Clear Sky Science · ru
CancerLLM: большая языковая модель в области онкологии
Почему это важно для пациентов и врачей
Онкологическая помощь требует обработки огромного объёма текстовой информации — от заметок врачей до лабораторных заключений. Большинство систем искусственного интеллекта, читающих такие тексты, являются универсальными, а не специализированными на раке; они часто большие, дорогие и требуют значительных ресурсов для работы в клиниках. В этой статье представлен CancerLLM — более компактная языковая модель, обученная специально на онкологических записях, которая обещает более точную помощь в понимании состояния пациента при существенно меньших вычислительных затратах.
Новый цифровой помощник, ориентированный на онкологию
Исследователи стремились создать модель, которая «думает» на языке онкологии. Вместо сбора данных из открытого интернета они обучали CancerLLM на 2,7 миллионах клинических заметок по онкологии и более чем полумиллионе патологоанатомических отчётов от более чем 30 000 пациентов по 17 типам рака, включая рак груди, лёгкого, колоректальный рак и лейкемии. В качестве отправной точки использовали архитектуру модели с 7 миллиардами параметров, затем продолжили обучение на этом богатом онкологическом материале, после чего провели вторую фазу обучения, где модель учили выполнять инструкционные задачи, похожие на запросы врача к цифровому помощнику.
Помощь в извлечении ключевых деталей из сложных отчётов
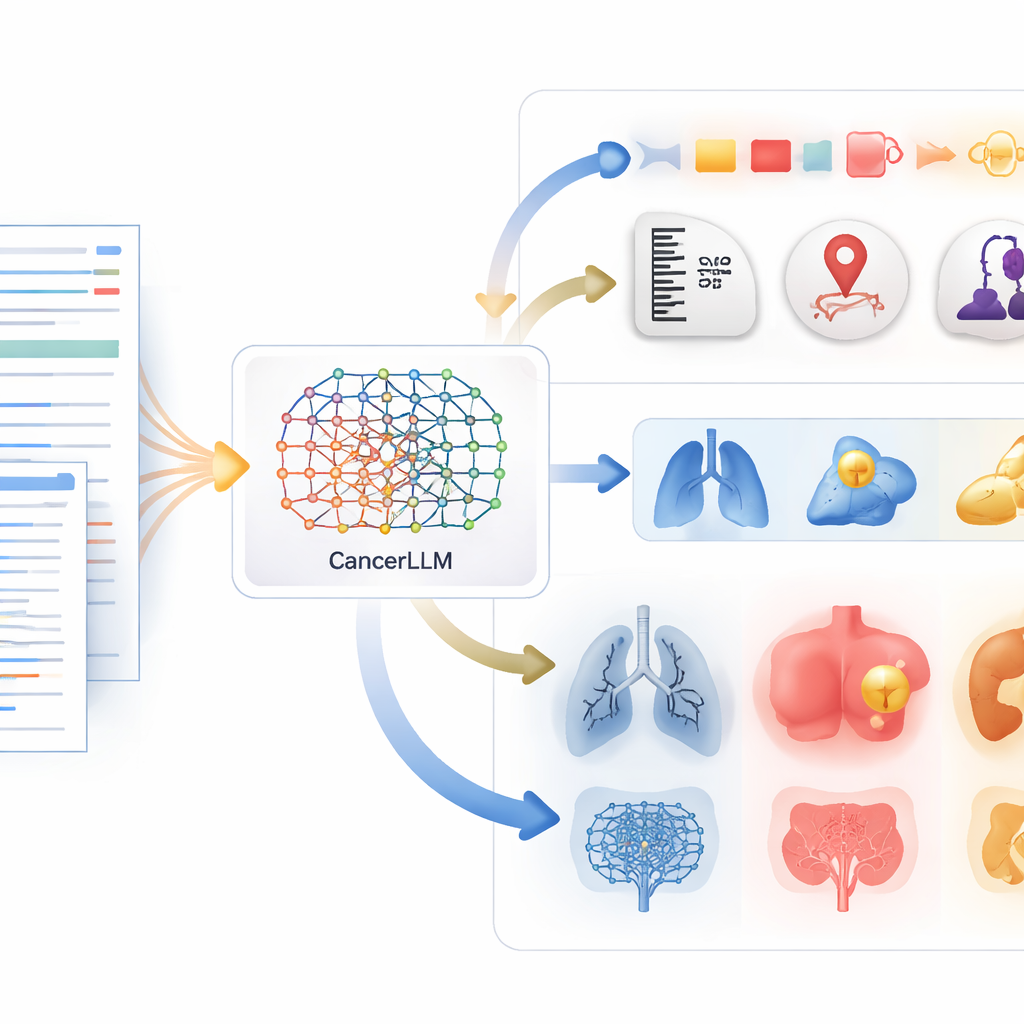
Одна из основных задач CancerLLM — «извлечение фенотипов»: выделение конкретных онкологических характеристик из свободного текста отчётов. Эти характеристики включают локализацию опухоли, её размер, степень дифференцировки и стадию, а также статус гормональных рецепторов, определяющих лечение. Традиционные системы решают это как задачу покомпонентной разметки токенов, тогда как авторы превратили её в задачу вопрос‑ответ. Для каждого предложения отчёта модельу задают простые вопросы типа «Каков размер опухоли?» или «Какая стадия рака?» и она должна ответить соответствующей фразой или указать, что вопрос не релевантен. На этой задаче CancerLLM сравнялся или превзошёл многие более крупные универсальные медицинские модели, показывая очень высокую точность при компактных размерах, пригодных для клинического использования.
От разрозненных заметок к ясному диагнозу
Вторая ключевая задача — генерация диагноза. Модель получает реалистичный фрагмент визита при онкологическом приёме: причины обращения, место поражения, симптомы, наблюдения медсестры, данные осмотра и результаты обследований. Затем ей нужно выдать правильный диагноз, например рак лёгкого или неходжкинская лимфома. По большому бенчмарку CancerLLM существенно опередил известные медицинские модели с параметрами в десятки раз больше, повысив комбинированную точность в среднем более чем на девять процентных пунктов. В отдельном тесте на независимой выборке из 2000 пациентов, которых модель никогда прежде «не видела», CancerLLM снова оказался лучшим, что говорит о способности обобщать на новых пациентах, а не просто запоминать предыдущие случаи.
Проверка устойчивости на «грязных» реальных данных
Реальные клинические записи редко бывают идеальными: в них встречаются опечатки, аббревиатуры и даже ошибки в разметке. Команда создала две специальные тестовые среды, чтобы оценить, насколько модель хрупка или устойчива к таким помехам. В одной среде они намеренно добавляли неверные ответы в тренировочные данные, имитируя ошибки разметки, и обнаружили, что CancerLLM держится не хуже или лучше сопоставимых моделей, особенно при высоком уровне ошибок. В другой среде они вводили орфографические ошибки, например «cnacer» вместо «cancer», с разной частотой. И CancerLLM, и сильная сравнительная модель показали падение производительности по мере увеличения ошибок, подчёркивая, что даже продвинутый ИИ чувствителен к «грязному» тексту, и что аккуратный ввод данных и предобработка по‑прежнему критичны.
Скорость, эффективность и текущие ограничения
Поскольку аппаратные бюджеты в больницах ограничены, исследователи также сравнили время вычислений и использование памяти. Очень большие модели на 70 миллиардов параметров могли в некоторых задачах извлечения выдавать чуть лучшую производительность, но требовали в несколько раз больше памяти и значительно больше времени на обработку. CancerLLM, напротив, обеспечивал ведущую или близкую к ведущей точность как для задач извлечения, так и для постановки диагноза, работая на одной высокопроизводительной видеокарте с умеренными требованиями к памяти. Анализ ошибок показал, что модель всё ещё испытывает трудности с очень тонкими различиями, такими как редкие подтипы рака, полные детали стадирования и активное использование сокращений или опечаток в записях, что указывает на области для улучшения через дополнительную очистку данных и дальнейшую доработку модели.
Что это значит для будущего ИИ в онкологии
Проще говоря, CancerLLM — это компактный, ориентированный на онкологию «чтец» медицинских текстов, который способен быстро выделять критичные детали из медицинских записей и предлагать вероятные онкологические диагнозы, оставаясь реалистичным для применения в больницах. Он не заменяет онкологов, но может сэкономить им время, поддержать научные исследования и снизить число пропущенных деталей в сложных картах пациентов. Публикуя как саму модельную платформу, так и синтетические наборы данных, авторы стремятся стимулировать дальнейшую работу над надежными и эффективными ИИ‑инструментами, настроенными на конкретные медицинские домены, а не универсальные решения для всех случаев.
Цитирование: Li, M., Zhan, Z., Huang, J. et al. CancerLLM: a large language model in cancer domain. npj Digit. Med. 9, 266 (2026). https://doi.org/10.1038/s41746-026-02441-8
Ключевые слова: ИИ для рака, клнический текстовый майнинг, поддержка диагноза, медицинские языковые модели, информатика онкологии