Clear Sky Science · de
Lernen von Erdbeben-Bodenbewegungen durch konditionelles generatives Modellieren
Warum das Bodenbeben künftiger Erdbeben wichtig ist
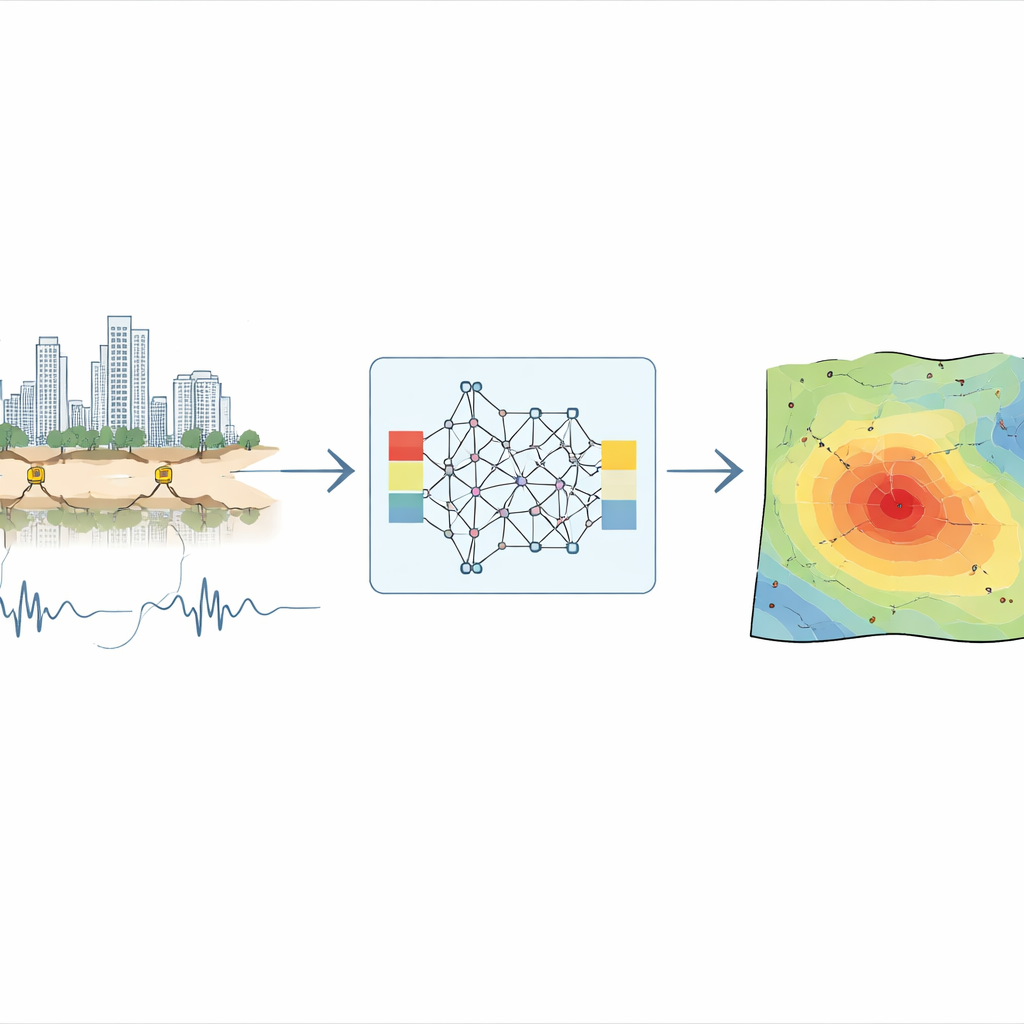
Erdbeben sind in vielen Regionen, von der San Francisco Bay Area bis nach Japan, unvermeidlich. Gefährlich für Menschen und Gebäude ist weniger das eigentliche Erdbeben als die Bodenerschütterung an der Oberfläche. Planer und Ingenieure benötigen realistische Szenarien dafür, wie stark sich der Untergrund an vielen Orten bewegen könnte, nicht nur dort, wo bereits Messstationen stehen. Die heutigen Methoden stützen sich jedoch entweder auf vereinfachte Statistiken, die lokale Details übersehen, oder auf aufwendige physikalische Simulationen, die Supercomputer und detaillierte Kenntnis des Erdinneren erfordern. Diese Studie stellt einen neuen Ansatz mit künstlicher Intelligenz (KI) vor, der aus früheren Aufzeichnungen lernt, um schnell vorstellbare Varianten davon zu erzeugen, wie zukünftige Erdbeben eine ganze Region erschüttern könnten.
Eine neue Art, sich das Beben vorzustellen
Die Forscher stellen ein Modell vor, das sie Conditional Generative Modeling for Ground Motion (CGM-GM) nennen. Anstatt die Wellengleichungen der Physik direkt zu lösen, lernt CGM-GM Muster aus tausenden aufgezeichneter kleiner Erdbeben entlang der Hayward- und San-Andreas-Verwerfungen in der San Francisco Bay Area. Der zentrale Gedanke ist die „konditionierte“ Erzeugung: Die KI erhält Basisinformationen über ein Ereignis—Magnituden, Tiefe und die Lage von Erdbeben und Sensoren auf der Karte—und erzeugt dann mögliche Bodengeschwindigkeits-Zeitreihen, die mit diesen Bedingungen vereinbar sind. Effektiv wirkt das Modell wie ein intelligenter Simulator, der ausfüllen kann, wie das Beben an Orten und für Erdbeben aussehen könnte, die nie gemessen wurden.
Quakes in Zeit und Farbe anhören
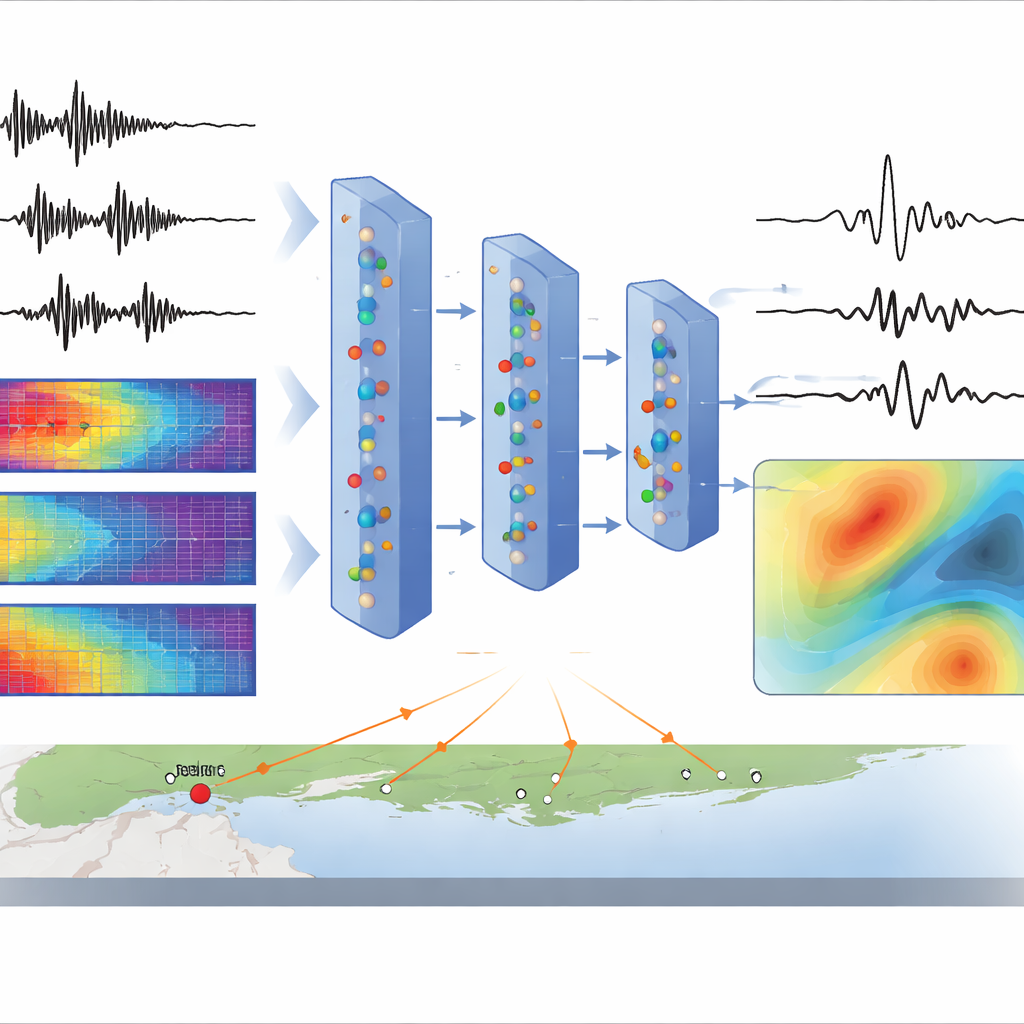
Um die KI zu trainieren, wandelt das Team zunächst jedes aufgezeichnete Signal in eine Art farbiges Bild um, ein Spektrogramm, das zeigt, wie sich die Stärke verschiedener Frequenzen über die Zeit ändert. Sie verwenden die Short-Time Fourier Transform, um jede Wellenform in Amplitude (wie stark) und Phase (wann Merkmale auftreten) zu zerlegen. Ein spezieller Typ neuronaler Netzwerke, ein dynamischer variationaler Autoencoder, lernt, diese Amplitudenspektrogramme in eine Folge verborgener Variablen zu komprimieren und anschließend zu rekonstruieren. Ein Begleitmodul nutzt geographische Koordinaten und Erdbebenparameter, um diese verborgene Sequenz zu beeinflussen, sodass das Modell Muster der Bodenerschütterung natürlich mit den Ausbreitungswegen der Wellen und der Größe des Bebens verknüpft. Bei der Generierung zieht das Modell neue verborgene Sequenzen, rekonstruiert Amplitudenspektrogramme, schätzt Phasen und wandelt alles zurück in synthetische Wellenformen.
Die Karte zwischen wenigen Messpunkten ausfüllen
Einmal trainiert, kann CGM-GM gefragt werden: „Wenn an einem bestimmten Ort ein Erdbeben einer gegebenen Stärke auftritt, welche Bodenbewegungen könnten wir über ein dichtes Gitter von Punkten beobachten?“ Die Autorinnen und Autoren prüfen dies, indem sie zehntausend synthetische Aufzeichnungen über eine Teilregion der Bay Area erzeugen und dann an jedem Punkt Fourier-Amplitudenspektren (ein Maß für frequenzabhängige Schüttstärke) berechnen. Die resultierenden Karten zeigen glatte, realistische Variationen: Die Erschütterung nimmt mit größerer Entfernung von der Quelle ab, ändert sich mit Richtung und wird in Gebieten mit weichen Böden, etwa in der Nähe von San Jose und den Schlammbereichen der San Francisco Bay, stärker. Wichtig ist, dass die räumlichen Muster deutlich realistischer wirken als bei einem einfacheren Basismodell der KI, das nur Entfernung und Tiefe kennt, und Ähnlichkeit mit einem fortgeschrittenen nicht-ergodischen empirischen Bodenbewegungsmodell aufweisen, das von Seismologen erstellt wurde.
Form und Stärke realer Daten annähernd treffen
Das Team vergleicht die Ausgaben der KI auf verschiedene Weise mit realen Aufzeichnungen. Im Frequenzbereich stimmen die synthetischen Amplitudenspektren gut mit Beobachtungen von 2 bis 15 Hertz überein, dem Bereich, der für viele Gebäude am wichtigsten ist. Im Zeitbereich reproduzieren die generierten Wellenformen nicht nur die Gesamtformen, sondern auch Spitzenboden-Geschwindigkeiten und die Ankunftszeiten von P- und S-Wellen, wie sie von einem unabhängigen Picking-Algorithmus bestimmt wurden. Das Modell kann außerdem für dasselbe Szenario viele leicht unterschiedliche Versionen der Erschütterung erzeugen und damit die natürliche Zufälligkeit von Erdbeben abbilden. Es gibt Einschränkungen: Sehr niedrige und sehr hohe Frequenzen sind schwerer perfekt nachzubilden, die Dauern der Erschütterungen bei den kleinsten Ereignissen zeigen größere Streuung, und die Skalierung auf sehr große Beben bleibt ohne zusätzliche Trainingsdaten herausfordernd.
Was das für Menschen und Gebäude bedeutet
Für Nicht-Spezialisten lässt sich zusammenfassen: Dieses KI-Framework kann rasch realistische, physikbewusste Szenarien von Erdbeben-Bodenerschütterungen für eine ganze urbane Region erzeugen, selbst an Orten ohne Sensoren und ohne teure Supercomputer-Simulationen durchzuführen. CGM-GM ersetzt nicht detaillierte physikbasierte Modelle oder sorgfältig kalibrierte empirische Gleichungen, liefert aber vergleichbare Leistungen zu modernen Methoden und ist dabei flexibel und schnell. Mit weiterer Verfeinerung und mehr Daten könnten solche generativen Modelle praktikable Werkzeuge werden, um „Was-wäre-wenn“-Erdbeben zu untersuchen, Gefährdungskarten zu verbessern und Ingenieurinnen und Ingenieure dabei zu helfen, Gebäude und Infrastruktur besser für das nächste große Beben vorzubereiten.
Zitation: Ren, P., Nakata, R., Lacour, M. et al. Learning earthquake ground motions via conditional generative modeling. Nat Commun 17, 4021 (2026). https://doi.org/10.1038/s41467-026-70719-2
Schlüsselwörter: Erdbeben-Bodenbewegung, generative KI, seismische Gefährdung, San Francisco Bay Area, variationaler Autoencoder