Clear Sky Science · en
KGERA: knowledge graph enhanced reasoning architecture for recommendation systems
Why smarter suggestions matter
Streaming sites and shopping apps constantly guess what you might like next. Yet even with mountains of data, those guesses can feel oddly off: too generic, too focused on blockbusters, or blind to the quirky mix of things you actually enjoy. This paper introduces KGERA, a new recommendation approach that tries to think more like a savvy friend than a statistics engine, by combining many kinds of evidence about items with an explicit, lightweight reasoning process over a network of knowledge about movies.
From simple patterns to richer connections
Most existing recommenders lean heavily on collaborative filtering: if people who liked the same films as you also liked some other title, that title gets pushed to you. This works well when there is plenty of data, but it struggles with new or niche items and with users who have only a few interactions. Other methods add content information such as genres or text descriptions, or use graph neural networks that treat users and items as points in a big interaction web. Still, these systems often reduce everything to dense numerical representations, making it hard to see why a suggestion appeared and slow to adapt when the catalog or your tastes shift.
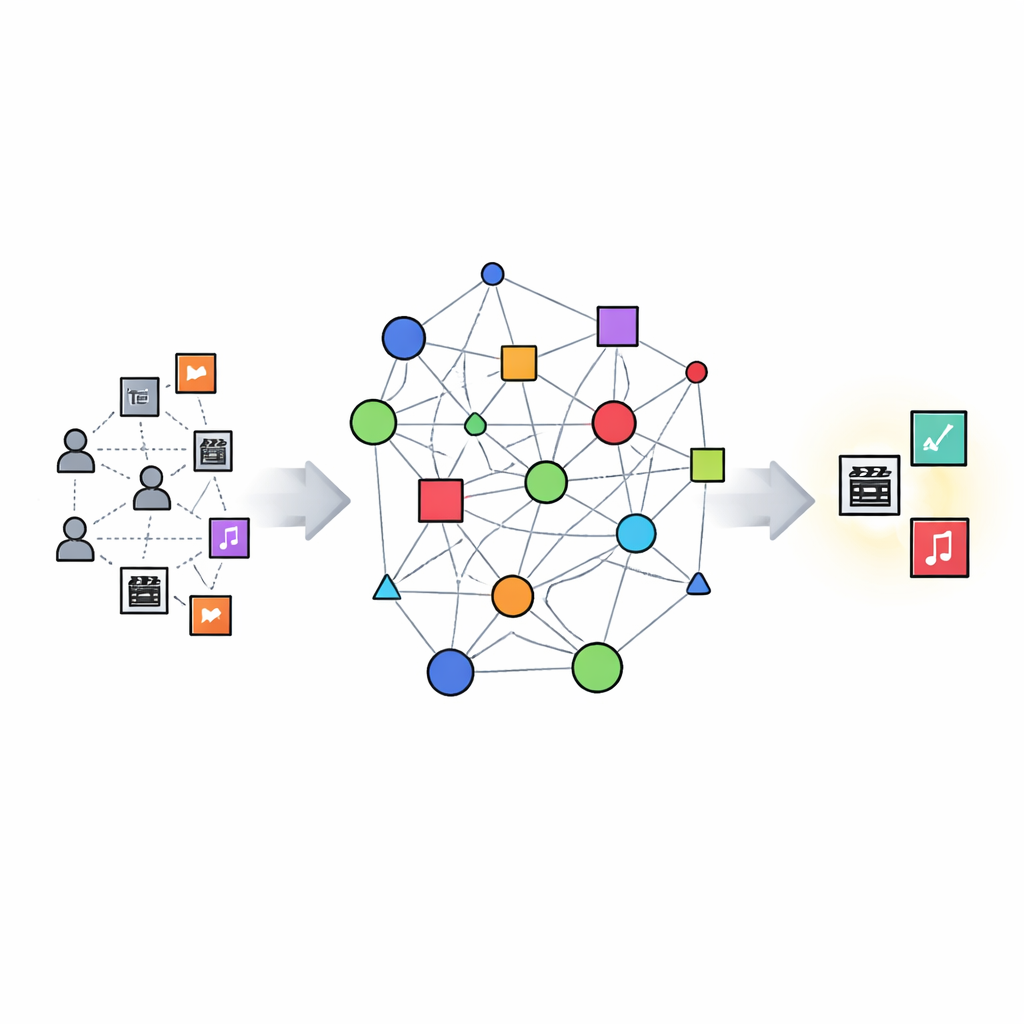
Building a map of movie knowledge
KGERA starts by constructing a knowledge graph: a structured map that links users, movies, genres, and creator-like entities. In this graph, relations describe who watched what, which genres a movie belongs to, which pseudo-director it is tied to, and which movies are similar, complementary, or interchangeable. Similar films tend to share both genre and creator; complementary films come from different genres but feel close in theme; substitutable films live in the same genre and are moderately alike, so they can serve as alternatives without being near duplicates. This graph captures not just co-occurrence, but the many ways movies can be related.
A reasoning layer that works at decision time
On top of this map, the authors design a reasoning module that activates when the system needs to make recommendations, rather than during long training runs. For a given user, it first builds a profile summarizing the movies they have already enjoyed. It then scores each candidate movie through several transparent lenses: overall similarity to the user profile, overlap in favorite genres, consistency with creator preferences, cross-genre but thematically close "stretch" options, within-genre substitutes that balance familiarity and novelty, and a penalty for items that are almost carbon copies of what the user has already seen. These components are combined into a single score using simple mathematical weights, making the logic understandable and easy to adjust as behavior or catalog content evolves.
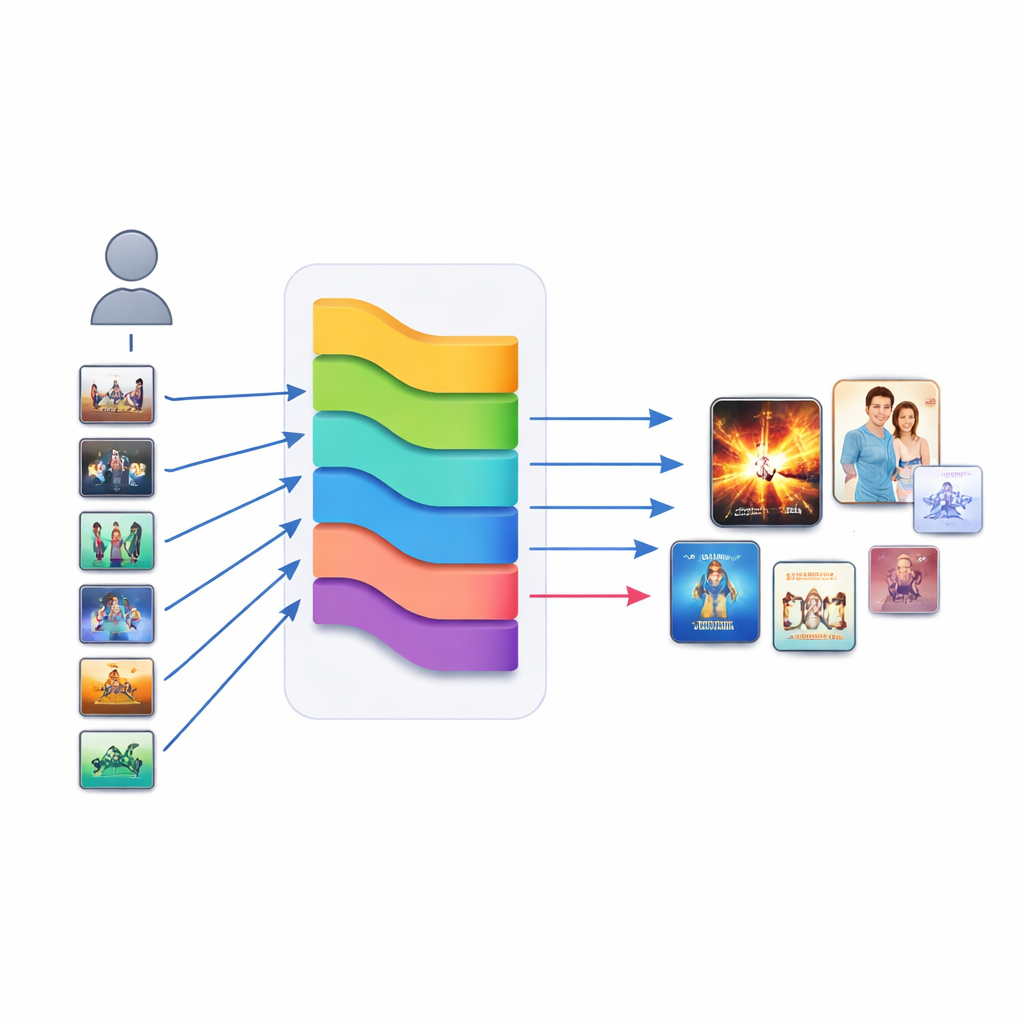
Blending many voices into one final choice
Instead of relying on one model, KGERA listens to nine different recommendation strategies and then lets a small meta-model decide how much to trust each one. Alongside the reasoning module, it includes classic neighborhood methods, graph-based recommenders, self-supervised graph models, a neural collaborative filter, a popularity signal, a knowledge-graph embedding model, and a content-based text model. All of their scores are normalized and fed into a simple logistic regression that learns a weight for each ingredient. Interestingly, item-to-item neighborhoods and text content emerge as the strongest positive contributors, while popularity and some graph signals get negative weights and act as deliberate debiasers, pushing back against the tendency to over-promote hits at the expense of lesser-known but relevant titles.
Robust gains across users, items, and genres
The authors test KGERA on the well-known MovieLens-1M dataset and compare it with strong modern baselines, including recent self-supervised graph methods. Across multiple ranking metrics and different list lengths, KGERA consistently comes out ahead, often by more than 50 percent relative improvement in how well it positions the truly relevant movie near the top of the list. The gains are especially large for users with few past interactions and for mid-popularity films, two areas where current systems often struggle. Detailed ablation studies, cross-validation, and sensitivity checks show that the improvements are stable and not tied to a particular hyperparameter choice or data split, though some genres such as drama remain challenging.
What this means for everyday recommendations
For non-specialists, the core message is that recommendations can be made both smarter and more understandable by reasoning over an explicit map of relationships among items, instead of hiding everything inside a large black-box model. KGERA shows that a fast, test-time reasoning layer, combined with a carefully calibrated blend of old and new techniques, can deliver noticeably better suggestions without resorting to slow, expensive language models. In practice, this could translate into streaming and shopping interfaces that surface more relevant, diverse, and serendipitous options, particularly for new users and less famous items, while still being efficient enough to run in real time.
Citation: Muniraja, P., Satapathy, S.M. KGERA: knowledge graph enhanced reasoning architecture for recommendation systems. Sci Rep 16, 13994 (2026). https://doi.org/10.1038/s41598-026-42865-6
Keywords: recommender systems, knowledge graphs, graph reasoning, ensemble learning, movie recommendation