Clear Sky Science · en
IntelliScheduler: an edge-cloud computing environment hybrid deep learning framework for task scheduling based on learning
Why waiting for the cloud still matters
Every time a smart camera flags a stranger at your door, or a connected car reacts to traffic, it sends small jobs—"tasks"—to be processed somewhere on the internet. If those jobs always travel all the way to distant data centers, the round trip can be too slow for time‑critical actions. This paper introduces IntelliScheduler, a learning-based system that decides in real time which tasks should be handled close to the user at the network’s edge and which can safely go to the cloud, aiming to keep responses snappy while holding down costs.
From faraway servers to nearby helpers
Traditional cloud computing has been a workhorse for online services because it can cheaply scale to millions of users. But for many modern Internet of Things (IoT) uses—such as factory sensors, smart vehicles, or health wearables—every extra millisecond of delay can matter. To reduce that delay, companies now deploy smaller servers near users, known as edge servers. These edge machines can respond faster but have limited capacity. If too many tasks are pushed to the edge, they get stuck in line; if too many are sent to the cloud, the trip time becomes the bottleneck. Older scheduling methods relied on fixed rules or hand-crafted heuristics that often break down when workloads spike or network conditions change quickly.
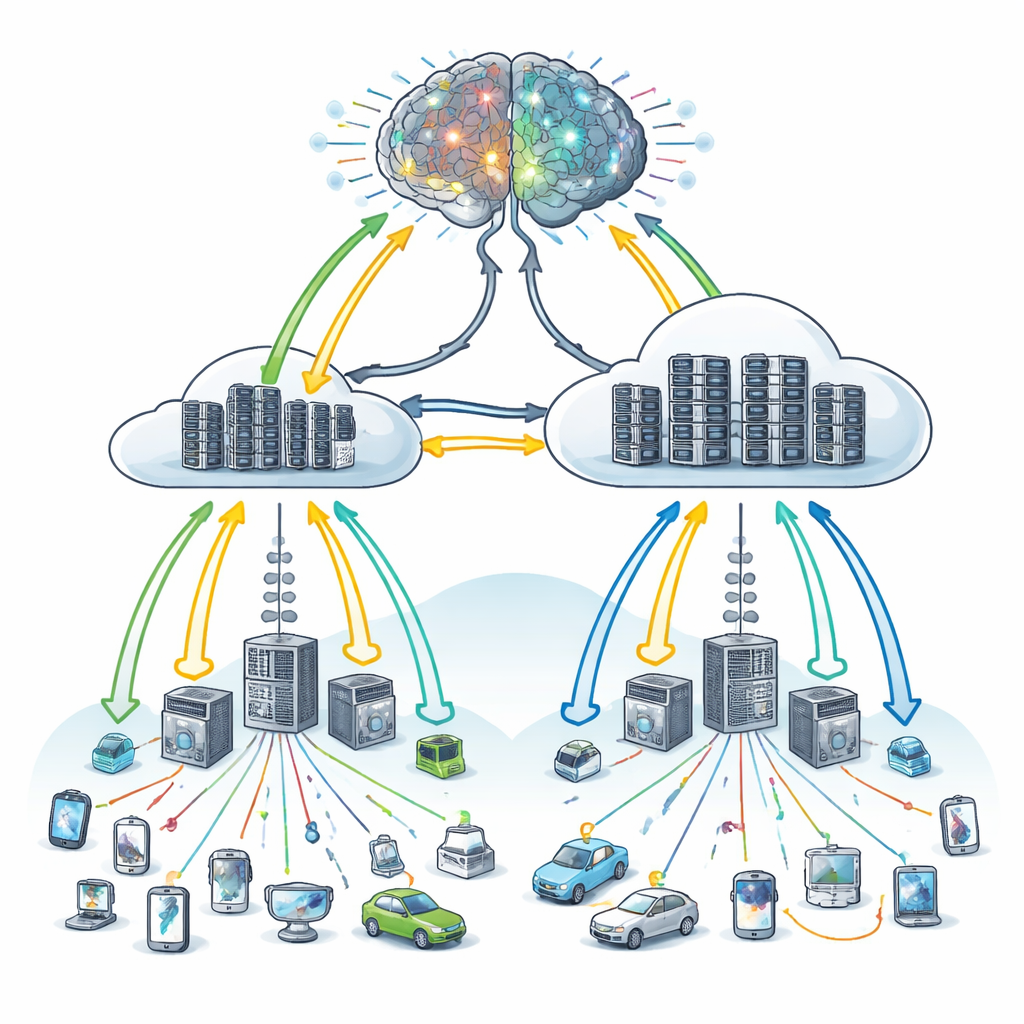
A learning brain for where work should go
The authors propose IntelliScheduler, a framework that treats task placement in an edge–cloud system as a learning problem rather than a fixed rulebook. At its core is a form of deep reinforcement learning: an artificial agent observes the current state of the system—how busy edge and cloud machines are, how long their queues are, how urgent incoming tasks appear—and then chooses an action, such as sending a task to the edge, to the cloud, or splitting work between them. After each choice, the agent receives feedback based mainly on how long devices had to wait and whether any service deadlines were missed. Over many rounds of trial and error, the system gradually learns a policy that tends to minimize waiting time and keep service-level agreements intact.
Remembering many kinds of busy days
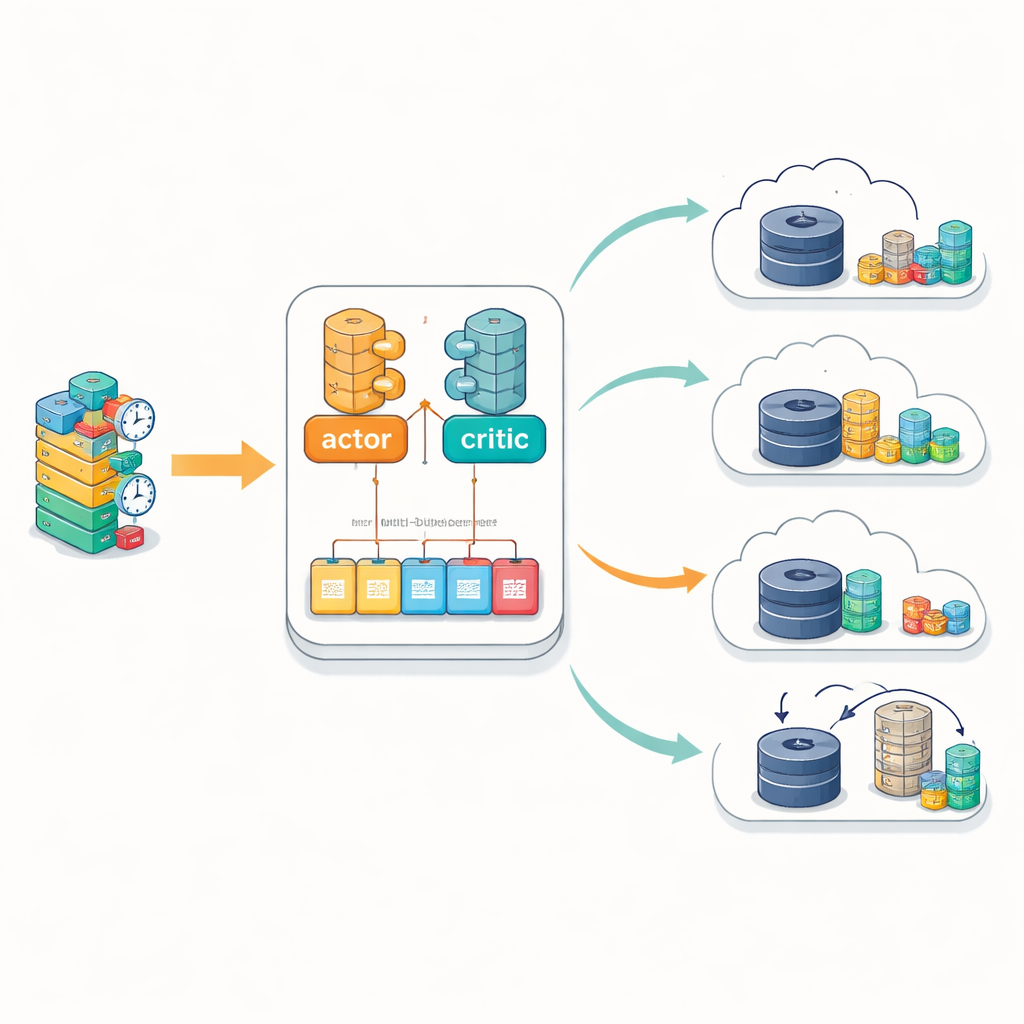
A key innovation is how IntelliScheduler learns from experience. Rather than storing past situations and decisions in a single long list, it maintains several separate memory buffers. Each buffer collects examples from different operating conditions—such as light load, heavy congestion, or imbalanced edge usage. During training, the agent samples from all of these buffers, with a preference for experiences where its past predictions were most off-target. This multi-buffer design helps the learning process remain stable even as the environment changes, avoiding the oscillations that can happen when a model repeatedly relearns only from the most recent events. The mathematical model backing this approach explicitly accounts for three ways a task can be handled: entirely at the cloud, entirely at the edge, or in a hybrid fashion where processing migrates from edge to cloud if resources become tight.
Putting the framework to the test
To study IntelliScheduler’s behavior, the researchers built a detailed simulator of an edge–cloud system running IoT workflows. They compared their Learning-based Optimal Task Scheduling (LbOTS) algorithm against three popular optimization-based schedulers drawn from swarm intelligence and metaheuristics. Across small, medium, and large synthetic workloads—ranging up to one million jobs—the learning-based approach consistently earned higher overall reward, a signal that combines shorter waits and better deadline satisfaction. It trained more reliably, with up to two‑thirds lower learning loss, and it used resources more efficiently, cutting estimated operational costs by roughly half or more. Perhaps most strikingly, the rate at which tasks were rejected due to overload dropped by around 80–90 percent, and user-perceived quality of experience improved by about 15–75 percent compared with the competing approaches.
What this means for everyday connected devices
In practical terms, the study suggests that an adaptive, learning-driven "air traffic controller" for digital tasks can make edge–cloud systems more responsive and economical than static scheduling rules. IntelliScheduler shows that by continuously watching how busy servers and networks are, and by learning from a wide range of past conditions, an automated agent can keep time-sensitive IoT applications running smoothly with fewer dropped requests. While the current results come from controlled simulations and focus mainly on delay and cost rather than energy use or security, the framework is designed to be extended. As such systems move from simulations to real deployments, they could help ensure that the growing web of everyday smart devices feels faster, more reliable, and less wasteful behind the scenes.
Citation: Raju, L.R., Reddy, M.V.K., Surukanti, S.R. et al. IntelliScheduler: an edge-cloud computing environment hybrid deep learning framework for task scheduling based on learning. Sci Rep 16, 11219 (2026). https://doi.org/10.1038/s41598-026-41330-8
Keywords: edge computing, cloud computing, task scheduling, reinforcement learning, Internet of Things