Clear Sky Science · de
Ein Beispielmodell zur Anwendung von Merkmal‑Selektion und Machine‑Learning‑Techniken zur Schätzung und Bewirtschaftung von Flusskrebsbeständen
Warum das Zählen von Flusskrebsen heute schlanke Tools braucht
Während die weltweite Nachfrage nach Meeresfrüchten wächst, stehen Verantwortliche unter Druck, Wildbestände gesund zu erhalten und gleichzeitig für Nahrungssicherheit zu sorgen. Flusskrebse sind nahrhafte, fettarme Delikatessen, die mit vergleichsweise geringem Wasseraufwand gezüchtet werden können, doch Krankheit, Überfischung und Verschmutzung haben ihre Bestände schwerer vorhersehbar gemacht. Diese Studie zeigt, wie moderne Datentechniken aus der künstlichen Intelligenz einfache Körpermessungen von Flusskrebsen in starke Hinweise auf Wachstum, Fleischanteil und Populationsgröße verwandeln können – und damit Fischereien helfen, sowohl profitabel als auch nachhaltig zu bleiben.
Flusskrebse als künftige Nahrungsquelle
Flusskrebse sind reich an Protein und wichtigen Mineralstoffen, aber arm an Fett und Kalorien, was sie besonders attraktiv macht, wo hochwertiges tierisches Eiweiß knapp oder teuer ist. Sie tolerieren außerdem eine Bandbreite von Umweltbedingungen und können in Teichen, Stauseen oder sogar Reisfeldern mit relativ geringem Input gehalten werden. Zugleich werden der globale Klimawandel und die wachsende Weltbevölkerung in den kommenden Jahrzehnten voraussichtlich die Nachfrage nach Lebensmitteln deutlich erhöhen. Da Flusskrebsbestände bereits durch Epidemien, intensive Fischerei und Wasserverschmutzung Schwankungen gezeigt haben, besteht ein dringender Bedarf an besseren Werkzeugen, um ihren Zustand zu überwachen und Ernten zu planen, ohne diese wertvolle Ressource zu erschöpfen.
Feldmessungen in nützliche Daten verwandeln
Die Forschenden konzentrierten sich auf eine große Flusskrebspopulation im Atikhisar‑Stausee in der Türkei, wo sie detaillierte Messungen von 6.470 Schmalzangen‑Flusskrebsen sammelten. Für jedes Tier erfassten sie 20 Merkmale, darunter Gesamtlänge, Breiten und Längen wichtiger Körperteile sowie das Gewicht von Kopf, Abdomen und Scheren sowie das essbare Fleisch. Diese Messungen wurden mit präzisen Messschiebern und Waagen vorgenommen und anschließend mit einer einfachen Mittelwertmethode bereinigt, um fehlende Werte zu ersetzen. Das Team wandte auch klassische Längen‑Gewichts‑Formeln aus der Fischerei an, um zu untersuchen, wie die Gesamtlänge mit dem Gesamtgewicht zusammenhängt und um zu verifizieren, wie die Tiere über die Zeit wachsen.
Die aussagekräftigsten Körpermerkmale finden
Nicht jede Messung liefert nützliche Informationen, und zusätzliche, schwach verwandte Merkmale können Computer‑Modelle verlangsamen oder verwirren. Um Signal von Rauschen zu trennen, nutzten die Autorinnen und Autoren ein statistisches Werkzeug, das bewertet, wie stark jedes Merkmal mit dem Gesamtgewicht zusammenhängt. Es blieben nur jene Messgrößen erhalten, die mindestens eine moderate Verbindung zeigten, wie Gesamtlänge, Kopf‑Länge und ‑Breite, Abdomen‑Länge und ‑Breite sowie die Gewichte der einzelnen Teile und des Fleisches. Dieser Schritt reduzierte die Zahl der Eingangsgrößen für die Modelle deutlich, während nahezu alle Informationen erhalten blieben, die nötig sind, um das voraussichtliche Gewicht eines Flusskrebses zu beschreiben.
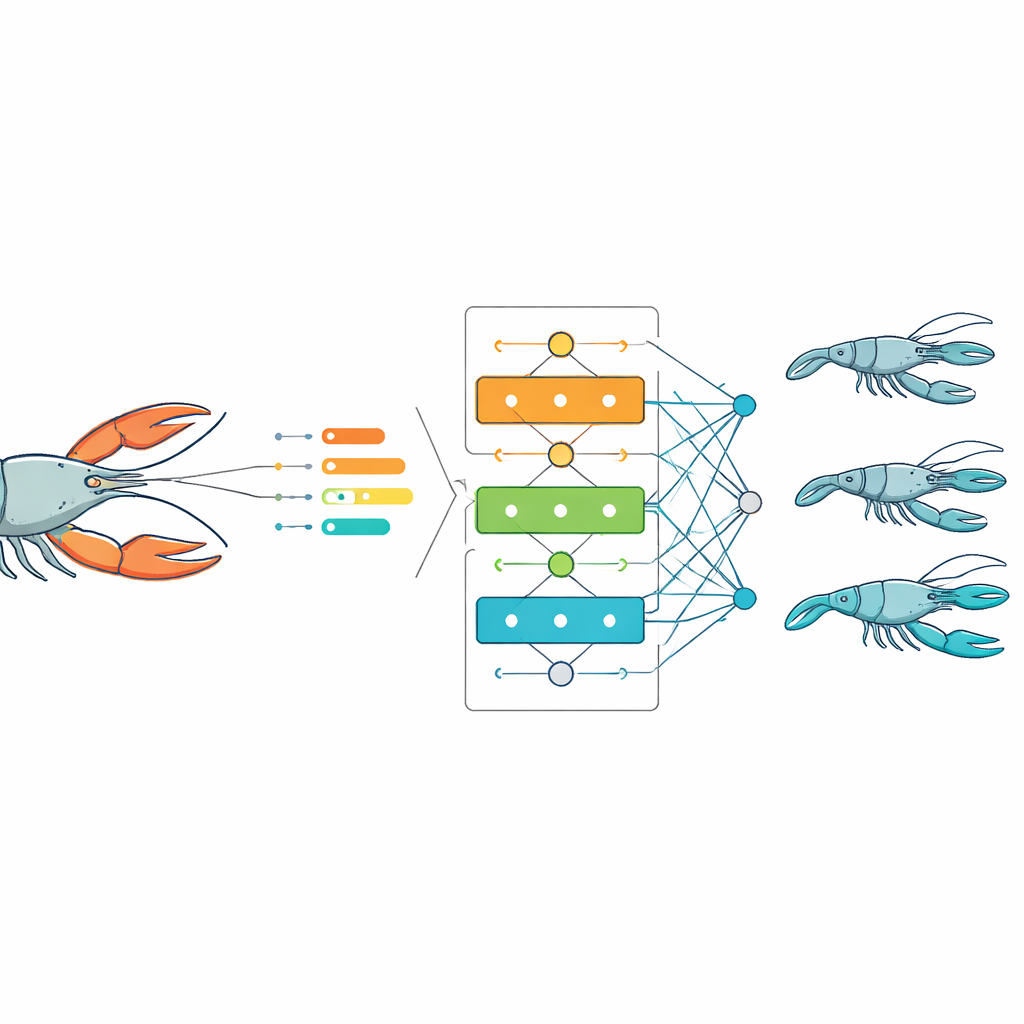
Algorithmen aus dem Fang lernen lassen
Mit den wichtigsten Merkmalen trainierte das Team mehrere gängige Vorhersagemethoden aus dem Bereich des maschinellen Lernens. Mit 70 % der Daten zum Training der Modelle und 30 % zum Testen verglichen sie, wie gut jede Methode das Gesamtgewicht eines einzelnen Flusskrebses aus seinen Körpermaßen schätzen konnte. Über Weibchen, Männchen und die kombinierte Population hinweg lieferten drei Methoden – multiple lineare Regression, Random Forest und besonders Gradient Boosting – durchweg sehr genaue Vorhersagen, mit Fehlern, die im Vergleich zur natürlichen Variabilität der Daten gering waren. Eine weitere weit verbreitete Methode, Support‑Vector‑Regression, lag zurück, da sie Schwierigkeiten hatte, die subtilen, gekrümmten Zusammenhänge zwischen Größe und Gewicht bei diesen Tieren abzubilden.
Was das für die zukünftige Fischerei bedeutet
Für Nicht‑Spezialisten ist die Kernbotschaft, dass einfache Körpermessungen von Flusskrebsen, kombiniert mit sorgfältig ausgewählten Methoden des maschinellen Lernens, ein schnelles und verlässliches Bild darüber liefern können, wieviel verwertbares Fleisch in einer Population enthalten ist. Die Studie ergab, dass Flusskrebse im Stausee eine Wachstumsform zeigen, bei der das Gewicht etwas schneller als die Länge zunimmt, und dass Gradient‑Boosting‑Modelle, gespeist mit gezielt ausgewählten Merkmalen, dieses Muster mit nahezu perfekter Genauigkeit vorhersagen können. Praktisch bedeutet das, dass Manager Bestandsgrößen schätzen und Fangregeln entwerfen könnten, ohne jedes Individuum wiegen zu müssen — was Zeit und Kosten spart und das Risiko der Überfischung verringert. Wenn ähnliche Methoden auf andere Arten angewendet werden, könnten datengetriebene Modelle wie diese zu einer Grundlage nachhaltiger Aquakultur und Wildbestandsbewirtschaftung werden.
Zitation: Gültepe, Y., Gültepe, N. A sample model for applying feature selection and machine learning techniques to estimate and manage crayfish populations. Sci Rep 16, 14540 (2026). https://doi.org/10.1038/s41598-026-45535-9
Schlüsselwörter: nachhaltige Fischerei, Flusskrebs‑Aquakultur, maschinelles Lernen, Bestandsbewertung, Merkmal‑Selektion