Clear Sky Science · sv
En flernivå visuell representationsdatamängd för storskalig icke‑finansiell informationspublicering
Varför företagsrapporters utseende spelar roll
När stora företag redovisar sin miljömässiga eller sociala påverkan publicerar de inte längre enkla svartvita dokument. Deras hållbarhetsrapporter är fyllda med fotografier, ikoner och starka färger avsedda att fånga blicken och forma vår uppfattning. Men fram till nu har det saknats ett stort, objektivt sätt att mäta hur dessa visuella val används. Denna studie introducerar en ny datamängd och ett mätsystem som omvandlar utseendet och känslan hos tusentals kinesiska hållbarhetsrapporter till hårda siffror, vilket hjälper forskare, tillsynsmyndigheter och medborgare att bättre förstå hur företag kommunicerar genom design såväl som ord.
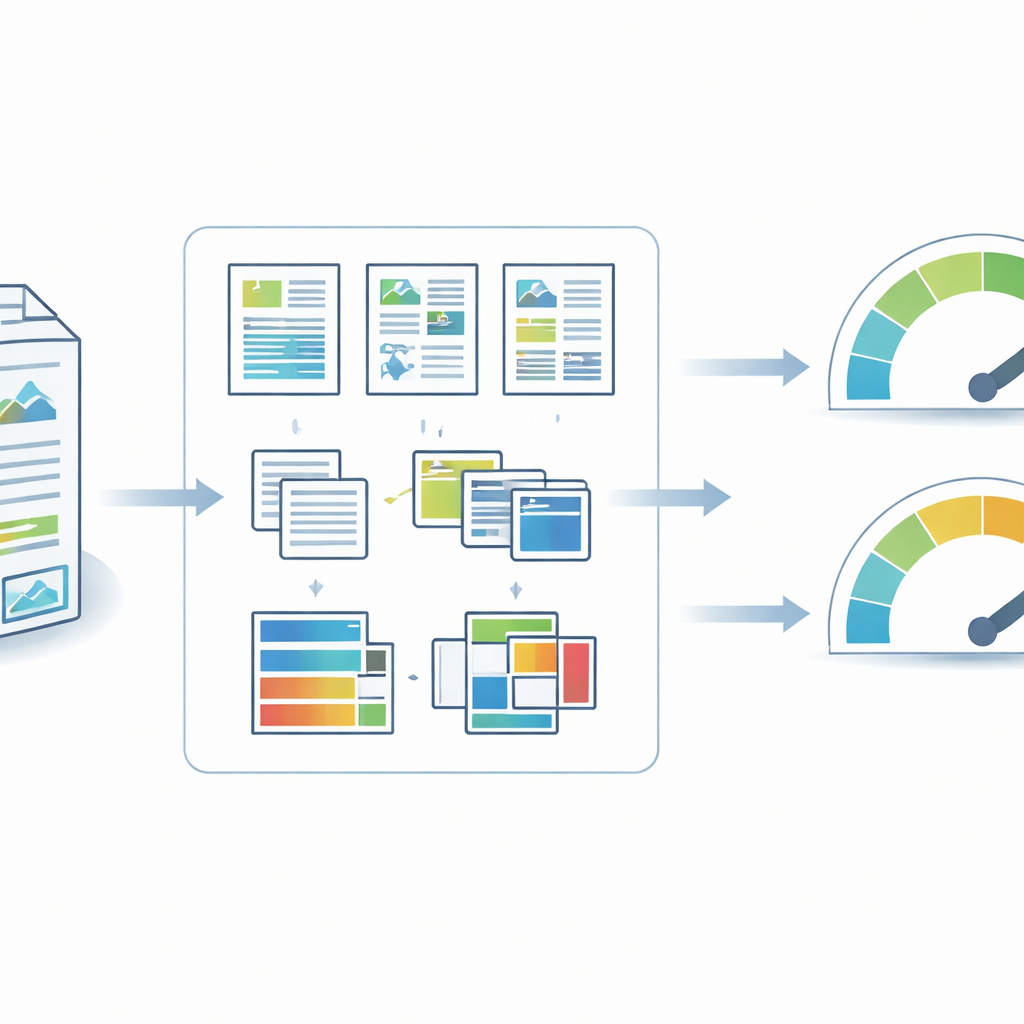
Från högar av rapporter till organiserade visuella data
Författarna samlade hållbarhetsrapporter från kinesiska företag noterade på Shanghai‑ och Shenzhen‑börserna, med hjälp av CNINFO, landets officiella informationsplattform. Med täckning för räkenskapsåren 2006 till 2024 fångar samlingen hur icke‑finansiell rapportering i Kina har gått från att vara ett undantag till att bli vanligt, särskilt efter att nya börsregler uppmuntrade företag att rapportera om sociala och miljömässiga frågor. Alla dokument laddades ner i original‑PDF‑format för att bevara deras visuella layout. Ett automatiserat Python‑skript filtrerade bort korrupta filer, extraherade grundläggande information såsom aktiekod och år, och organiserade rapporterna i ett standardiserat mappsystem så att varje fil kunde spåras unikt och pålitligt över tid.
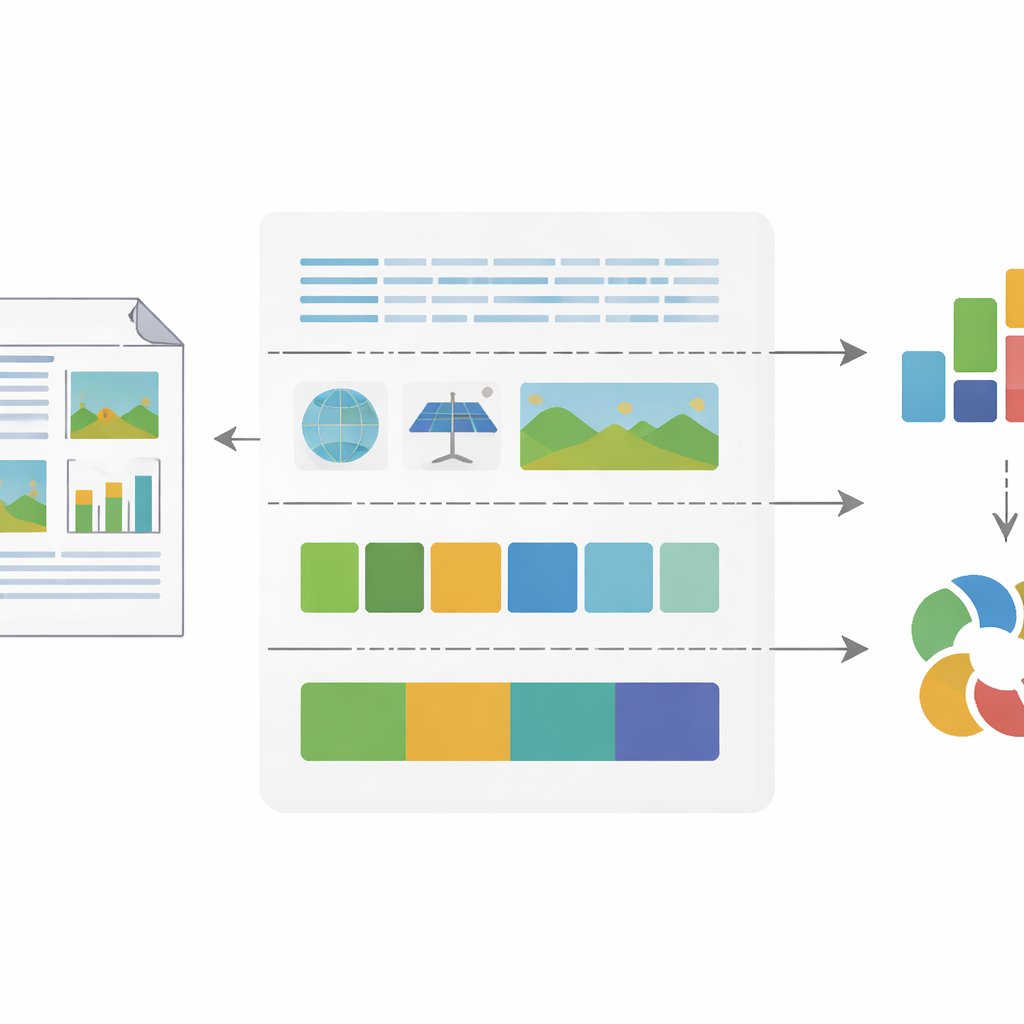
Att dela upp sidor i text, bilder och färg
För att analysera visuellt material i stor skala konverterade teamet varje rapportsida till högupplösta bilder och använde moderna datorvisionsverktyg för att dela upp sidorna i meningsfulla delar. En layoutanalysmodell identifierade var textblock, bilder, tabeller, rubriker och andra element förekom på varje sida. Textrutor matades till ett optiskt teckenigenkänningssystem som inte bara läste orden utan också mätte egenskaper som radavstånd, teckenstorlek i förhållande till sidan och hur många ord som förekom i varje rad och på varje sida. Bildområden klassificerades som antingen ”abstrakta” (såsom diagram eller ikoner) eller ”realistiska” (såsom fotografier), vilket fångar om ett företag lutar mer mot datadrivna visuella framställningar eller emotionell, fotobaserad berättande. Samtidigt skannade en färganalysrutin varje pixel, sorterade dem i ett antal grundläggande färgkategorier och beräknade hur stor del av sidan varje färg upptog.
Att omvandla visuella stilar till siffror
Från dessa byggstenar definierade forskarna 18 detaljerade indikatorer för hur varje sida och varje rapport använder text, bilder och färg — alltifrån andelen yta som bilder tar upp till balansen mellan varma och kalla toner. De kombinerade sedan dessa indikatorer till två nyckelindex. Informationsentropiindexet mäter visuell komplexitet genom att undersöka hur varierat färgpaletten är: sidor som använder många olika färger i liknande proportioner får höga poäng, medan enkla, nästan monokroma sidor får låga poäng. Funktionskorrelationsindexet fångar hur visuellt konsekvent en rapport är från sida till sida genom att beräkna hur lika sidorna är med varandra i detta 18‑dimensionella funktionsrum. Lägre värden betyder att sidorna följer en stabil visuell stil; högre värden betyder att designen skiftar mer dramatiskt genom dokumentet.
Kontrollera att siffrorna stämmer med mänskliga intryck
Där värdet av ett index beror på om det speglar vad människor faktiskt ser, validerade teamet noggrant sina mått. De finslipade och testade sina datorvisionsmodeller på tusentals manuellt etiketterade sidor och bilder och uppnådde höga noggrannhetsnivåer i att identifiera layoutelement, läsa text och skilja abstrakta diagram från realistiska fotografier. För att testa de nya indexen jämförde de NFIVI‑poäng med bedömningar från mänskliga experter och flera AI‑system som ombads bedöma hur komplexa och hur konsekventa olika rapporter såg ut. Starka korrelationer visade att högre entropipoäng verkligen motsvarar mer upptagna, mer färgstarka layouter, medan lägre funktionskorrelationspoäng stämmer överens med rapporter som för människor framstår som visuellt stabila och enhetliga.
Vad detta betyder för läsare och granskare
I praktiska termer skapar detta arbete ett slags ”visuellt fingeravtryck” för tusentals företags hållbarhetsrapporter. Det gör det möjligt för forskare att fråga, till exempel, om företag som står under press för dålig miljöprestanda förlitar sig mer på starka färger och blanka bilder, eller om mer återhållsamma designer följer med mer pålitliga upplysningar. Myndigheter och tillsynsgrupper skulle kunna använda dessa verktyg för att upptäcka potentiellt vilseledande designval eller för att övervaka hur rapporteringsstilar förändras efter att nya regler införts. Genom att översätta sidlayouter, bildval och färgscheman till transparenta mått gör datamängden det möjligt att studera inte bara vad företag säger, utan hur de väljer att visa det.
Citering: Li, B., Xia, B., Cheng, Z. et al. A multi-level visual representation dataset for large-scale non-financial information disclosure. Sci Data 13, 500 (2026). https://doi.org/10.1038/s41597-026-06848-6
Nyckelord: hållbarhetsrapportering, visuell kommunikation, företagsrapportering, data‑driven revision, miljö social styrning