvermelding: Gültepe, Y., Gültepe, N. A sample model for applying feature selection and machine learning techniques to estimate and manage crayfish populations. Sci Rep 16, 14540 (2026). https://doi.org/10.1038/s41598-026-45535-9
Trefwoorden: duurzame visserij, rivierkreeftenkweek, machine learning, bestandbeoordeling, featureselectie