Clear Sky Science · pl
IntelliScheduler: hybrydowy framework deep learning dla harmonogramowania zadań w środowisku edge-cloud oparty na uczeniu
Dlaczego wciąż warto czekać na chmurę
Za każdym razem, gdy inteligentna kamera zgłasza nieznajomego przy drzwiach albo samochód połączony z siecią reaguje na ruch, wysyła małe zadania — „taski” — do przetworzenia gdzieś w Internecie. Jeśli te zadania zawsze lecą aż do odległych centrów danych, czas podróży może być zbyt długi dla działań wymagających szybkiej reakcji. W pracy tej zaprezentowano IntelliScheduler, system oparty na uczeniu, który w czasie rzeczywistym decyduje, które zadania powinny być obsłużone blisko użytkownika na krawędzi sieci (edge), a które można bezpiecznie wysłać do chmury, dążąc do szybkich odpowiedzi przy jednoczesnym ograniczeniu kosztów.
Od dalekich serwerów do lokalnych pomocników
Tradycyjne przetwarzanie w chmurze było siłą napędową usług online, ponieważ można je tanio skalować do milionów użytkowników. Jednak dla wielu współczesnych zastosowań Internetu Rzeczy (IoT) — takich jak czujniki w fabrykach, inteligentne pojazdy czy urządzenia monitorujące zdrowie — każdy dodatkowy milisekund opóźnienia może mieć znaczenie. Aby zmniejszyć to opóźnienie, firmy wdrażają mniejsze serwery blisko użytkowników, zwane serwerami edge. Maszyny te mogą odpowiadać szybciej, ale mają ograniczoną pojemność. Jeśli zbyt wiele zadań trafi na edge, tworzą się kolejki; jeśli zbyt wiele trafi do chmury, czas podróży staje się wąskim gardłem. Starsze metody harmonogramowania opierały się na stałych regułach lub ręcznie tworzonych heurystykach, które często zawodzą, gdy nagle rośnie obciążenie lub warunki sieciowe szybko się zmieniają.
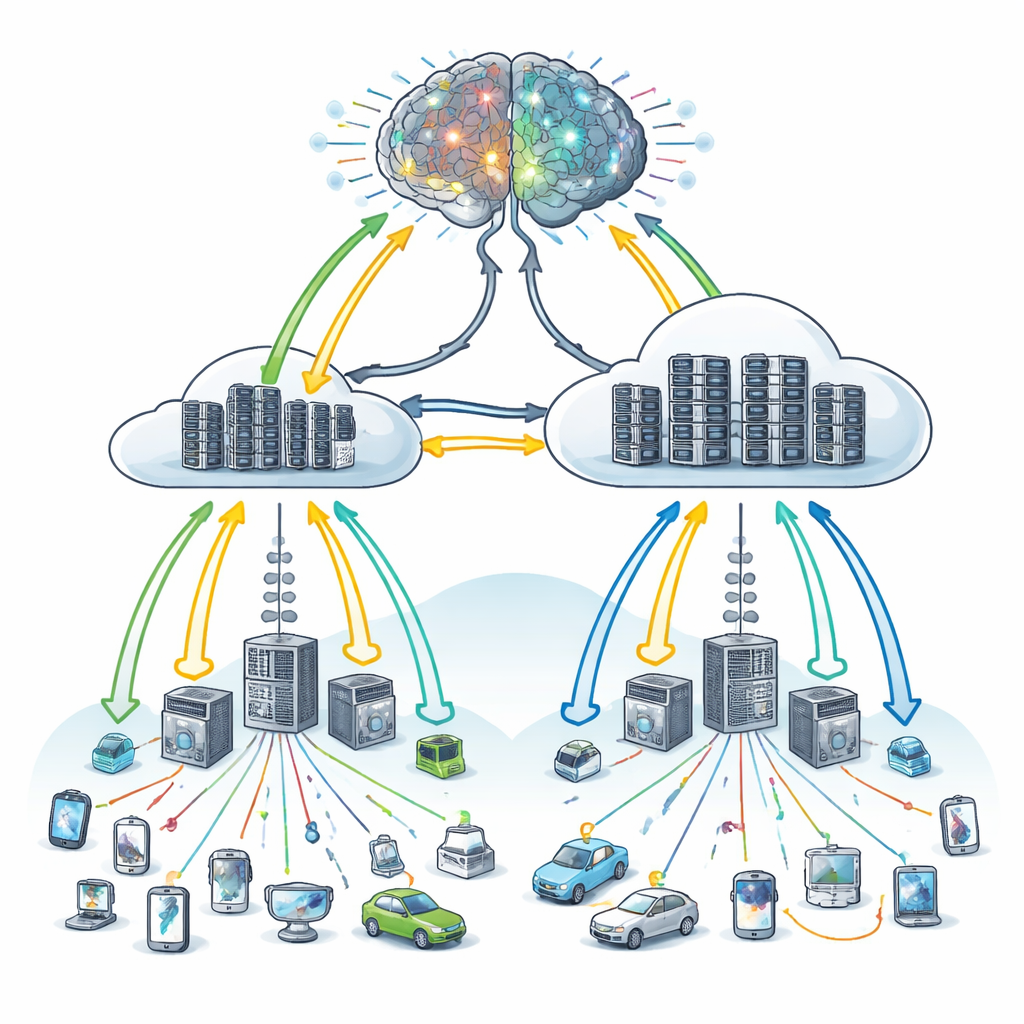
Mózg uczący się, gdzie powinno trafić zadanie
Autorzy proponują IntelliScheduler — framework traktujący rozmieszczanie zadań w systemie edge–cloud jako problem uczenia, a nie zbiór sztywnych reguł. W jego rdzeniu znajduje się rodzaj głębokiego uczenia ze wzmocnieniem: sztuczny agent obserwuje aktualny stan systemu — jak zajęte są maszyny na edge i w chmurze, jak długie są ich kolejki, jak pilne wydają się nadchodzące zadania — i wybiera akcję, np. wysłanie zadania na edge, do chmury lub rozdzielenie pracy między nie. Po każdym wyborze agent otrzymuje informację zwrotną opartą głównie na czasie oczekiwania urządzeń i tym, czy naruszono terminy usług. Wiele rund prób i błędów pozwala systemowi stopniowo nauczyć się polityki, która minimalizuje czas oczekiwania i utrzymuje umowy o poziomie usług.
Pamiętanie wielu rodzajów dni szczytu
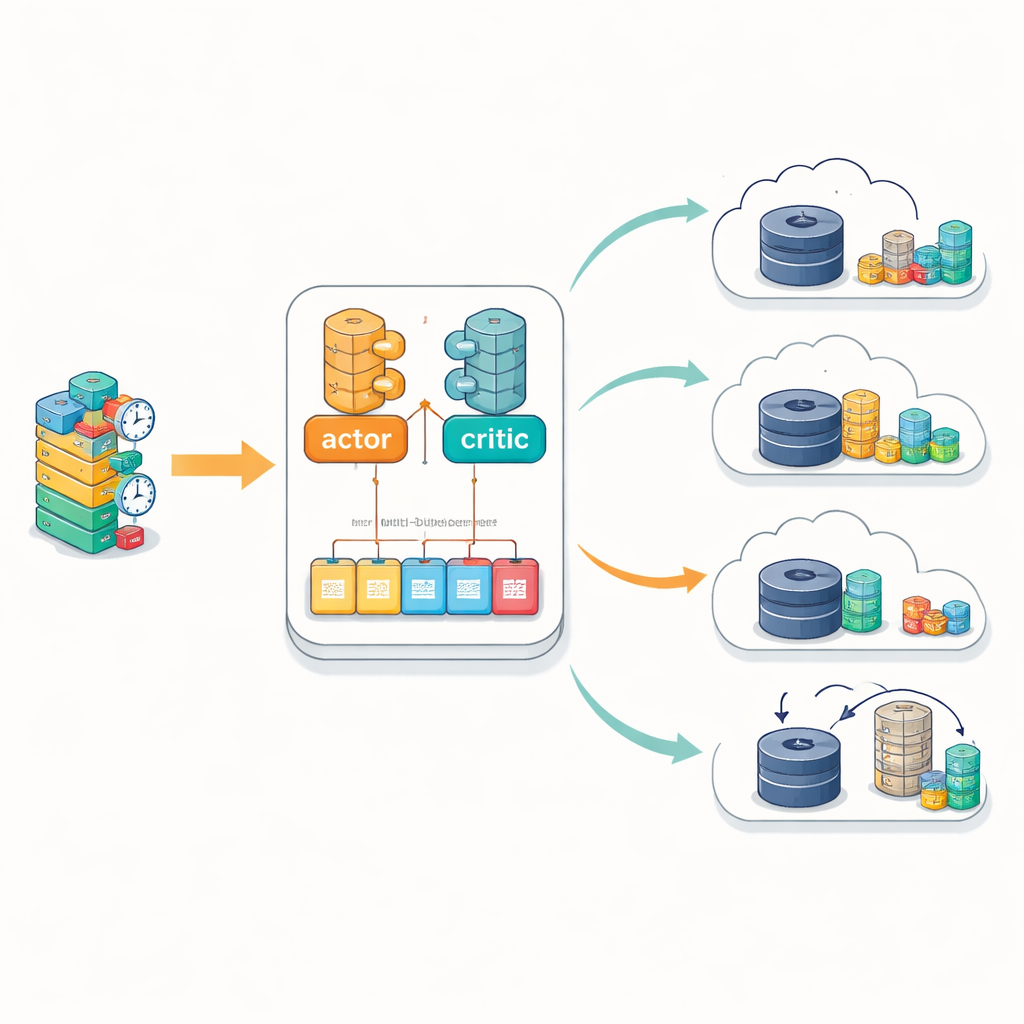
Kluczową innowacją jest sposób, w jaki IntelliScheduler uczy się na podstawie doświadczeń. Zamiast przechowywać przeszłe sytuacje i decyzje w jednej długiej liście, utrzymuje kilka oddzielnych buforów pamięci. Każdy bufor zbiera przykłady z różnych warunków operacyjnych — na przykład przy małym obciążeniu, przy dużych zatorach czy przy niezrównoważonym wykorzystaniu edge. Podczas treningu agent próbuje próbki ze wszystkich tych buforów, z preferencją dla doświadczeń, w których jego wcześniejsze przewidywania były najbardziej nietrafione. Ten wielobuforowy projekt pomaga procesowi uczenia pozostać stabilnym nawet w zmieniającym się środowisku, unikając oscylacji, które pojawiają się, gdy model uczy się na nowo wyłącznie z najnowszych zdarzeń. Model matematyczny stojący za tym podejściem explicite uwzględnia trzy sposoby obsługi zadania: całkowicie w chmurze, całkowicie na edge albo w trybie hybrydowym, gdzie przetwarzanie przechodzi z edge do chmury, jeśli zasoby stają się niewystarczające.
Testowanie frameworku
Aby zbadać zachowanie IntelliScheduler, badacze zbudowali szczegółowy symulator systemu edge–cloud uruchamiającego workflowy IoT. Porównali swój algorytm Learning-based Optimal Task Scheduling (LbOTS) z trzema popularnymi schedulerami opartymi na optymalizacji, zaczerpniętymi z inteligencji rojowej i metaheurystyk. W testach na małych, średnich i dużych syntetycznych obciążeniach — sięgających do miliona zadań — podejście oparte na uczeniu konsekwentnie osiągało wyższą łączną nagrodę, sygnalizującą krótsze oczekiwanie i lepsze dotrzymywanie terminów. Trenowało się bardziej niezawodnie, z nawet do dwóch trzecich niższą stratą uczenia, i wykorzystywało zasoby bardziej efektywnie, szacunkowo obniżając koszty operacyjne o około połowę lub więcej. Co być może najbardziej uderzające, współczynnik odrzuceń zadań z powodu przeciążenia spadł o około 80–90%, a postrzegana przez użytkowników jakość doświadczenia poprawiła się o około 15–75% w porównaniu z konkurencyjnymi podejściami.
Co to oznacza dla codziennych urządzeń połączonych z siecią
W praktyce badanie sugeruje, że adaptacyjny, sterowany uczeniem „kontroler ruchu lotniczego” dla zadań cyfrowych może uczynić systemy edge–cloud bardziej responsywnymi i ekonomicznymi niż statyczne reguły harmonogramowania. IntelliScheduler pokazuje, że przez ciągłe monitorowanie obciążenia serwerów i sieci oraz uczenie się na podstawie szerokiego zakresu przeszłych warunków, zautomatyzowany agent może utrzymać aplikacje IoT wrażliwe na czas w płynnym działaniu przy mniejszej liczbie odrzuconych żądań. Chociaż obecne wyniki pochodzą z kontrolowanych symulacji i koncentrują się głównie na opóźnieniach i kosztach, a nie na zużyciu energii czy bezpieczeństwie, framework został zaprojektowany z myślą o rozszerzalności. W miarę jak takie systemy przejdą od symulacji do rzeczywistych wdrożeń, mogą pomóc sprawić, że rosnąca sieć codziennych inteligentnych urządzeń będzie działać szybciej, bardziej niezawodnie i mniej marnotrawnie w tle.
Cytowanie: Raju, L.R., Reddy, M.V.K., Surukanti, S.R. et al. IntelliScheduler: an edge-cloud computing environment hybrid deep learning framework for task scheduling based on learning. Sci Rep 16, 11219 (2026). https://doi.org/10.1038/s41598-026-41330-8
Słowa kluczowe: edge computing, cloud computing, harmonogramowanie zadań, uczenie ze wzmocnieniem, Internet rzeczy