Clear Sky Science · sv
Lära sig jordskredets markrörelser via konditionell generativ modellering
Varför framtida skakningar spelar roll
Jordbävningar är en ofrånkomlig del av livet i många regioner, från San Francisco Bay Area till Japan. Det som verkligen hotar människor och byggnader är inte själva jordbävningen utan den markskakning den skapar vid ytan. Ingenjörer och planerare behöver realistiska scenarier för hur kraftigt marken kan röra sig på många platser, inte bara där sensorer redan finns. Dagens metoder förlitar sig antingen på förenklad statistik som missar lokala detaljer, eller på tyngre fysiksimuleringar som kräver superdatorer och detaljerad kunskap om jordens inre. Denna studie introducerar en ny artificiell intelligens (AI)-metod som lär sig av tidigare skakningar för att snabbt föreställa sig hur framtida jordbävningar kan skaka en hel region.
Ett nytt sätt att föreställa sig skakningarna
Forskarna presenterar en modell de kallar Conditional Generative Modeling for Ground Motion (CGM-GM). Istället för att direkt lösa vågfysikens ekvationer lär sig CGM-GM mönster från tusentals inspelade små jordbävningar kring Hayward- och San Andreas-falterna i San Francisco Bay Area. Den centrala idén är ”konditionell” generering: AI:n får grundläggande information om ett händelseförlopp—dess magnitud, djup och var jordbävningen och sensorerna ligger på kartan—och genererar sedan möjliga tidserier av markrörelser som är förenliga med dessa villkor. I praktiken fungerar modellen som en smart simulator som kan fylla i hur skakningar kan se ut på platser och för jordbävningar som aldrig har registrerats.
Lyssna på jordbävningar i tid och färg
För att lära AI:n omvandlar teamet först varje inspelad skakningssignal till en slags färgbild kallad spektrogram, som visar hur styrkan hos olika frekvenser förändras över tid. De använder ett verktyg känt som Short-Time Fourier Transform för att separera varje vågform i amplitud (hur stark) och fas (när egenskaper inträffar). En särskild typ av neuralt nätverk, en dynamisk variational autoencoder, lär sig komprimera dessa amplitudspektrogram till en sekvens av dolda variabler och sedan rekonstruera dem. En kompletterande modul använder geografiska koordinater och jordbävningsegenskaper för att påverka denna dolda sekvens, så att modellen naturligt associerar mönster i skakningarna med hur vågorna färdas och hur stor jordbävningen är. Vid generering drar modellen nya dolda sekvenser, rekonstruerar amplitudspektrogram, uppskattar fas och omvandlar allt tillbaka till syntetiska vågformer.
Fyller i kartan mellan glest placerade sensorer
När CGM-GM väl är tränad kan den frågas: ”Om en jordbävning av en viss storlek och plats inträffar, vilken skakning kan vi då se över ett tätt rutnät av punkter?” Författarna testar detta genom att generera tiotusen syntetiska registreringar över en delregion av Bay Area och sedan beräkna Fourier-amplitudspektran (ett mått på frekvensberoende skakningsstyrka) vid varje punkt. De resulterande kartorna visar jämna, realistiska variationer: skakningar tenderar att avta med avstånd från källan, förändras med riktning och bli starkare i områden kända för mjuka jordlager, såsom nära San Jose och San Francisco Bay-myllor. Viktigt är att de rumsliga mönstren ser mycket mer realistiska ut än en enklare referens-AI som endast känner till avstånd och djup, och att de liknar mönster från en avancerad icke-ergodisk empirisk markrörelsemodell framtagen av seismologer.
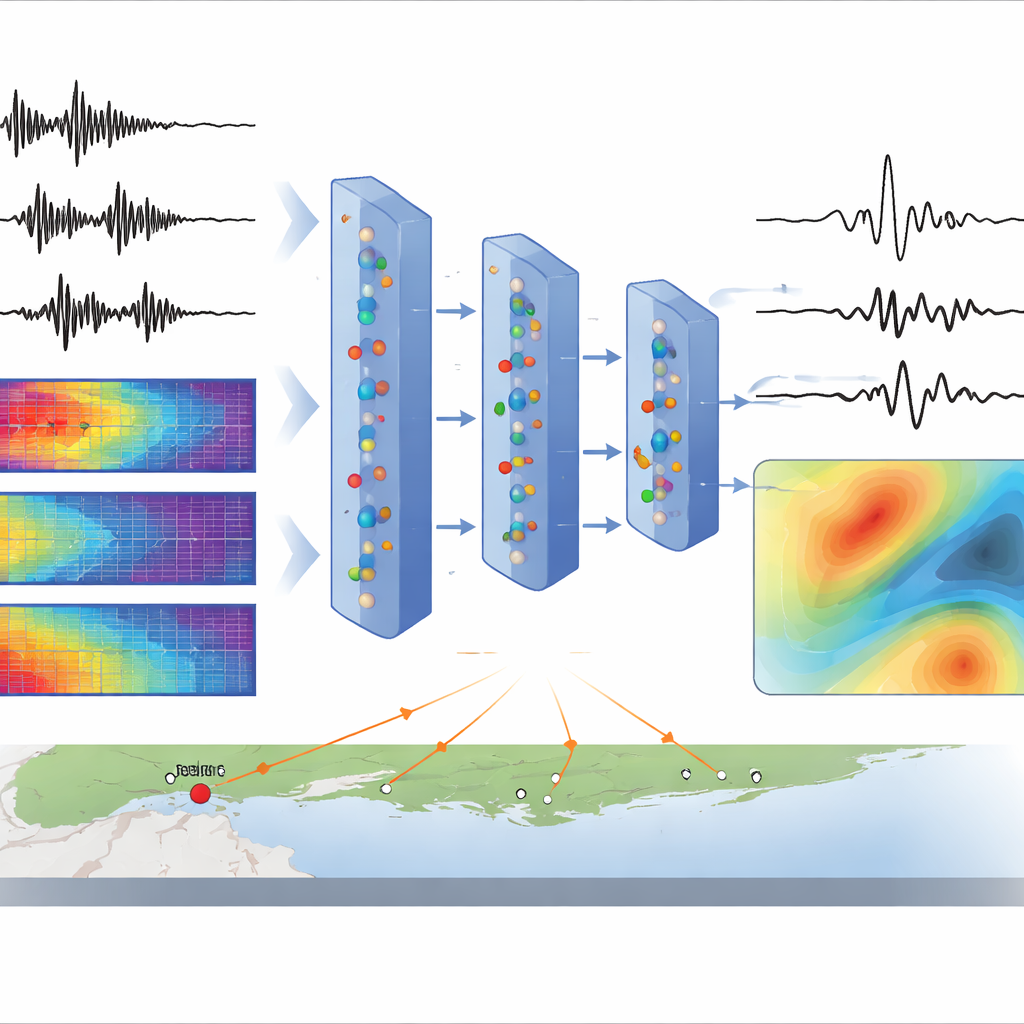
Matchar verkliga data i både form och styrka
Teamet jämför AI:ns output med riktiga inspelningar på flera sätt. I frekvensdomänen överensstämmer de syntetiska amplitudspektra väl med observationer från 2 till 15 hertz, det intervall som är viktigast för många byggnader. I tidsdomänen återger de genererade vågformerna inte bara övergripande former utan också toppmarkhastigheter och ankomsttider för P- och S-vågor, som bestämts av en oberoende plockningsalgoritm. Modellen kan också producera många något olika versioner av skakningarna för samma scenario och fånga jordbävningars naturliga slumpmässighet. Det finns begränsningar: mycket låga och mycket höga frekvenser är svårare att matcha perfekt, skakningarnas varaktigheter för de minsta händelserna visar större spridning, och skalning till mycket stora jordbävningar förblir utmanande utan ytterligare träningsdata.
Vad detta betyder för människor och byggnader
För icke-specialister är slutsatsen att detta AI-ramverk snabbt kan generera realistiska, fysikmedvetna scenarier för jordbävningsskakningar över en hel stadsregion, även där inga sensorer är installerade och utan att köra dyra superdatorsimuleringar. CGM-GM ersätter inte detaljerade fysikbaserade modeller eller noggrant kalibrerade empiriska ekvationer, men det presterar jämförbart med toppmoderna metoder samtidigt som det är flexibelt och snabbt. Med vidare förfining och mer data kan sådana generativa modeller bli praktiska verktyg för att utforska ”tänk om”-jordbävningar, förbättra riskkartor och hjälpa ingenjörer att utforma byggnader och infrastruktur som är bättre förberedda för nästa stora skakning.
Citering: Ren, P., Nakata, R., Lacour, M. et al. Learning earthquake ground motions via conditional generative modeling. Nat Commun 17, 4021 (2026). https://doi.org/10.1038/s41467-026-70719-2
Nyckelord: jordbävningsmarkrörelse, generativ AI, seismisk risk, San Francisco Bay Area, variationsautoenkodare