Clear Sky Science · it
IntelliScheduler: un framework ibrido di deep learning per l’ambiente edge-cloud per la schedulazione dei task basato sull’apprendimento
Perché aspettare il cloud conta ancora
Ogni volta che una videocamera intelligente segnala uno sconosciuto alla tua porta o un’auto connessa reagisce al traffico, invia piccoli lavori — “task” — da elaborare da qualche parte su Internet. Se questi task viaggiano sempre fino a data center lontani, il tempo di andata e ritorno può essere troppo lento per azioni sensibili al tempo. Questo articolo presenta IntelliScheduler, un sistema basato sull’apprendimento che decide in tempo reale quali task devono essere gestiti vicino all’utente, ai margini della rete (edge), e quali possono essere inviati in modo sicuro al cloud, con l’obiettivo di mantenere le risposte rapide riducendo al contempo i costi.
Dai server lontani agli assistenti vicini
Il cloud tradizionale è stato il cavallo di battaglia per i servizi online perché può scalare a basso costo per milioni di utenti. Ma per molti usi moderni dell’Internet of Things (IoT) — come sensori di fabbrica, veicoli intelligenti o dispositivi indossabili per la salute — ogni millisecondo in più di latenza può fare la differenza. Per ridurre questa latenza, le aziende ora dispiegano server più piccoli vicino agli utenti, noti come server edge. Queste macchine locali possono rispondere più rapidamente ma hanno capacità limitate. Se troppi task vengono spinti verso l’edge, si accumulano in coda; se troppi vengono inviati al cloud, il tempo di viaggio diventa il collo di bottiglia. I metodi di schedulazione tradizionali si basavano su regole fisse o euristiche progettate a mano che spesso collassano quando i carichi di lavoro aumentano o le condizioni di rete cambiano rapidamente.
Un cervello che impara dove assegnare il lavoro
Gli autori propongono IntelliScheduler, un framework che considera il posizionamento dei task in un sistema edge–cloud come un problema di apprendimento anziché un insieme di regole fisse. Al suo cuore c’è una forma di deep reinforcement learning: un agente artificiale osserva lo stato corrente del sistema — quanto sono occupati i nodi edge e cloud, la lunghezza delle loro code, quanto appaiono urgenti i task in arrivo — e poi sceglie un’azione, come inviare un task all’edge, al cloud o dividere il lavoro tra i due. Dopo ogni scelta, l’agente riceve un feedback basato principalmente sui tempi di attesa e sul mancato rispetto dei vincoli di servizio. Dopo molti cicli di tentativi ed errori, il sistema impara gradualmente una politica che tende a minimizzare i tempi di attesa e a mantenere gli accordi di livello di servizio.
Ricordare molti tipi di giornate affollate
Un’innovazione chiave è il modo in cui IntelliScheduler apprende dall’esperienza. Piuttosto che memorizzare situazioni e decisioni passate in un’unica lunga lista, mantiene diversi buffer di memoria separati. Ogni buffer raccoglie esempi da differenti condizioni operative — come carico leggero, forte congestione o uso sbilanciato dell’edge. Durante l’addestramento, l’agente campiona da tutti questi buffer, con una preferenza per le esperienze in cui le sue predizioni passate erano più errate. Questo design a multi-buffer aiuta il processo di apprendimento a rimanere stabile anche quando l’ambiente cambia, evitando le oscillazioni che possono verificarsi quando un modello rieduca continuamente se stesso solo sugli eventi più recenti. Il modello matematico che supporta questo approccio tiene esplicitamente conto di tre modalità con cui un task può essere gestito: completamente nel cloud, completamente all’edge o in modo ibrido, dove l’elaborazione migra dall’edge al cloud se le risorse si fanno scarse.
Mettere il framework alla prova
Per studiare il comportamento di IntelliScheduler, i ricercatori hanno costruito un simulatore dettagliato di un sistema edge–cloud che esegue workflow IoT. Hanno confrontato il loro algoritmo Learning-based Optimal Task Scheduling (LbOTS) con tre scheduler popolari basati su ottimizzazione tratti dall’intelligenza degli sciami e dalle metaeuristiche. Su carichi di lavoro sintetici piccoli, medi e grandi — fino a un milione di job — l’approccio basato sull’apprendimento ha ottenuto costantemente una ricompensa complessiva più alta, un indicatore che combina tempi di attesa più brevi e migliore rispetto delle scadenze. Si è addestrato in modo più affidabile, con una perdita di apprendimento ridotta fino a due terzi, e ha utilizzato le risorse in modo più efficiente, riducendo i costi operativi stimati di circa la metà o più. Forse più sorprendente, il tasso di rifiuto dei task dovuto a sovraccarico è diminuito di circa l’80–90% e la qualità dell’esperienza percepita dagli utenti è migliorata di circa il 15–75% rispetto agli approcci concorrenti.
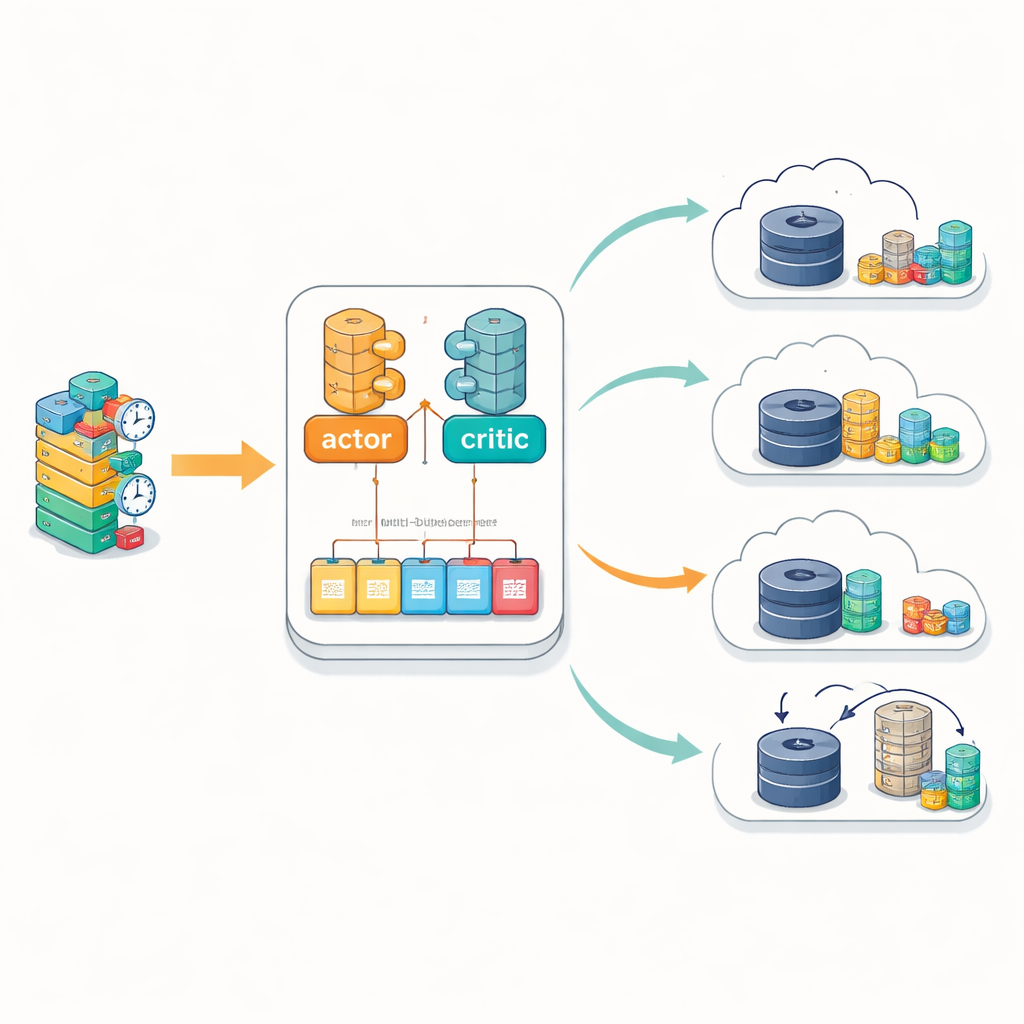
Cosa significa per i dispositivi connessi di tutti i giorni
In termini pratici, lo studio suggerisce che un “controllore del traffico aereo” adattivo e guidato dall’apprendimento per i task digitali può rendere i sistemi edge–cloud più reattivi ed economici rispetto a regole di schedulazione statiche. IntelliScheduler dimostra che, monitorando continuamente quanto sono occupati server e reti e imparando da un’ampia gamma di condizioni passate, un agente automatizzato può mantenere applicazioni IoT sensibili al tempo in funzione in modo fluido con meno richieste scartate. Pur provenendo da simulatori controllati e concentrandosi principalmente su latenza e costi più che su consumo energetico o sicurezza, il framework è progettato per essere estendibile. Quando tali sistemi passeranno dalle simulazioni alle implementazioni reali, potrebbero contribuire a fare in modo che la sempre più ampia rete di dispositivi intelligenti quotidiani sembri più veloce, più affidabile e meno sprecona dietro le quinte.
Citazione: Raju, L.R., Reddy, M.V.K., Surukanti, S.R. et al. IntelliScheduler: an edge-cloud computing environment hybrid deep learning framework for task scheduling based on learning. Sci Rep 16, 11219 (2026). https://doi.org/10.1038/s41598-026-41330-8
Parole chiave: edge computing, cloud computing, schedulazione dei task, apprendimento per rinforzo, Internet of Things