Clear Sky Science · pl
CancerLLM: duży model językowy w dziedzinie onkologii
Dlaczego to ma znaczenie dla pacjentów i lekarzy
Opieka onkologiczna zależy od zrozumienia ogromnych ilości tekstu — od notatek lekarzy po wyniki badań laboratoryjnych. Większość systemów sztucznej inteligencji czytających te teksty to rozwiązania ogólne, a nie eksperci w dziedzinie raka; często są też ogromne, kosztowne i trudne do uruchomienia w szpitalach. W artykule przedstawiono CancerLLM — mniejszy model językowy wytrenowany specjalnie na dokumentacji onkologicznej, który obiecuje bardziej precyzyjną pomoc w rozumieniu choroby pacjenta przy znacznie niższych wymaganiach obliczeniowych.
Nowy cyfrowy asystent skoncentrowany na onkologii
Badacze postawili sobie za cel zbudowanie modelu językowego, który „myśli” językiem onkologii. Zamiast czerpać dane z otwartego internetu, wytrenowali CancerLLM na 2,7 miliona klinicznych notatek dotyczących raka oraz ponad pół miliona raportów patologicznych pochodzących od ponad 30 000 pacjentów dotyczących 17 typów nowotworów, w tym piersi, płuca, jelita grubego i białaczek. Rozpoczęli od istniejącej architektury modelu o 7 miliardach parametrów, kontynuując trening na materiale bogatym w dane onkologiczne, a następnie przeprowadzili drugi etap, w którym model nauczył się wykonywać zadania w formie instrukcji podobnych do zapytań, jakie lekarz mógłby skierować do cyfrowego asystenta.
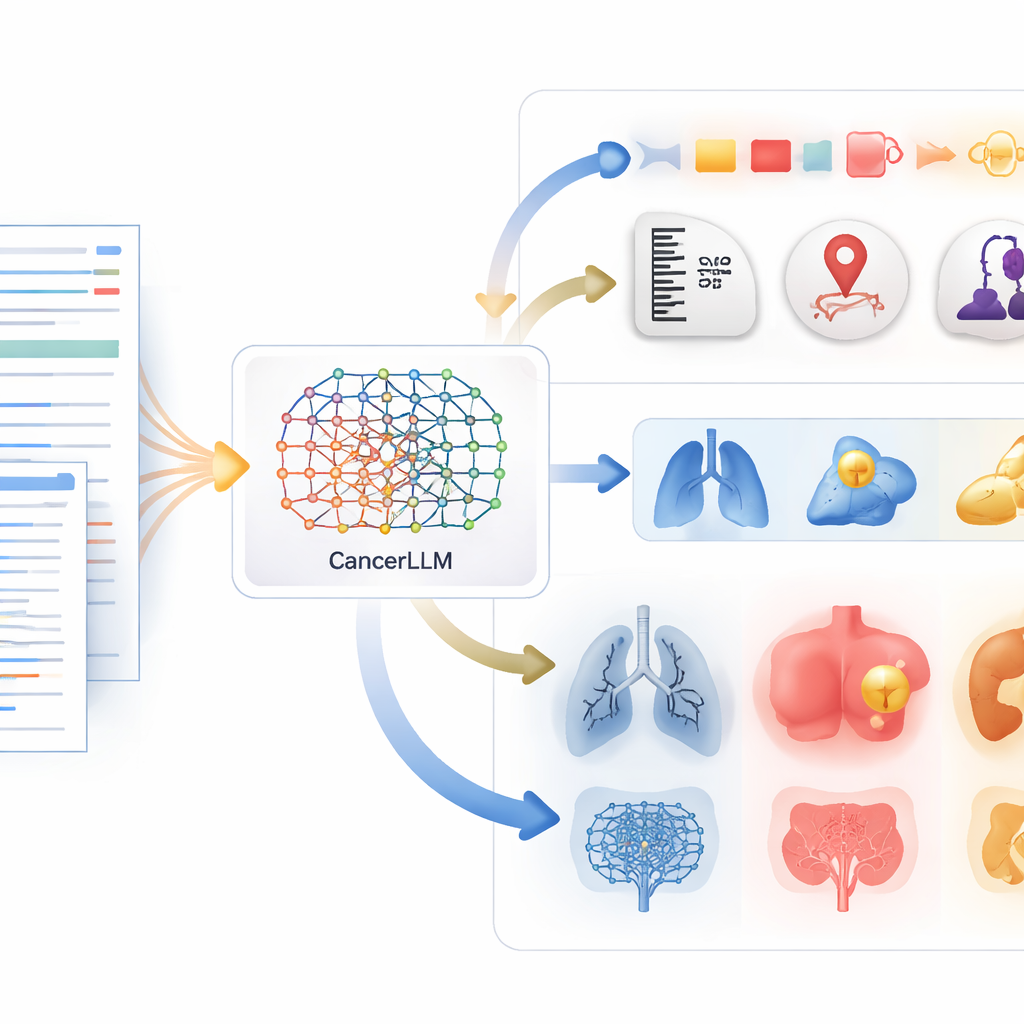
Pomoc w wydobywaniu kluczowych informacji z złożonych raportów
Jednym z głównych zadań CancerLLM jest „ekstrakcja fenotypu”: wydobywanie konkretnych cech nowotworu z tekstu wolnego. Cecha te obejmują lokalizację guza, jego wielkość, stopień i stadium oraz status receptorów hormonalnych kierujących leczeniem. Tradycyjne systemy traktują to jako problem etykietowania token po tokenie, natomiast autorzy zamienili go na zadanie pytanie–odpowiedź. Dla każdego zdania z raportu modelowi zadaje się proste pytania, takie jak „Jaki jest rozmiar guza?” czy „Jakie jest stadium choroby?” i musi on odpowiedzieć odpowiednim fragmentem lub stwierdzić, że pytanie nie ma zastosowania. W tym zadaniu CancerLLM dorównał lub przewyższył wiele większych, ogólnych modeli medycznych, osiągając bardzo wysoką dokładność przy zachowaniu kompaktowości praktycznej w użyciu klinicznym.
Od rozproszonych notatek do jasnej diagnozy
Drugim kluczowym zadaniem jest generowanie diagnozy. Model otrzymuje realistyczny wycinek wizyty onkologicznej: powody zgłoszenia się do kliniki, miejsce leczenia, objawy, obserwacje pielęgniarki, wyniki badania fizykalnego oraz wyniki badań. Następnie musi wygenerować poprawną diagnozę nowotworu, na przykład rak płuca czy chłoniak nieziarniczy. W dużym zestawie testowym CancerLLM znacznie przewyższył dobrze znane modele medyczne mające nawet dziesięć razy więcej parametrów, podnosząc łączny wynik dokładności średnio o ponad dziewięć punktów procentowych. W oddzielnym teście na niezależnej grupie 2 000 pacjentów, których nigdy wcześniej „nie widział”, CancerLLM znów osiągnął najlepsze wyniki, co sugeruje, że potrafi uogólniać na nowych pacjentów, a nie tylko zapamiętywać wcześniejsze przypadki.
Badanie odporności na chaotyczne dane z rzeczywistej praktyki
Rzeczywiste dokumenty kliniczne nie są czyste: zawierają literówki, skróty, a czasem błędy etykietowania. Zespół zbudował dwa specjalne zestawy testowe, by sprawdzić, jak kruchy lub wytrzymały jest model wobec takiego szumu. W jednym celu celowo wmieszano błędne odpowiedzi podczas treningu, by naśladować źle oznakowane dane, i stwierdzono, że CancerLLM radził sobie równie dobrze lub lepiej niż porównywalne modele, zwłaszcza przy wysokim odsetku błędów. W drugim teście wprowadzono błędy ortograficzne, np. „cnacer” zamiast „cancer”, w różnych proporcjach. Zarówno CancerLLM, jak i silny model porównawczy wykazały spadki wydajności wraz ze wzrostem liczby błędów, podkreślając, że nawet zaawansowana SI jest wrażliwa na zanieczyszczony tekst i że staranne wprowadzanie danych oraz ich wstępne przetwarzanie pozostają kluczowe.
Szybkość, efektywność i obecne ograniczenia
Ponieważ budżety sprzętowe w szpitalach są ograniczone, badacze porównali też czas obliczeń i zużycie pamięci. Duże modele o 70 miliardach parametrów mogły osiągnąć nieco lepsze wyniki w niektórych zadaniach ekstrakcji, ale wymagały wielokrotnie większej pamięci i znacznie dłuższego czasu przetwarzania. CancerLLM natomiast dostarczał wiodącą lub zbliżoną do wiodącej dokładność zarówno w ekstrakcji, jak i diagnozie, działając na jednej wysokiej klasy karcie graficznej przy umiarkowanych wymaganiach pamięciowych. Analiza błędów wykazała, że model nadal ma trudności z bardzo drobnymi rozróżnieniami, takimi jak subtelne podtypy nowotworów, pełne szczegóły dotyczące stadium czy intensywne użycie skrótów i literówek w notatkach, co wskazuje obszary, gdzie potrzebne będą dodatkowe czyszczenie danych i przyszłe ulepszenia modelu.
Co to oznacza dla przyszłości SI w onkologii
Mówiąc prosto, CancerLLM przypomina kompaktowego, znającego się na onkologii czytnika tekstu, który potrafi szybko wydestylować krytyczne informacje z dokumentacji medycznej i zasugerować prawdopodobne rozpoznania nowotworowe, jednocześnie będąc realistycznym do wdrożenia w szpitalach. Nie zastępuje on onkologów, ale może zaoszczędzić im czas, wspierać badania i zmniejszać liczbę pominiętych informacji w złożonych kartotekach. Poprzez udostępnienie zarówno ram modelu, jak i syntetycznych zestawów danych, autorzy liczą na pobudzenie dalszych prac nad zaufanymi, efektywnymi narzędziami SI dostrojonymi do konkretnych dziedzin medycyny, zamiast uniwersalnych systemów typu "one-size-fits-all".
Cytowanie: Li, M., Zhan, Z., Huang, J. et al. CancerLLM: a large language model in cancer domain. npj Digit. Med. 9, 266 (2026). https://doi.org/10.1038/s41746-026-02441-8
Słowa kluczowe: sztuczna inteligencja w onkologii, analiza tekstów klinicznych, wsparcie diagnostyczne, medyczne modele językowe, informatyka onkologiczna