Clear Sky Science · en
A sample model for applying feature selection and machine learning techniques to estimate and manage crayfish populations
Why counting crayfish now needs smart tools
As the world’s appetite for seafood grows, managers are under pressure to keep wild stocks healthy while still putting food on the table. Crayfish are a nutritious, low‑fat delicacy that can be raised with relatively modest water needs, but disease, overfishing, and pollution have made their numbers harder to predict. This study shows how modern data techniques, borrowed from artificial intelligence, can turn simple body measurements of crayfish into powerful clues about their growth, meat yield, and population size—helping fisheries stay both profitable and sustainable.
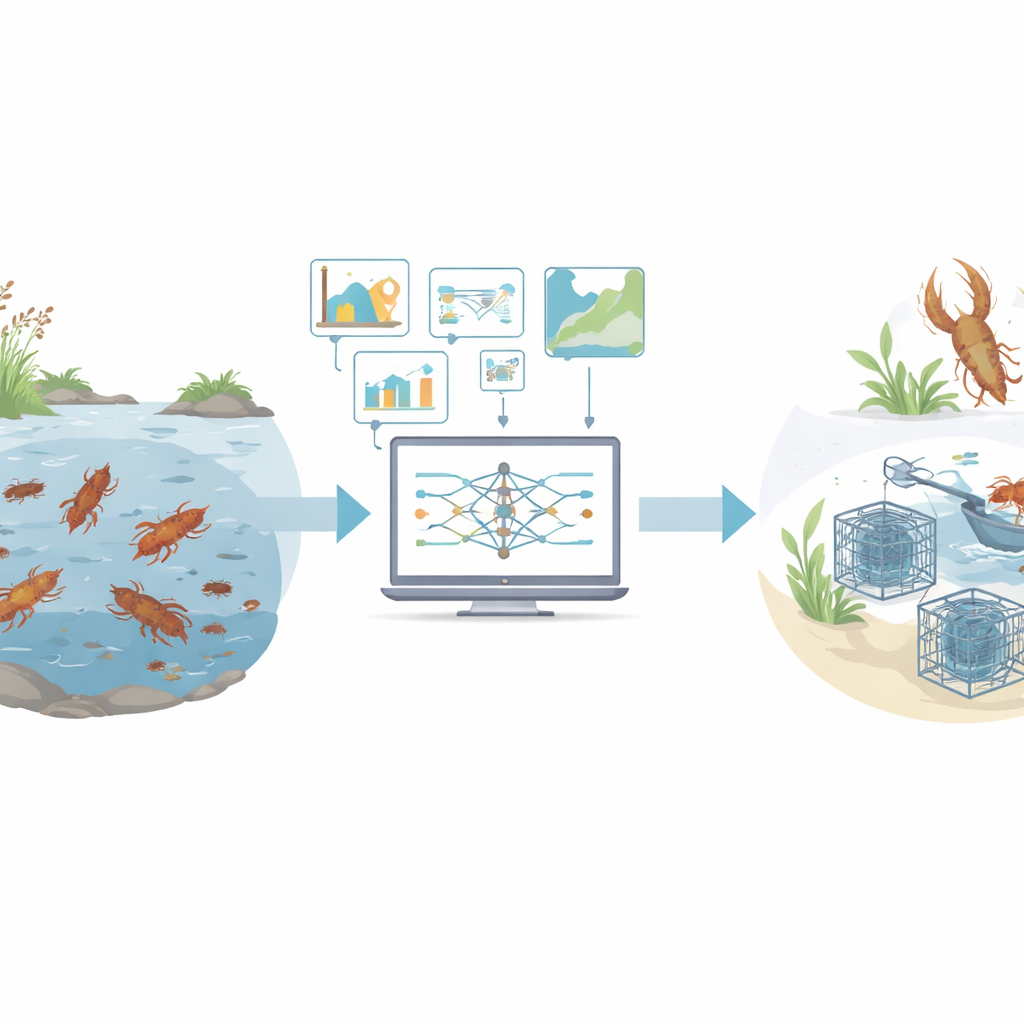
Crayfish as a future food source
Crayfish are rich in protein and essential minerals yet low in fat and calories, making them an attractive option where high‑quality animal protein is scarce or expensive. They also tolerate a range of environmental conditions and can be cultivated in ponds, reservoirs, or even rice fields with relatively low inputs. At the same time, global climate change and a rising human population are expected to push food demand sharply upward in the coming decades. Because crayfish stocks have already shown ups and downs due to epidemics, heavy fishing, and water pollution, there is an urgent need for better tools to track their status and plan harvests without depleting this valuable resource.
Turning field measurements into useful data
The researchers focused on a large crayfish population in Türkiye’s Atikhisar Reservoir, where they collected detailed measurements from 6,470 narrow‑clawed crayfish. For each animal they recorded 20 features, including overall length, widths and lengths of key body parts, and the weights of the head, abdomen, and claws, as well as the edible meat inside. These measurements were taken with precise calipers and scales, then cleaned using a simple averaging method to fill any missing values. The team also applied classic length‑weight formulas used in fisheries to see how total length relates to total weight and to verify how the animals grow over time.
Finding the most telling body features
Not every measurement adds useful information, and extra, weakly related features can slow down or confuse computer models. To sift signal from noise, the authors used a statistical tool that scores how strongly each feature moves with total weight. They kept only those measurements that showed at least a moderate link, such as total length, head length and width, abdomen length and width, and the various part and meat weights. This step sharply reduced the number of inputs the models had to consider, while preserving nearly all of the information needed to describe how heavy a crayfish is likely to be.
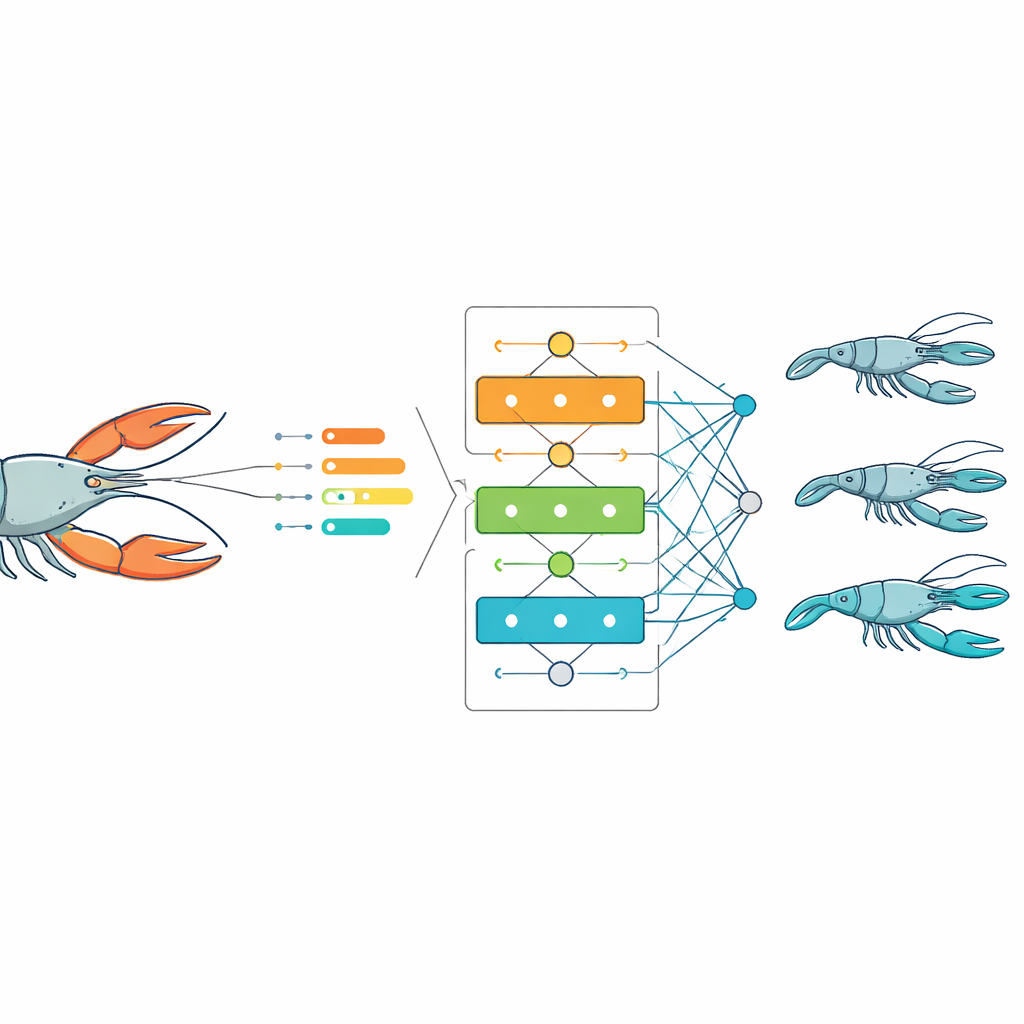
Letting algorithms learn from the catch
With the most important features in hand, the team trained several common prediction methods that fall under the umbrella of machine learning. Using 70% of the data to teach the models and 30% to test them, they compared how well each approach could estimate an individual crayfish’s total weight from its body measurements. Across females, males, and the combined population, three methods—multiple linear regression, random forest, and especially gradient boosting—consistently produced very accurate predictions, with errors small compared to the natural variation in the data. Another widely used method, support vector regression, lagged behind because it struggled to capture the subtle, curved relationships between size and weight in these animals.
What this means for future fisheries
For non‑specialists, the main message is that simple measurements of crayfish bodies, when paired with well‑chosen machine learning tools, can provide a fast and reliable picture of how much harvestable meat a population contains. The study found that crayfish in the reservoir show a form of growth where weight increases slightly faster than length, and that gradient boosting models, fed with carefully selected features, can predict this pattern with near‑perfect accuracy. In practice, this means managers could estimate stock size and design catch rules without having to weigh every individual, saving time and cost while reducing the risk of overfishing. As similar methods are applied to other species, data‑driven models like these may become a cornerstone of sustainable aquaculture and wild‑stock management.
Citation: Gültepe, Y., Gültepe, N. A sample model for applying feature selection and machine learning techniques to estimate and manage crayfish populations. Sci Rep 16, 14540 (2026). https://doi.org/10.1038/s41598-026-45535-9
Keywords: sustainable fisheries, crayfish aquaculture, machine learning, stock assessment, feature selection