Clear Sky Science · sv
IntelliScheduler: ett hybriddjupinlärningsramverk för kant‑och‑moln‑beräkning för uppgiftsschemaläggning baserat på lärande
Varför väntan på molnet fortfarande spelar roll
Varje gång en smart kamera markerar en obekant person vid din dörr, eller en uppkopplad bil reagerar på trafik, skickas korta jobb — ”uppgifter” — för bearbetning någonstans på internet. Om dessa jobb alltid skickas hela vägen till avlägsna datacenter kan rundresan bli för långsam för tidskritiska åtgärder. Den här artikeln presenterar IntelliScheduler, ett lärandebaserat system som i realtid avgör vilka uppgifter som bör hanteras nära användaren i nätverkets kant och vilka som tryggt kan skickas till molnet, med målet att hålla svarstiderna snabba samtidigt som kostnaderna hålls nere.
Från fjärrservrar till närliggande hjälpare
Traditionell molndatabehandling har varit en arbetsnöt för onlinetjänster eftersom den billigt kan skala till miljontals användare. Men för många moderna Internet of Things (IoT)-tillämpningar — som fabriksensorer, smarta fordon eller bärbar hälsoteknik — kan varje extra millisekund fördröjning vara betydelsefull. För att minska den fördröjningen placerar företag nu mindre servrar nära användarna, så kallade kantservrar. Dessa kantmaskiner kan svara snabbare men har begränsad kapacitet. Om för många uppgifter skjuts till kanten fastnar de i kö; om för många skickas till molnet blir restiden flaskhalsen. Äldre schemaläggningsmetoder förlitade sig på fasta regler eller handgjorda heuristiker som ofta fallerar när arbetsmängder skjuter i höjden eller nätverksförhållanden förändras snabbt.
En lärande hjärna för var arbetet ska gå
Författarna föreslår IntelliScheduler, ett ramverk som betraktar uppgiftsplacering i ett kant–moln‑system som ett inlärningsproblem snarare än en samling fasta regler. Kärnan är en form av djup förstärkningsinlärning: en artificiell agent observerar systemets nuvarande tillstånd — hur upptagna kant‑ och molnmaskiner är, hur långa deras köer är, hur brådskande inkommande uppgifter verkar — och väljer sedan en handling, till exempel att skicka en uppgift till kanten, till molnet eller dela upp arbetet mellan dem. Efter varje val får agenten återkoppling främst baserad på hur länge enheter behövde vänta och om några servicetidsgränser missades. Över många omgångar av trial‑and‑error lär sig systemet gradvis en policy som tenderar att minimera väntetider och bibehålla servicenivåavtal.
Att minnas många sorters hektiska dagar
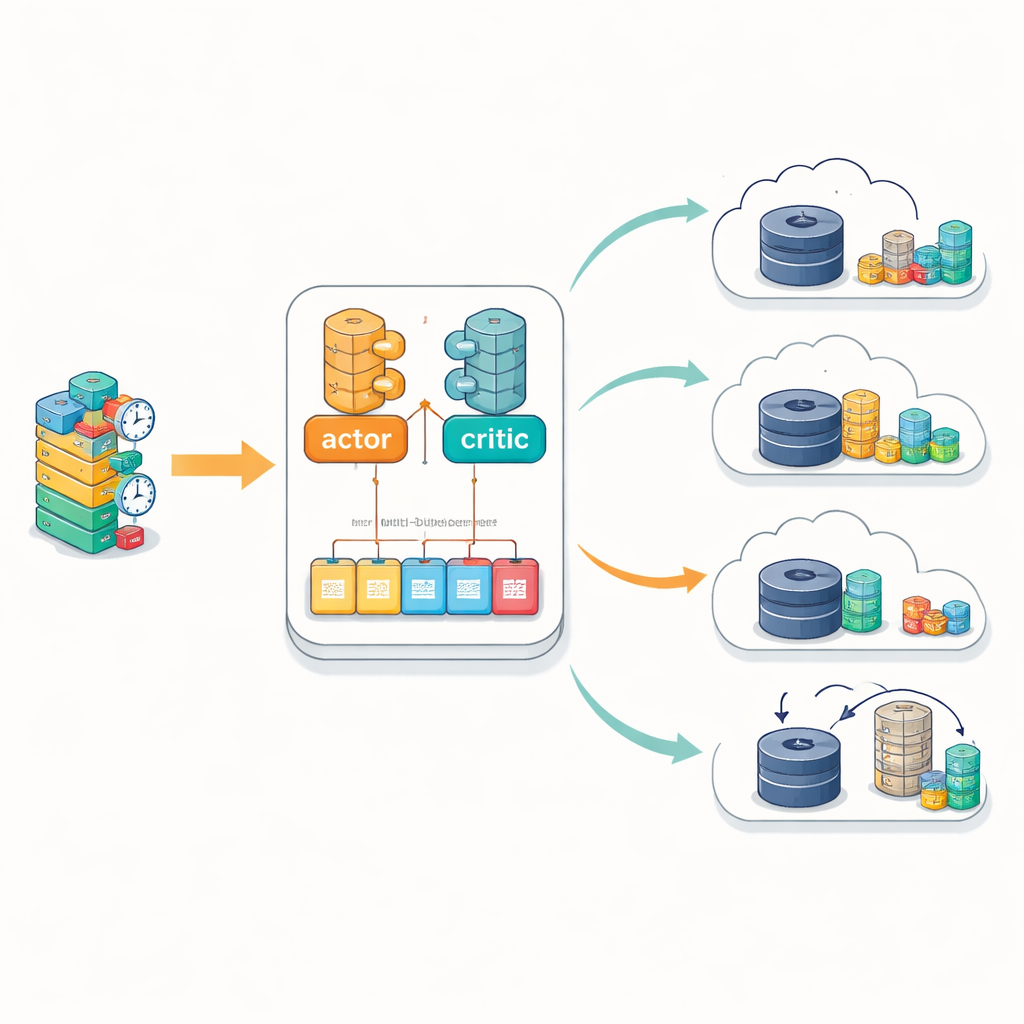
En nyckelinnovation är hur IntelliScheduler lär sig av erfarenhet. I stället för att lagra tidigare situationer och beslut i en enda lång lista håller det flera separata minnesbuffertar. Varje buffert samlar exempel från olika driftförhållanden — såsom låg belastning, kraftig trängsel eller obalanserad kantanvändning. Under träning provtar agenten från alla dessa buffertar, med preferens för erfarenheter där dess tidigare förutsägelser var mest felaktiga. Denna flerbuffertdesign hjälper inlärningsprocessen att förbli stabil även när miljön förändras, och undviker de svängningar som kan uppstå när en modell hela tiden återlär sig endast från de senaste händelserna. Den matematiska modellen bakom detta tillvägagångssätt tar uttryckligen hänsyn till tre sätt en uppgift kan hanteras: helt i molnet, helt i kanten eller i en hybridform där bearbetning migrerar från kanten till molnet om resurserna blir knappa.
Sätter ramverket på prov
För att studera IntelliSchedulers beteende byggde forskarna en detaljerad simulator av ett kant–moln‑system som kör IoT‑arbetsflöden. De jämförde sin Learning‑based Optimal Task Scheduling (LbOTS)-algoritm med tre populära optimeringsbaserade schemaläggare hämtade från svärmintelligens och metaheuristiker. Över små, medelstora och stora syntetiska arbetsbelastningar — upp till en miljon jobb — gav det lärandebaserade tillvägagångssättet konsekvent högre total belöning, en signal som kombinerar kortare väntetider och bättre uppfyllande av tidsgränser. Det tränade mer tillförlitligt, med upp till två tredjedels lägre inlärningsförlust, och använde resurser mer effektivt, vilket minskade uppskattade driftkostnader med ungefär hälften eller mer. Kanske mest anmärkningsvärt minskade andelen uppgifter som avvisades på grund av överbelastning med omkring 80–90 procent, och användarupplevd kvalitet förbättrades med cirka 15–75 procent jämfört med de konkurrerande metoderna.
Vad detta betyder för vardagliga uppkopplade enheter
I praktiska termer antyder studien att en adaptiv, lärandestyrd ”flygledare” för digitala uppgifter kan göra kant–moln‑system mer responsiva och ekonomiska än statiska schemaläggningsregler. IntelliScheduler visar att genom att kontinuerligt övervaka hur upptagna servrar och nätverk är, och genom att lära av ett brett spektrum av tidigare förhållanden, kan en automatiserad agent hålla tidskänsliga IoT‑applikationer igång smidigt med färre förlorade förfrågningar. Medan de nuvarande resultaten kommer från kontrollerade simuleringar och huvudsakligen fokuserar på fördröjning och kostnad snarare än energianvändning eller säkerhet, är ramverket utformat för att kunna utökas. När sådana system går från simuleringar till verkliga distributioner kan de bidra till att den växande nätverket av vardagliga smarta enheter känns snabbare, mer pålitligt och mindre slösaktigt i bakgrunden.
Citering: Raju, L.R., Reddy, M.V.K., Surukanti, S.R. et al. IntelliScheduler: an edge-cloud computing environment hybrid deep learning framework for task scheduling based on learning. Sci Rep 16, 11219 (2026). https://doi.org/10.1038/s41598-026-41330-8
Nyckelord: edge computing, cloud computing, task scheduling, reinforcement learning, Internet of Things