Clear Sky Science · ru
Набор данных с многоуровневым визуальным представлением для масштабного раскрытия нефинансовой информации
Почему внешний вид корпоративных отчетов имеет значение
Когда крупные компании говорят о своем экологическом или социальном влиянии, они уже не публикуют простые черно‑белые документы. Их отчеты по устойчивому развитию заполнены фотографиями, иконками и насыщенными цветами, призванными привлечь внимание и сформировать впечатление. Но до сих пор не существовало крупномасштабного объективного способа измерить, как используются эти визуальные решения. В этом исследовании представлен новый набор данных и система измерений, которые превращают внешний вид тысяч китайских отчетов по устойчивому развитию в числовые показатели, помогая исследователям, регуляторам и гражданам лучше понимать, как компании коммуницируют через дизайн, а не только через слова.
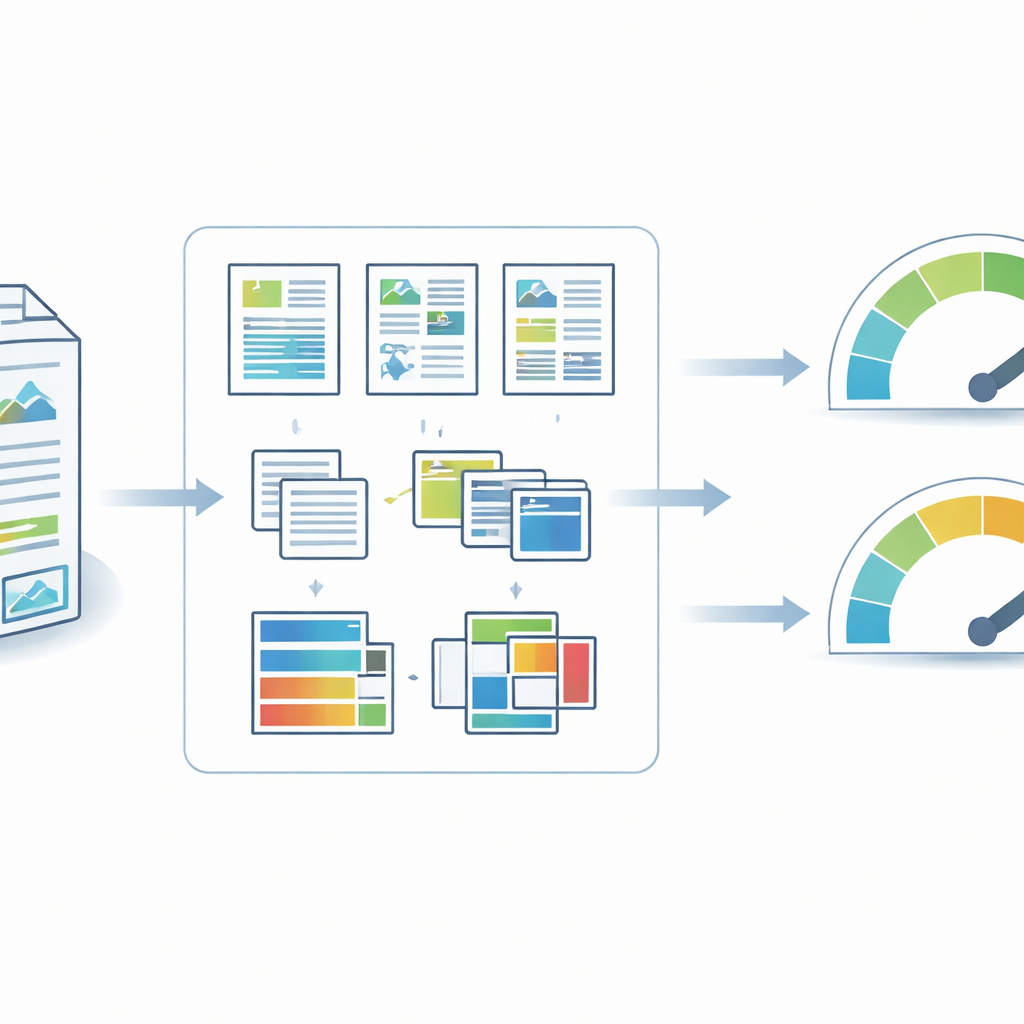
От груды отчетов к упорядоченным визуальным данным
Авторы собрали отчеты по устойчивому развитию китайских компаний, котирующихся на Шанхайской и Шэньчжэньской фондовых биржах, используя CNINFO — официальную платформу раскрытия страны. Покрывая финансовые годы с 2006 по 2024, коллекция отражает, как нефинансовая отчетность в Китае выросла от редкости до повсеместной практики, особенно после того, как новые правила бирж стимулировали компании сообщать о социальных и экологических вопросах. Все документы были загружены в исходном формате PDF, чтобы сохранить их визуальную верстку. Автоматический скрипт на Python отфильтровал поврежденные файлы, извлек базовую информацию, такую как код акций и год, и организовал отчеты в стандартизированную файловую структуру, чтобы каждый файл можно было однозначно и надежно отслеживать во времени.
Разбиение страниц на текст, изображения и цвет
Чтобы анализировать визуальные элементы в масштабе, команда конвертировала каждую страницу отчета в изображение высокого разрешения и затем использовала современные инструменты компьютерного зрения, чтобы разбить эти страницы на значимые части. Модель анализа верстки определяла, где на каждой странице находятся текстовые блоки, изображения, таблицы, заголовки и другие элементы. Текстовые области подвергались оптическому распознаванию символов (OCR), которое не только читало слова, но и измеряло такие характеристики, как межстрочный интервал, размер шрифта относительно страницы и количество слов в строке и на странице. Области с изображениями классифицировались как «абстрактные» (например, диаграммы или иконки) или «реалистичные» (например, фотографии), что позволяло выяснить, делает ли компания упор на визуализацию данных или на эмоциональное рассказание с помощью фото. В то же время процедура цветового анализа сканировала каждый пиксель, сортируя его по нескольким базовым категориям цветов и вычисляя, какую долю страницы занимает каждый цвет.
Превращение визуального стиля в числа
Из этих строительных блоков исследователи определили 18 детализированных показателей того, как каждая страница и каждый отчет используют текст, изображения и цвет — от доли площади, занятой изображениями, до баланса теплых и холодных тонов. Затем они объединили эти показатели в два ключевых индекса. Индекс информационной энтропии измеряет визуальную сложность, оценивая разнообразие цветовой палитры: страницы, которые используют много разных цветов в похожих пропорциях, получают высокие значения, тогда как простые, почти монохромные страницы получают низкие. Индекс корреляции признаков фиксирует, насколько визуально согласован отчет от страницы к странице, вычисляя, насколько похожи страницы друг на друга в этом 18‑мерном пространстве признаков. Низкие значения означают, что страницы следуют устойчивому визуальному стилю; высокие — что дизайн меняется значительно в разных частях документа.
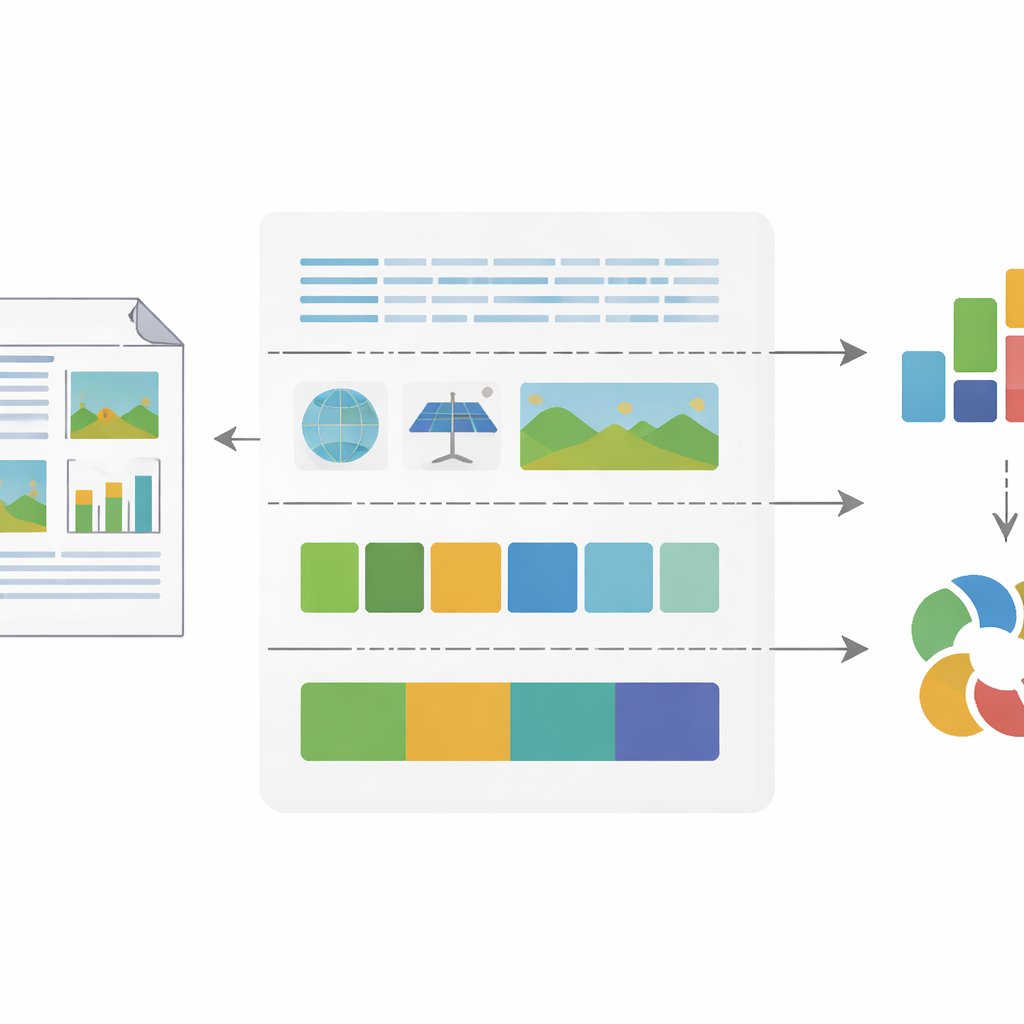
Проверка соответствия цифр человеческим впечатлениям
Поскольку ценность любого индекса зависит от того, отражает ли он то, что люди действительно видят, команда тщательно валиировала свои измерения. Они тонко настроили и протестировали модели компьютерного зрения на тысячах вручную размеченных страниц и изображений, добившись высокой точности в идентификации элементов верстки, чтении текста и различении абстрактных диаграмм и реалистичных фотографий. Чтобы проверить сами индексы, они сопоставили значения NFIVI с оценками экспертов‑людей и нескольких систем ИИ, которым поручили судить о том, насколько сложными и согласованными выглядят разные отчеты. Сильные корреляции показали, что более высокие значения энтропии действительно соответствуют более насыщенным, красочным макетам, тогда как более низкие значения корреляции признаков совпадают с отчетами, которые человеческому глазу кажутся визуально стабильными и единообразными.
Что это значит для читателей и надсмотрщиков
В повседневном смысле эта работа создает своего рода «визуальный отпечаток» для тысяч корпоративных отчетов по устойчивому развитию. Она позволяет исследователям задавать вопросы, например: зависят ли компании с плохими экологическими показателями больше от ярких цветов и глянцевых изображений, или более сдержанные дизайны сопровождают более заслуживающие доверия раскрытия. Регуляторы и контрольные организации могли бы использовать эти инструменты, чтобы выявлять потенциально вводящие в заблуждение оформления или отслеживать, как меняются стили отчетности после введения новых правил. Превращая макеты страниц, выбор изображений и цветовые схемы в прозрачные метрики, набор данных делает возможным изучать не только то, что компании говорят, но и то, как они решают это показывать.
Цитирование: Li, B., Xia, B., Cheng, Z. et al. A multi-level visual representation dataset for large-scale non-financial information disclosure. Sci Data 13, 500 (2026). https://doi.org/10.1038/s41597-026-06848-6
Ключевые слова: отчетность по устойчивому развитию, визуальная коммуникация, корпоративное раскрытие, аудит, основанный на данных, экологическое и социальное управление