Clear Sky Science · it
KGERA: architettura di ragionamento potenziata da knowledge graph per sistemi di raccomandazione
Perché le proposte più intelligenti sono importanti
I siti di streaming e le app di shopping provano continuamente a indovinare cosa potrebbe piacerti dopo. Eppure, anche con montagne di dati, quei suggerimenti possono risultare stranamente fuori strada: troppo generici, troppo concentrati sui grandi successi, o ciechi rispetto al mix di gusti particolari che davvero apprezzi. Questo articolo presenta KGERA, un nuovo approccio alle raccomandazioni che cerca di ragionare più come un amico esperto che come un motore statistico, combinando diversi tipi di evidenza sugli oggetti con un processo di ragionamento esplicito e leggero su una rete di conoscenza sui film.
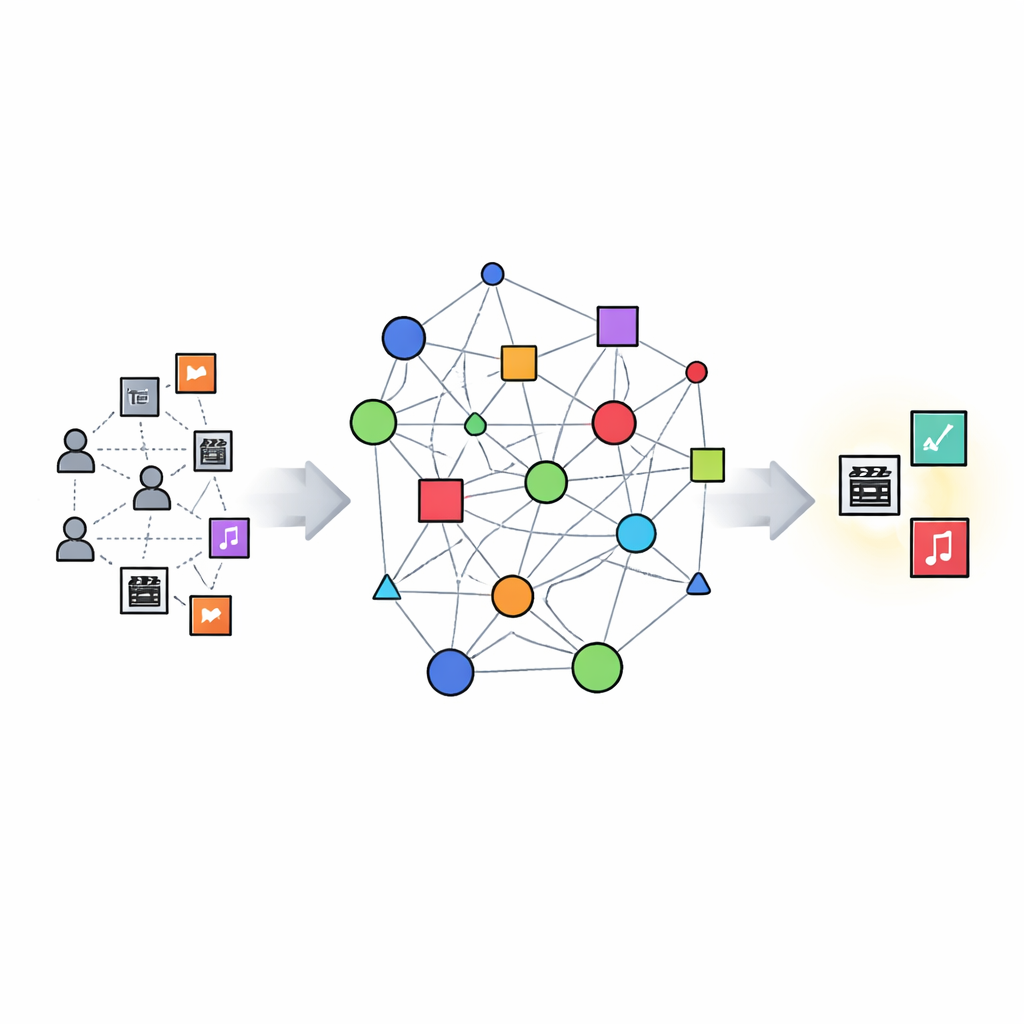
Dai pattern semplici a connessioni più ricche
La maggior parte dei sistemi di raccomandazione esistenti si basa molto sul collaborative filtering: se persone che hanno apprezzato gli stessi film che hai visto anche hanno gradito un altro titolo, quel titolo ti viene proposto. Questo funziona bene quando ci sono molti dati, ma fatica con elementi nuovi o di nicchia e con utenti che hanno poche interazioni. Altri metodi integrano informazioni di contenuto come generi o descrizioni testuali, oppure usano graph neural network che trattano utenti e oggetti come nodi in una grande rete di interazioni. Tuttavia, questi sistemi spesso comprimono tutto in rappresentazioni numeriche dense, rendendo difficile capire perché un suggerimento è apparso e lento adattarsi quando il catalogo o i tuoi gusti cambiano.
Costruire una mappa della conoscenza sui film
KGERA inizia costruendo un knowledge graph: una mappa strutturata che collega utenti, film, generi ed entità simili a creatori. In questo grafo, le relazioni descrivono chi ha visto cosa, a quali generi appartiene un film, a quale pseudo-regista è legato e quali film sono simili, complementari o intercambiabili. I film simili tendono a condividere sia genere che creatore; i film complementari provengono da generi diversi ma risultano vicini per tema; i film sostitutivi vivono nello stesso genere e sono moderatamente simili, quindi possono fungere da alternative senza essere quasi duplicati. Questo grafo cattura non solo la co-occorrenza, ma i molteplici modi in cui i film possono essere correlati.
Un livello di ragionamento che opera al momento della decisione
Sopra questa mappa, gli autori progettano un modulo di ragionamento che si attiva quando il sistema deve generare raccomandazioni, anziché durante lunghe fasi di addestramento. Per un dato utente costruisce prima un profilo che riassume i film che ha già apprezzato. Poi valuta ogni film candidato attraverso diverse lenti trasparenti: similarità complessiva con il profilo utente, sovrapposizione nei generi preferiti, coerenza con le preferenze verso i creatori, opzioni “stretch” cross-genere ma tematicamente vicine, sostituti all’interno del genere che bilanciano familiarità e novità, e una penalità per elementi che sono quasi copie carbone di ciò che l’utente ha già visto. Questi componenti vengono combinati in un unico punteggio usando pesi matematici semplici, rendendo la logica comprensibile e facile da aggiustare man mano che il comportamento o il contenuto del catalogo evolvono.
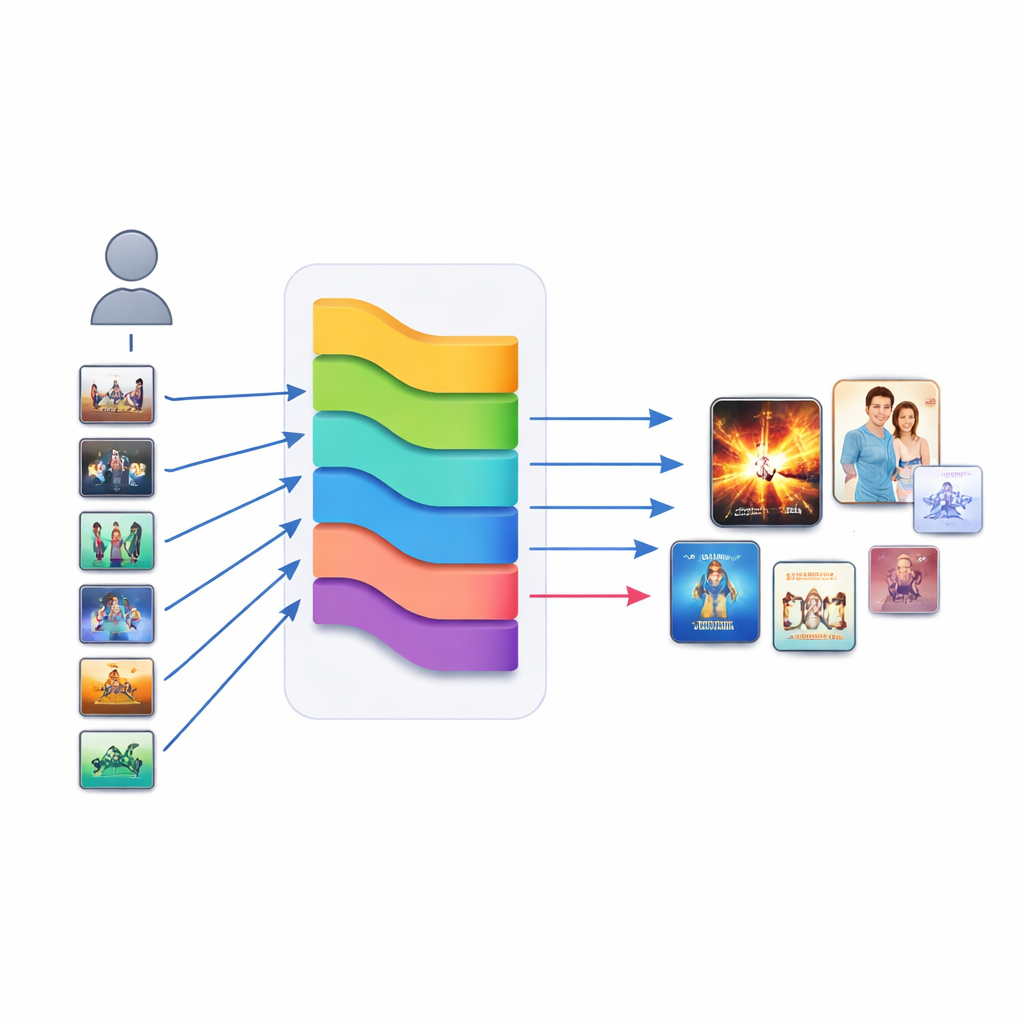
Fondere molte voci in una scelta finale
Invece di affidarsi a un singolo modello, KGERA ascolta nove diverse strategie di raccomandazione e lascia poi a un piccolo meta-modello il compito di decidere quanto fidarsi di ciascuna. Oltre al modulo di ragionamento, include metodi classici basati sul vicinato, raccomandatori basati su grafi, modelli grafici self-supervised, un filtro collaborativo neurale, un segnale di popolarità, un modello di embedding del knowledge graph e un modello testuale basato sul contenuto. Tutti i loro punteggi vengono normalizzati e alimentati in una semplice regressione logistica che impara un peso per ogni ingrediente. Interessante notare che i vicinati item-to-item e il contenuto testuale emergono come i contributori positivi più forti, mentre la popolarità e alcuni segnali di grafo ottengono pesi negativi e fungono da correttori deliberati, contrastando la tendenza a sovra-promuovere i successi a scapito di titoli meno noti ma rilevanti.
Vantaggi robusti su utenti, elementi e generi
Gli autori testano KGERA sul noto dataset MovieLens-1M e lo confrontano con solidi baseline moderni, inclusi recenti metodi grafici self-supervised. Su molteplici metriche di ranking e diverse lunghezze di lista, KGERA risulta costantemente in vantaggio, spesso con miglioramenti relativi superiori al 50 percento nel posizionare il film veramente rilevante nelle prime posizioni della lista. I guadagni sono particolarmente ampi per utenti con poche interazioni passate e per film di popolarità media, due aree in cui i sistemi attuali spesso faticano. Studi di ablazione dettagliati, cross-validation e controlli di sensitività mostrano che i miglioramenti sono stabili e non legati a una particolare scelta di iperparametri o alla suddivisione dei dati, sebbene alcuni generi come il dramma restino impegnativi.
Cosa significa per le raccomandazioni di tutti i giorni
Per i non addetti ai lavori, il messaggio principale è che le raccomandazioni possono essere sia più intelligenti che più comprensibili ragionando su una mappa esplicita di relazioni tra elementi, invece di nascondere tutto dentro un grande modello scatola nera. KGERA dimostra che un livello di ragionamento veloce attivato al test-time, combinato con una miscela calibrata di tecniche vecchie e nuove, può offrire suggerimenti nettamente migliori senza ricorrere a modelli linguistici lenti e costosi. In pratica, questo potrebbe tradursi in interfacce di streaming e shopping che mostrano opzioni più rilevanti, varie e serendipitose, particolarmente per utenti nuovi e per elementi meno famosi, rimanendo comunque efficienti abbastanza da operare in tempo reale.
Citazione: Muniraja, P., Satapathy, S.M. KGERA: knowledge graph enhanced reasoning architecture for recommendation systems. Sci Rep 16, 13994 (2026). https://doi.org/10.1038/s41598-026-42865-6
Parole chiave: sistemi di raccomandazione, knowledge graph, ragionamento su grafi, apprendimento ensemble, raccomandazione di film