Clear Sky Science · nl
Leren van aardbevingsgrondbewegingen via conditionele generatieve modellering
Waarom het schudden van toekomstige aardbevingen ertoe doet
Aardbevingen zijn een onvermijdelijk onderdeel van het leven in veel regio’s, van de San Francisco Bay Area tot Japan. Wat mensen en gebouwen echt bedreigt is niet de beving zelf, maar het schudden dat aan het aardoppervlak optreedt. Ingenieurs en planners hebben realistische scenario’s nodig van hoe heftig de grond op veel locaties kan bewegen, niet alleen waar al sensoren staan. De huidige methoden vertrouwen echter óf op vereenvoudigde statistieken die lokale details missen, óf op zware fysische simulaties die supercomputers en gedetailleerde kennis van de aarde vereisen. Deze studie introduceert een nieuwe kunstmatige-intelligentie (AI) benadering die leert van eerder schudden om snel voor te stellen hoe toekomstige aardbevingen een hele regio kunnen doen beven.
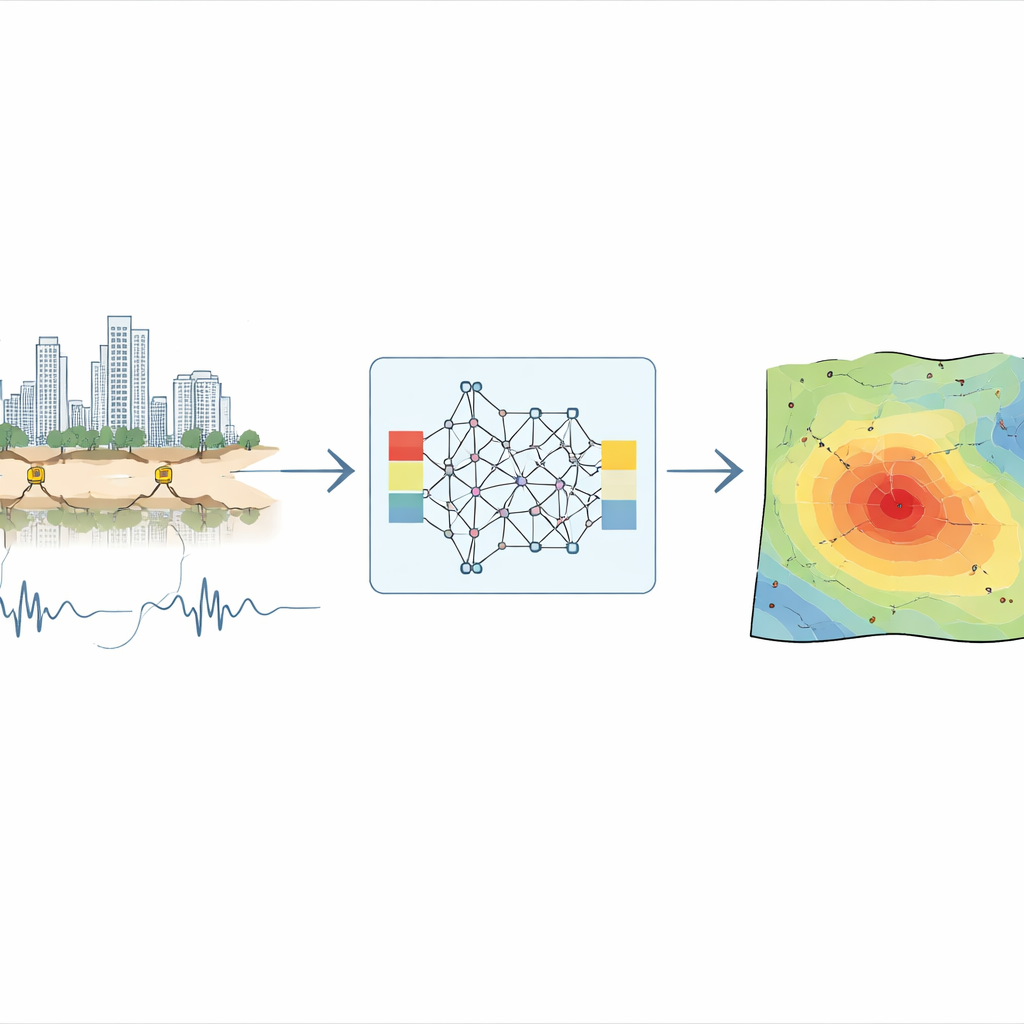
Een nieuwe manier om het schudden voor te stellen
De onderzoekers presenteren een model dat zij Conditional Generative Modeling for Ground Motion (CGM-GM) noemen. In plaats van direct de golfbewegingsvergelijkingen op te lossen, leert CGM-GM patronen uit duizenden opgenomen kleine aardbevingen rondom de Hayward- en San Andreasbreuken in de San Francisco Bay Area. Het kernidee is “conditionele” generatie: de AI krijgt basisinformatie over een gebeurtenis—de magnitude, diepte en waar de aardbeving en sensoren op de kaart liggen—en genereert vervolgens mogelijke tijdreeksen van grondbeweging die consistent zijn met die condities. In feite fungeert het model als een slimme simulator die kan invullen hoe het schudden eruit zou kunnen zien op locaties en voor aardbevingen die nooit zijn opgenomen.
Luisteren naar bevingen in tijd en kleur
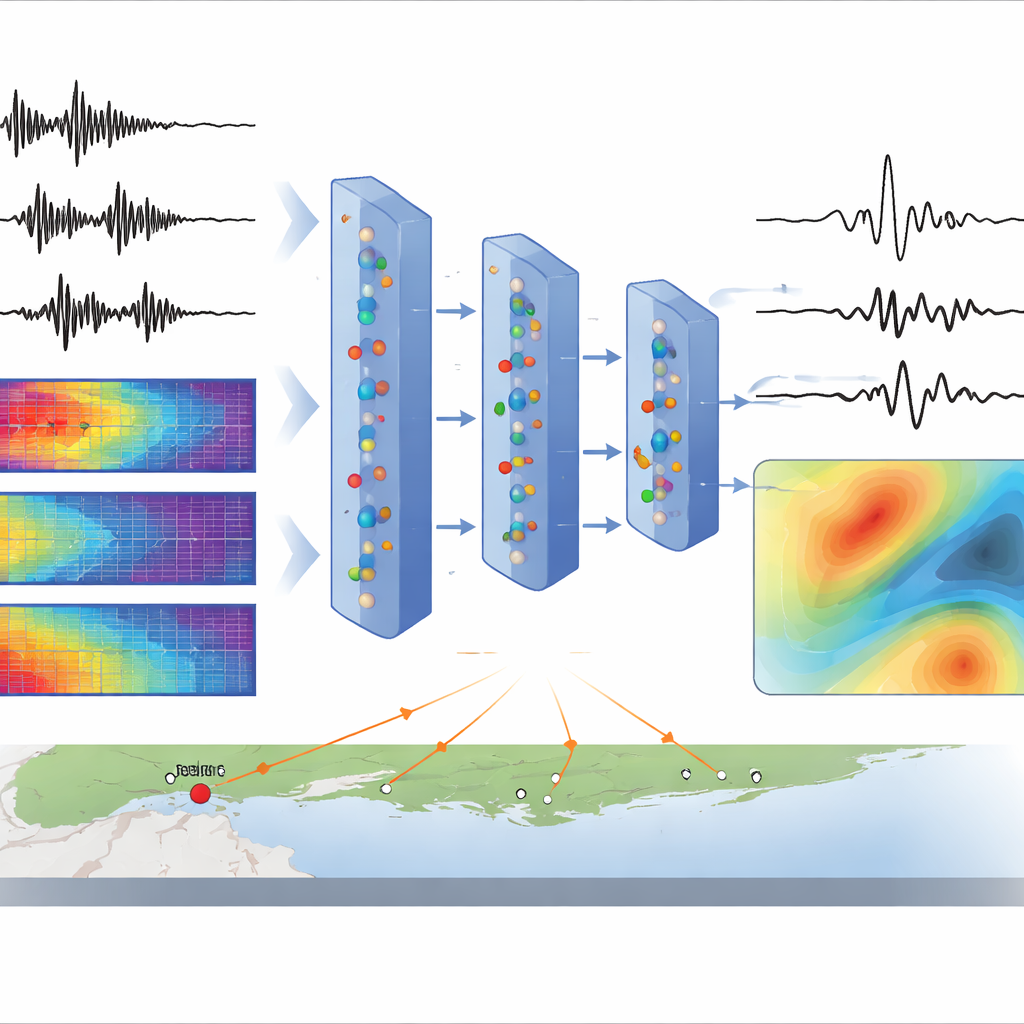
Om de AI te trainen zet het team eerst elk opgenomen schudsignaal om in een soort gekleurd plaatje, een spectrogram, dat laat zien hoe de sterkte van verschillende frequenties in de loop van de tijd verandert. Ze gebruiken een hulpmiddel dat bekendstaat als de Short-Time Fourier Transform om elke golfvorm te scheiden in amplitude (hoe sterk) en fase (wanneer kenmerken optreden). Een speciaal type neuraal netwerk, een dynamische variational autoencoder, leert deze amplitudespectrogrammen samen te vatten in een reeks verborgen variabelen en ze daarna te reconstrueren. Een begeleidend module gebruikt geografische coördinaten en aardbevingskenmerken om deze verborgen sequentie te beïnvloeden, zodat het model op natuurlijke wijze schudpatronen koppelt aan waar de golven reizen en hoe groot de beving is. Tijdens generatie trekt het model nieuwe verborgen sequenties, reconstrueert amplitudespectrogrammen, schat fase en zet alles terug om in synthetische golfvormen.
De kaart invullen tussen sparsely geplaatste sensoren
Eenmaal getraind kan CGM-GM de vraag beantwoorden: “Als een aardbeving van een bepaalde grootte en locatie plaatsvindt, welk schudden zouden we dan zien over een dicht raster van punten?” De auteurs testen dit door tienduizend synthetische registraties te genereren over een subregio van de Bay Area en vervolgens Fourrier-amplitudespectra (een maat voor frequentieafhankelijke schuddingsterkte) te berekenen op elk punt. De resulterende kaarten tonen vloeiende, realistische variaties: het schudden neemt doorgaans af met afstand vanaf de bron, verandert met richting en wordt sterker in gebieden waarvan bekend is dat ze zachte bodems hebben, zoals nabij San Jose en de moddergebieden van de San Francisco Bay. Belangrijk is dat de ruimtelijke patronen veel realistischer ogen dan die van een eenvoudiger baseline-AI-model dat alleen afstand en diepte kent, en dat ze lijken op die van een geavanceerd niet-ergodisch empirisch grondbewegingsmodel dat door seismologen is ontwikkeld.
Overeenkomen met echte data in zowel vorm als sterkte
Het team controleert de AI-uitvoer op meerdere manieren tegen echte opnamen. In het frequentiedomein komen de synthetische amplitudespectra goed overeen met waarnemingen van 2 tot 15 hertz, het bereik dat voor veel gebouwen het belangrijkst is. In het tijdsdomein reproduceren de gegenereerde golfvormen niet alleen de algemene vormen maar ook pieksnelheden van de grond en de aankomsttijden van P- en S-golven, zoals bepaald door een onafhankelijke pick-algoritme. Het model kan ook veel licht verschillende varianten van schudgedrag voor hetzelfde scenario produceren, waarmee het de natuurlijke willekeur van aardbevingen vastlegt. Er zijn beperkingen: zeer lage en zeer hoge frequenties zijn moeilijker perfect te matchen, de duur van het schudden bij de kleinste gebeurtenissen vertoont meer spreiding, en opschaling naar zeer grote bevingen blijft uitdagend zonder extra trainingsdata.
Wat dit betekent voor mensen en gebouwen
Voor niet-specialisten is de kernboodschap dat dit AI-kader snel realistische, fysica-bewuste aardbevingsschudscenario’s kan genereren voor een hele stedelijke regio, zelfs waar geen sensoren zijn geïnstalleerd en zonder het draaien van dure supercomputersimulaties. CGM-GM vervangt geen gedetailleerde fysica-gebaseerde modellen of zorgvuldig gekalibreerde empirische vergelijkingen, maar het presteert vergelijkbaar met state-of-the-art methoden terwijl het flexibel en snel is. Met verdere verfijning en meer data kunnen zulke generatieve modellen praktische hulpmiddelen worden om “wat-als” aardbevingen te verkennen, hazard-kaarten te verbeteren en ingenieurs te helpen gebouwen en infrastructuur te ontwerpen die beter bestand zijn tegen de volgende grote schok.
Bronvermelding: Ren, P., Nakata, R., Lacour, M. et al. Learning earthquake ground motions via conditional generative modeling. Nat Commun 17, 4021 (2026). https://doi.org/10.1038/s41467-026-70719-2
Trefwoorden: aardbevingsgrondbeweging, generatieve AI, seismisch risico, San Francisco Bay Area, variational autoencoder