Clear Sky Science · sv
KGERA: knowledge graph enhanced reasoning architecture för rekommendationssystem
Varför smartare förslag spelar roll
Streamingtjänster och shoppingappar gissar ständigt vad du kan gilla härnäst. Ändå kan dessa gissningar, trots stora datamängder, upplevas som märkligt felaktiga: för generiska, för fokuserade på storsäljare eller blinda för den udda mix av saker du faktiskt uppskattar. Den här artikeln presenterar KGERA, en ny rekommendationsmetod som försöker tänka mer som en insiktsfull vän än en statistisk motor, genom att kombinera många slags bevis om objekt med ett explicitt, lättviktigt resonemangsskikt över ett nätverk av kunskap om filmer.
Från enkla mönster till rikare samband
De flesta befintliga rekommendationssystem förlitar sig tungt på kollaborativ filtrering: om personer som gillade samma filmer som du också gillade en annan titel, så rekommenderas den titeln för dig. Det fungerar bra när mycket data finns, men har svårt med nya eller nischade titlar och med användare som bara har få interaktioner. Andra metoder adderar innehållsinformation som genrer eller textbeskrivningar, eller använder grafneurala nätverk som behandlar användare och objekt som punkter i ett stort interaktionsnät. Ändå reducerar dessa system ofta allt till täta numeriska representationer, vilket gör det svårt att förstå varför ett förslag dök upp och långsamt att anpassa sig när katalogen eller dina preferenser förändras.
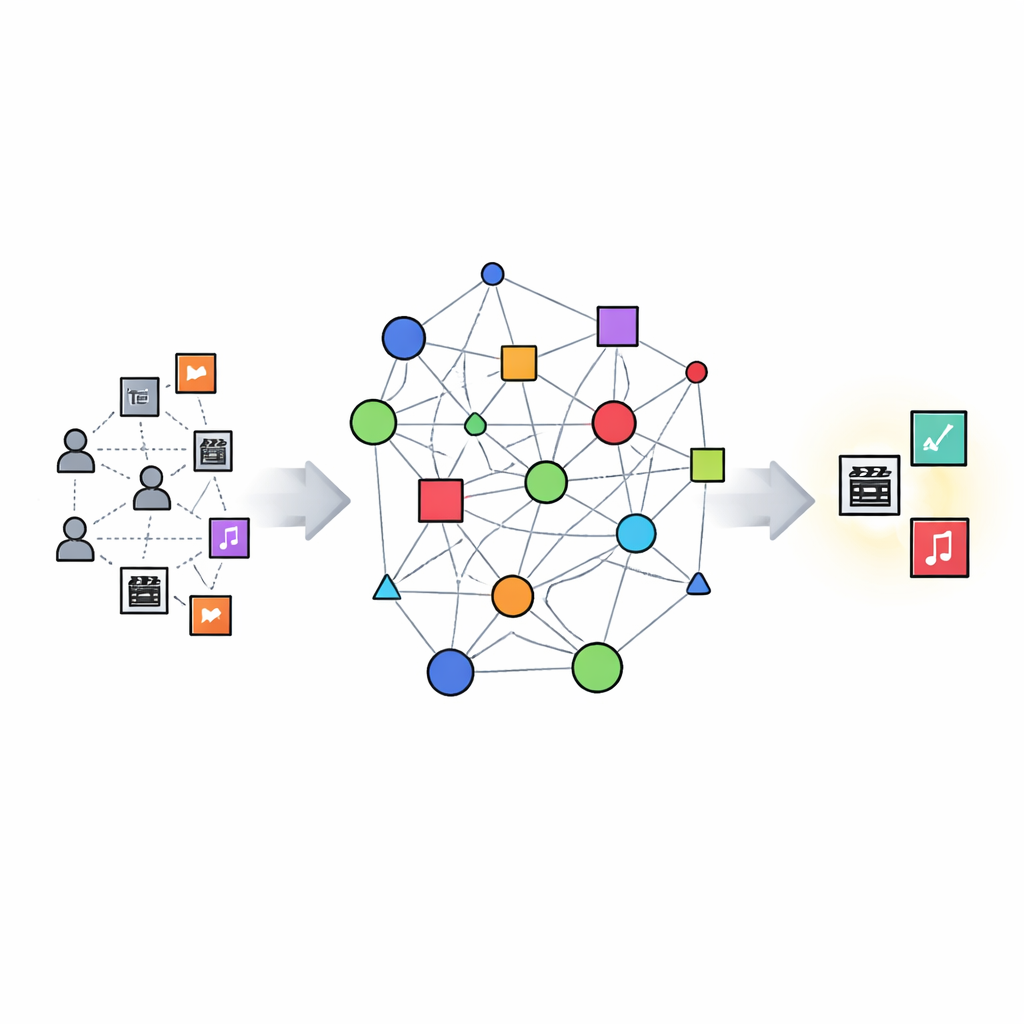
Bygga en karta över filmkunskap
KGERA börjar med att konstruera en kunskapsgraf: en strukturerad karta som länkar användare, filmer, genrer och skaparliknande enheter. I denna graf beskriver relationer vem som tittade på vad, vilka genrer en film tillhör, vilken pseudo-regissör den är kopplad till, och vilka filmer som är liknande, kompletterande eller utbytbara. Liknande filmer delar ofta både genre och skapare; kompletterande filmer kommer från olika genrer men känns nära tematiskt; utbytbara filmer finns i samma genre och är måttligt lika, så de kan fungera som alternativ utan att vara nära duplicat. Denna graf fångar inte bara samförekomster, utan de många sätt filmer kan relatera till varandra.
Ett resonemangsskikt som körs vid beslutstid
Ovanpå denna karta utformar författarna en resonansmodul som aktiveras när systemet behöver ge rekommendationer, i stället för under långa träningskörningar. För en given användare bygger den först en profil som sammanfattar vilka filmer personen redan har uppskattat. Den poängsätter sedan varje kandidatfilm genom flera genomskinliga linser: övergripande likhet med användarprofilen, överlapp i favoritenrer, konsekvens med skaparprefenser, tvärgenre men tematiskt nära „stretch“-alternativ, inom-genre-utbytbara som balanserar familjäritet och nyhet, samt en straffpoäng för objekt som är nästan kolkopior av vad användaren redan sett. Dessa komponenter kombineras till en enda poäng med enkla matematiska vikter, vilket gör logiken begriplig och lätt att justera när beteende eller kataloginnehåll utvecklas.
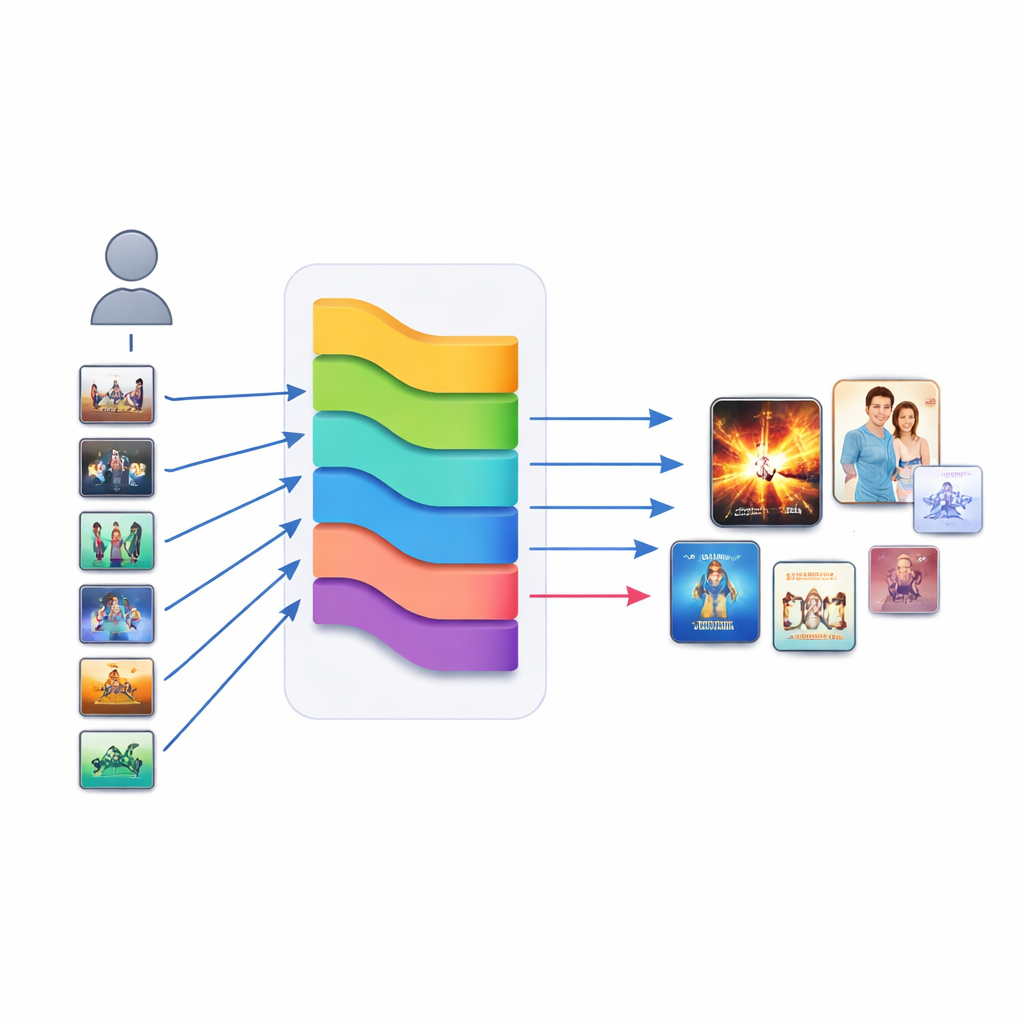
Blanda många röster till ett slutgiltigt val
I stället för att lita på en modell lyssnar KGERA på nio olika rekommendationsstrategier och låter sedan en liten meta-modell bestämma hur mycket förtroende varje strategi ska få. Förutom resonemangsmodulen ingår klassiska närhetsmetoder, grafbaserade rekommendatorer, självövervakade grafmodeller, ett neuralt kollaborativt filter, ett popularitetssignal, en kunskapsgraf-embeddingmodell och en innehållsbaserad textmodell. Alla deras poäng normaliseras och matas in i en enkel logistisk regression som lär sig en vikt för varje ingrediens. Intressant nog framträder item-till-item-närheter och textinnehåll som de starkaste positiva bidragsgivarna, medan popularitet och vissa graf-signaler får negativa vikter och fungerar som avsiktliga debiasers som bromsar tendensen att överexponera storsäljare på bekostnad av mindre kända men relevanta titlar.
Robusta vinster över användare, objekt och genrer
Författarna testar KGERA på den välkända MovieLens-1M-datamängden och jämför den med starka moderna baslinjer, inklusive nyare självövervakade grafmetoder. Över flera rankningsmått och olika listlängder ligger KGERA konsekvent före, ofta med mer än 50 procent relativ förbättring i hur väl den placerar den verkligt relevanta filmen högt i listan. Vinsterna är särskilt stora för användare med få tidigare interaktioner och för filmer med medelpopuläritet, två områden där nuvarande system ofta har problem. Detaljerade ablationsstudier, korsvalidering och känslighetskontroller visar att förbättringarna är stabila och inte knutna till ett specifikt hyperparameterval eller datasplit, även om vissa genrer som drama förblir utmanande.
Vad detta betyder för vardagliga rekommendationer
För icke-specialister är kärnbudskapet att rekommendationer kan bli både smartare och mer begripliga genom att resonera över en explicit karta av relationer mellan objekt, i stället för att dölja allt i en stor svart låda. KGERA visar att ett snabbt resonemangsskikt vid testtid, kombinerat med en noggrant kalibrerad blandning av gamla och nya tekniker, kan leverera märkbart bättre förslag utan att ta till långsamma, dyra språkmodeller. I praktiken kan detta översättas till streaming- och shoppinggränssnitt som lyfter fram mer relevanta, varierade och oväntade alternativ, särskilt för nya användare och mindre kända titlar, samtidigt som det är effektivt nog att köras i realtid.
Citering: Muniraja, P., Satapathy, S.M. KGERA: knowledge graph enhanced reasoning architecture for recommendation systems. Sci Rep 16, 13994 (2026). https://doi.org/10.1038/s41598-026-42865-6
Nyckelord: rekommendationssystem, kunskapsgrafer, grafresonemang, ensembleinlärning, filmtips