Clear Sky Science · fr
KGERA : architecture de raisonnement enrichie par un graphe de connaissances pour les systèmes de recommandation
Pourquoi des suggestions plus intelligentes comptent
Les plateformes de streaming et les applications d’achat tentent en permanence de deviner ce qui pourrait vous plaire ensuite. Pourtant, malgré des montagnes de données, ces prédictions peuvent sembler étrangement hors sujet : trop génériques, trop centrées sur les succès commerciaux, ou incapables de saisir le mélange particulier de choses que vous appréciez réellement. Cet article présente KGERA, une nouvelle approche de recommandation qui cherche à raisonner davantage comme un ami avisé que comme un moteur statistique, en combinant de nombreux types d’indices sur les éléments avec un processus de raisonnement explicite et léger au sein d’un réseau de connaissances sur les films.
Des motifs simples à des connexions plus riches
La plupart des systèmes de recommandation existants s’appuient fortement sur le filtrage collaboratif : si des personnes qui ont aimé les mêmes films que vous ont aussi aimé un autre titre, ce titre vous est proposé. Cela fonctionne bien quand il y a abondance de données, mais peine avec les nouveautés ou les objets de niche et avec les utilisateurs qui ont peu d’interactions. D’autres méthodes ajoutent des informations de contenu comme les genres ou les descriptions textuelles, ou utilisent des réseaux de neurones de graphes qui traitent utilisateurs et éléments comme des nœuds d’un vaste réseau d’interactions. Pourtant, ces systèmes réduisent souvent tout à des représentations numériques denses, ce qui rend difficile de comprendre pourquoi une suggestion est apparue et lent à s’adapter lorsque le catalogue ou vos goûts évoluent.
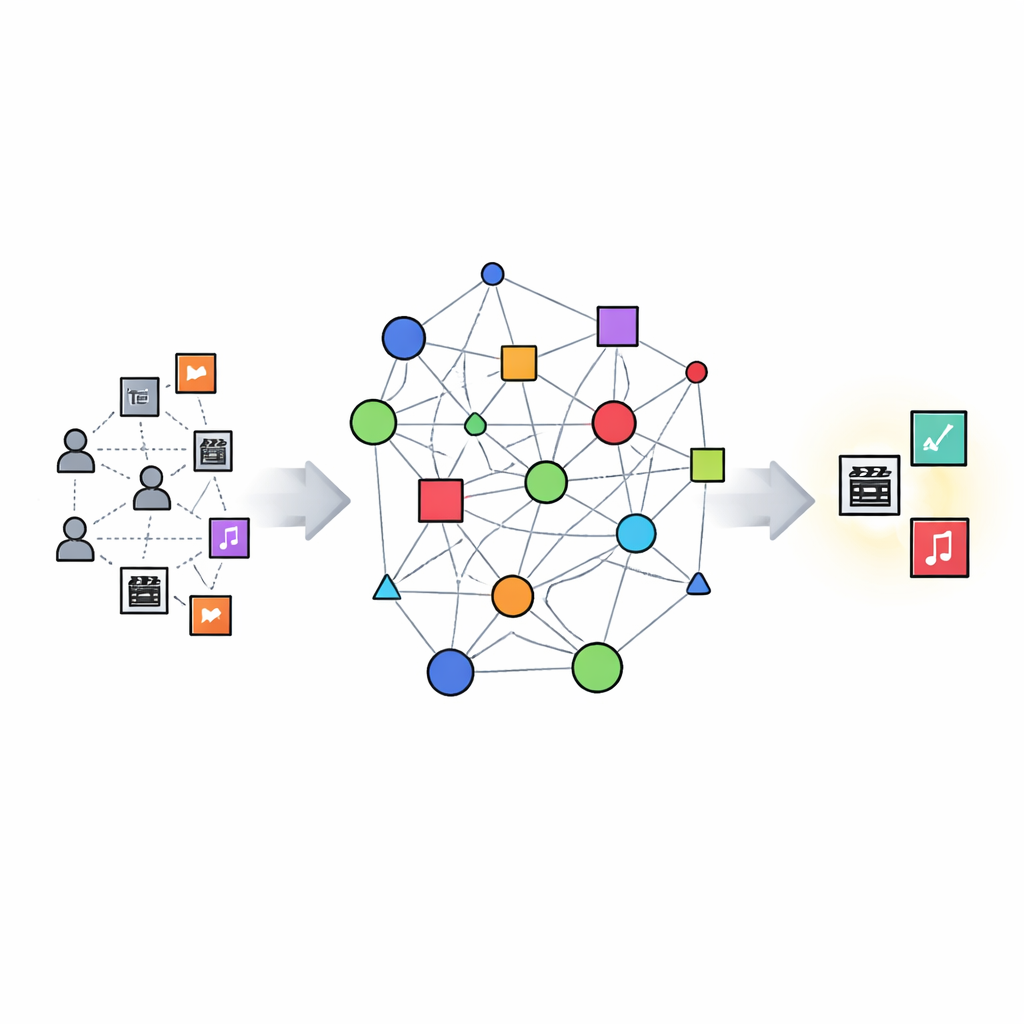
Construire une carte des connaissances cinématographiques
KGERA commence par construire un graphe de connaissances : une carte structurée qui relie utilisateurs, films, genres et entités proches des créateurs. Dans ce graphe, les relations décrivent qui a regardé quoi, à quels genres appartient un film, quel pseudo-réalisateur lui est associé, et quels films sont similaires, complémentaires ou substituables. Les films similaires partagent souvent à la fois le genre et le créateur ; les films complémentaires proviennent de genres différents mais sont proches thématiquement ; les films substituables évoluent dans le même genre et se ressemblent modérément, de sorte qu’ils peuvent servir d’alternatives sans être des quasi-duplications. Ce graphe capture non seulement les co-occurrences, mais aussi les nombreuses façons dont les films peuvent être reliés.
Une couche de raisonnement qui intervient au moment de la décision
Par-dessus cette carte, les auteurs conçoivent un module de raisonnement qui s’active lorsque le système doit générer des recommandations, plutôt que pendant de longues phases d’entraînement. Pour un utilisateur donné, il construit d’abord un profil résumant les films qu’il a déjà appréciés. Il évalue ensuite chaque film candidate selon plusieurs lentilles transparentes : similarité globale avec le profil utilisateur, recoupement des genres favoris, cohérence avec les préférences de créateurs, options « étirées » traversant les genres mais proches thématiquement, substituts au sein du même genre qui équilibrent familiarité et nouveauté, et une pénalité pour les éléments qui sont quasiment des copies conformes de ce que l’utilisateur a déjà vu. Ces composantes sont combinées en un score unique à l’aide de poids mathématiques simples, rendant la logique compréhensible et facile à ajuster à mesure que le comportement ou le contenu du catalogue évoluent.
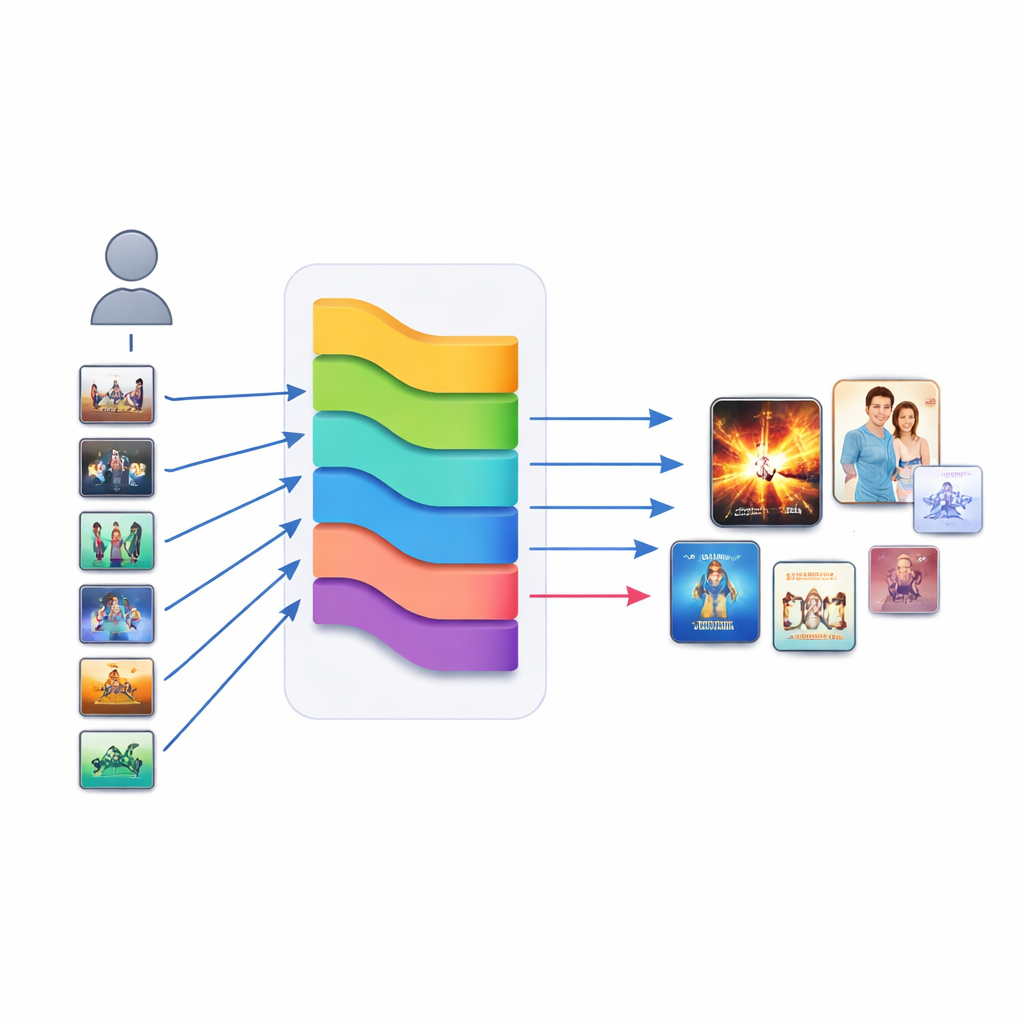
Fusionner de nombreuses voix en un choix final
Plutôt que de s’en remettre à un seul modèle, KGERA écoute neuf stratégies de recommandation différentes puis laisse un petit méta-modèle décider combien faire confiance à chacune. Outre le module de raisonnement, il inclut des méthodes de voisinage classiques, des recommandations basées sur les graphes, des modèles auto-supervisés sur graphes, un filtre collaboratif neuronal, un signal de popularité, un modèle d’embedding de graphe de connaissances et un modèle de contenu textuel. Tous leurs scores sont normalisés et alimentés dans une régression logistique simple qui apprend un poids pour chaque ingrédient. Fait intéressant, les voisinages item-à-item et le contenu textuel apparaissent comme les contributeurs positifs les plus forts, tandis que la popularité et certains signaux de graphe obtiennent des poids négatifs et agissent comme des dé-biasers délibérés, contrant la tendance à sur-promouvoir les succès au détriment de titres moins connus mais pertinents.
Gains robustes pour les utilisateurs, les films et les genres
Les auteurs testent KGERA sur le célèbre jeu de données MovieLens-1M et le comparent à de solides baselines modernes, y compris des méthodes récentes auto-supervisées sur graphes. Sur plusieurs métriques de classement et différentes longueurs de liste, KGERA arrive systématiquement en tête, souvent avec plus de 50 % d’amélioration relative dans la capacité à positionner le film réellement pertinent en haut de la liste. Les gains sont particulièrement importants pour les utilisateurs avec peu d’interactions passées et pour les films de popularité moyenne, deux domaines où les systèmes actuels peinent souvent. Des études d’ablation détaillées, une validation croisée et des tests de sensibilité montrent que les améliorations sont stables et ne dépendent pas d’un choix d’hyperparamètres ou d’une découpe de données particulière, même si certains genres comme le drame restent difficiles.
Ce que cela signifie pour les recommandations de tous les jours
Pour un public non spécialisé, le message central est que les recommandations peuvent être à la fois plus intelligentes et plus compréhensibles en raisonnant sur une carte explicite des relations entre éléments, au lieu de tout dissimuler dans un grand modèle boîte noire. KGERA montre qu’une couche de raisonnement rapide au moment du test, combinée à un mélange finement calibré de techniques anciennes et nouvelles, peut fournir des suggestions sensiblement meilleures sans recourir à des modèles de langage lents et coûteux. En pratique, cela pourrait se traduire par des interfaces de streaming et d’achat qui mettent en avant des options plus pertinentes, diverses et surprenantes, en particulier pour les nouveaux utilisateurs et les articles moins connus, tout en restant suffisamment efficaces pour fonctionner en temps réel.
Citation: Muniraja, P., Satapathy, S.M. KGERA: knowledge graph enhanced reasoning architecture for recommendation systems. Sci Rep 16, 13994 (2026). https://doi.org/10.1038/s41598-026-42865-6
Mots-clés: systèmes de recommandation, graphes de connaissances, raisonnement sur graphes, apprentissage par ensemble, recommandation de films