Clear Sky Science · nl
Een dataset met meerniveau visuele representaties voor grootschalige niet-financiële informatieverschaffing
Waarom het uiterlijk van bedrijfsrapporten ertoe doet
Wanneer grote bedrijven praten over hun milieu- of sociale impact, publiceren ze niet langer saaie zwart-witdocumenten. Hun duurzaamheidsrapporten staan vol foto’s, pictogrammen en felle kleuren die bedoeld zijn om de aandacht te trekken en onze indruk te sturen. Tot nu toe bestond er echter geen grote, objectieve manier om te meten hoe deze visuele keuzes worden ingezet. Deze studie introduceert een nieuwe dataset en een meetsysteem dat het uiterlijk en de uitstraling van duizenden Chinese duurzaamheidsrapporten in harde cijfers omzet, en zo onderzoekers, toezichthouders en burgers helpt beter te begrijpen hoe bedrijven via ontwerp, naast woorden, communiceren.
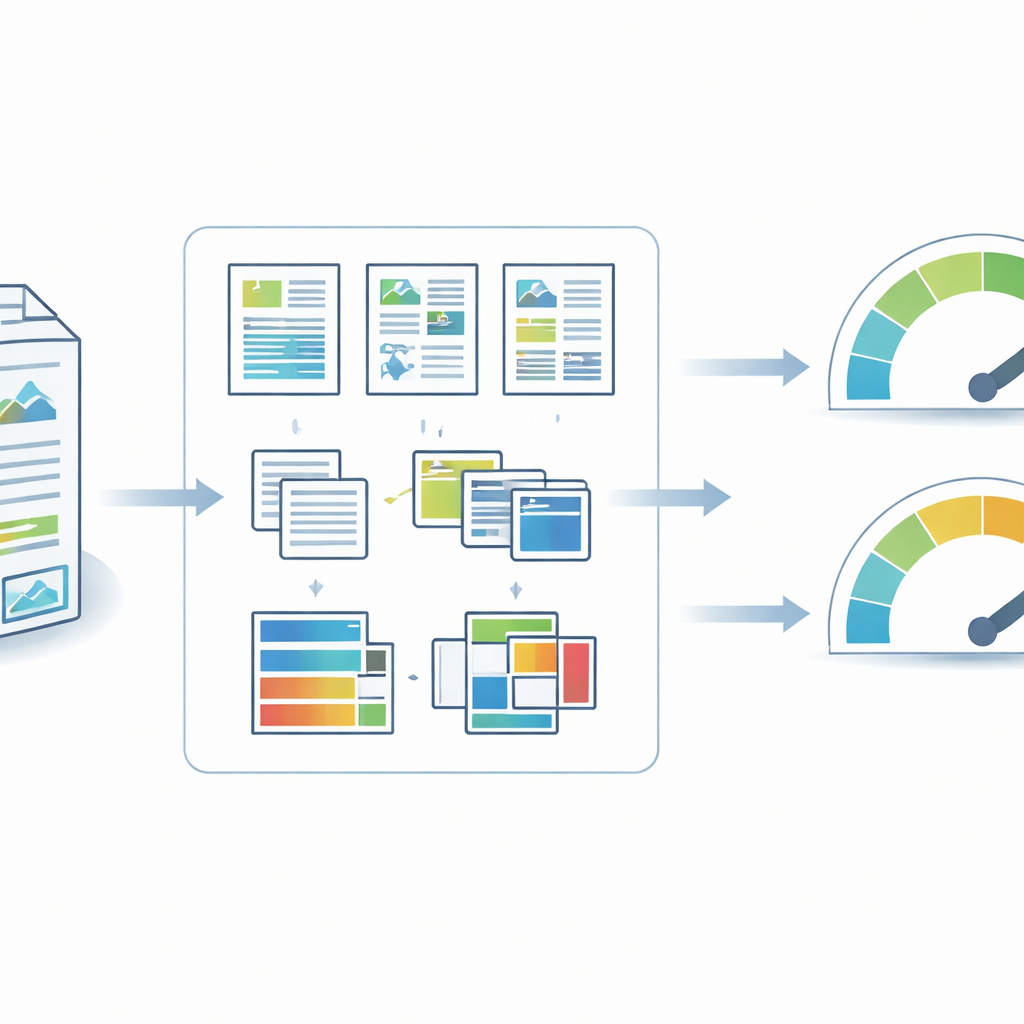
Van stapels rapporten naar georganiseerde visuele data
De auteurs verzamelden duurzaamheidsrapporten van Chinese bedrijven die genoteerd zijn aan de beurzen van Shanghai en Shenzhen, gebruikmakend van CNINFO, het officiële openbaarmakingsplatform van het land. Met verslagjaren van 2006 tot 2024 legt de verzameling vast hoe niet-financiële rapportage in China is gegroeid van zeldzaamheid naar gangbare praktijk, vooral nadat nieuwe beursregels bedrijven aanspoorden te rapporteren over sociale en milieuaspecten. Alle documenten werden in hun oorspronkelijke PDF-formaat gedownload om de visuele opmaak te behouden. Een geautomatiseerd Python-script filterde corrupte bestanden eruit, haalde basisgegevens zoals aandelencode en jaar op, en organiseerde de rapporten in een gestandaardiseerd mappensysteem zodat elk bestand uniek en betrouwbaar in de tijd gevolgd kon worden.
Pagina’s opdelen in tekst, afbeeldingen en kleur
Om visuals op grote schaal te analyseren, converteerde het team iedere raportpagina naar hoge-resolutie afbeeldingen en gebruikte vervolgens moderne computervisiemethoden om deze pagina’s in betekenisvolle onderdelen te splitsen. Een lay-outanalysemodel identificeerde waar tekstblokken, afbeeldingen, tabellen, koppen en andere elementen op elke pagina verschenen. Tekstgebieden werden doorgestuurd naar een optische tekenherkenningssysteem dat niet alleen de woorden las, maar ook kenmerken mat zoals regelafstand, lettergrootte relatief ten opzichte van de pagina en hoeveel woorden er per regel en per pagina verschenen. Beeldgebieden werden geclassificeerd als ofwel “abstract” (zoals grafieken of pictogrammen) of “realistisch” (zoals foto’s), waarmee werd vastgelegd of een bedrijf meer leunde op datagedreven beelden of op emotieverhalende foto’s. Tegelijkertijd scande een kleuranalyselus elke pixel en sorteerde die in één van verschillende basiskleurcategorieën en berekende hoeveel van de pagina elke kleur bezette.
Visuele stijl omzetten in cijfers
Uit deze bouwstenen definiëerden de onderzoekers 18 gedetailleerde indicatoren van hoe elke pagina en elk rapport tekst, beelden en kleur gebruikt—variërend van het aandeel ruimte dat door afbeeldingen wordt ingenomen tot de balans tussen warme en koele tinten. Ze combineerden deze indicatoren vervolgens in twee sleutelindices. De Information Entropy Index meet visuele complexiteit door te kijken naar hoe gevarieerd het kleurenpalet is: pagina’s die veel verschillende kleuren in vergelijkbare verhoudingen gebruiken krijgen hoge scores, terwijl eenvoudige, bijna monochrome pagina’s laag scoren. De Feature-Correlation Index vangt hoe visueel consistent een rapport is van pagina tot pagina door te berekenen hoe vergelijkbaar de pagina’s zijn in deze 18-dimensionale kenmerkruimte. Lagere waarden betekenen dat de pagina’s een vaste visuele stijl volgen; hogere waarden wijzen op meer dramatische verschuivingen in het ontwerp door het document heen.
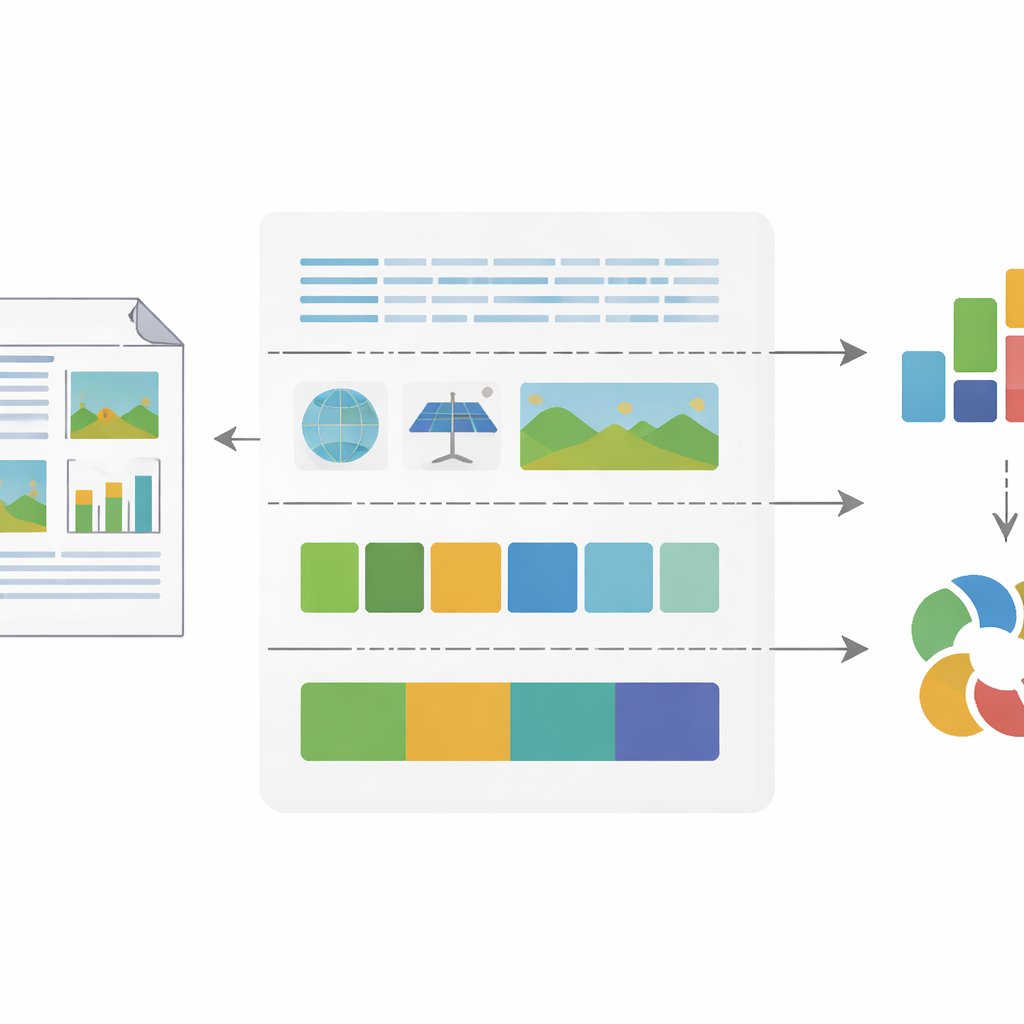
Controleren of de cijfers overeenkomen met menselijke indrukken
Omdat de waarde van elke index afhangt van of deze weerspiegelt wat mensen daadwerkelijk zien, valideerde het team hun maatstaven zorgvuldig. Ze verfijnden en testten hun computervisiemodellen op duizenden handmatig gelabelde pagina’s en afbeeldingen, en bereikten hoge nauwkeurigheid in het identificeren van lay-outelementen, het lezen van tekst en het onderscheid tussen abstracte diagrammen en realistische foto’s. Om de nieuwe indices zelf te toetsen vergeleken ze NFIVI-scores met beoordelingen van menselijke experts en verschillende AI-systemen die gevraagd werden te oordelen hoe complex en hoe consistent verschillende rapporten eruitzagen. Sterke correlaties toonden aan dat hogere entropiescores daadwerkelijk overeenkomen met drukker, kleurrijker opgemaakte pagina’s, terwijl lagere feature-correlation-scores samengaan met rapporten die visueel stabiel en uniform lijken voor menselijke ogen.
Wat dit betekent voor lezers en waakhonden
In alledaagse termen creëert dit werk een soort “visuele vingerafdruk” voor duizenden bedrijfsduurzaamheidsrapporten. Het stelt onderzoekers in staat om vragen te stellen, bijvoorbeeld of bedrijven die onder druk staan vanwege slechte milieu-prestaties zich zwaarder bedienen van felle kleuren en glanzende beelden, of dat soberdere ontwerpen samengaan met betrouwbaardere openbaringen. Toezichthouders en waakhonden kunnen deze hulpmiddelen gebruiken om potentieel misleidende ontwerpen op te sporen of om te monitoren hoe rapportagestijlen veranderen nadat nieuwe regels zijn ingevoerd. Door paginalay-outs, beeldkeuzes en kleurenpaletten om te zetten in transparante metrics, maakt de dataset het mogelijk niet alleen te bestuderen wat bedrijven zeggen, maar ook hoe ze ervoor kiezen het te tonen.
Bronvermelding: Li, B., Xia, B., Cheng, Z. et al. A multi-level visual representation dataset for large-scale non-financial information disclosure. Sci Data 13, 500 (2026). https://doi.org/10.1038/s41597-026-06848-6
Trefwoorden: duurzaamheidsrapportage, visuele communicatie, bedrijfsoverdracht, data-gedreven controle, milieu sociaal bestuur