Clear Sky Science · ru
Легковесная гибридная сеть внимания с мультимасштабной интеграцией признаков для интеллектуального распознавания подводных акустических целей
Слушая корабли под волнами
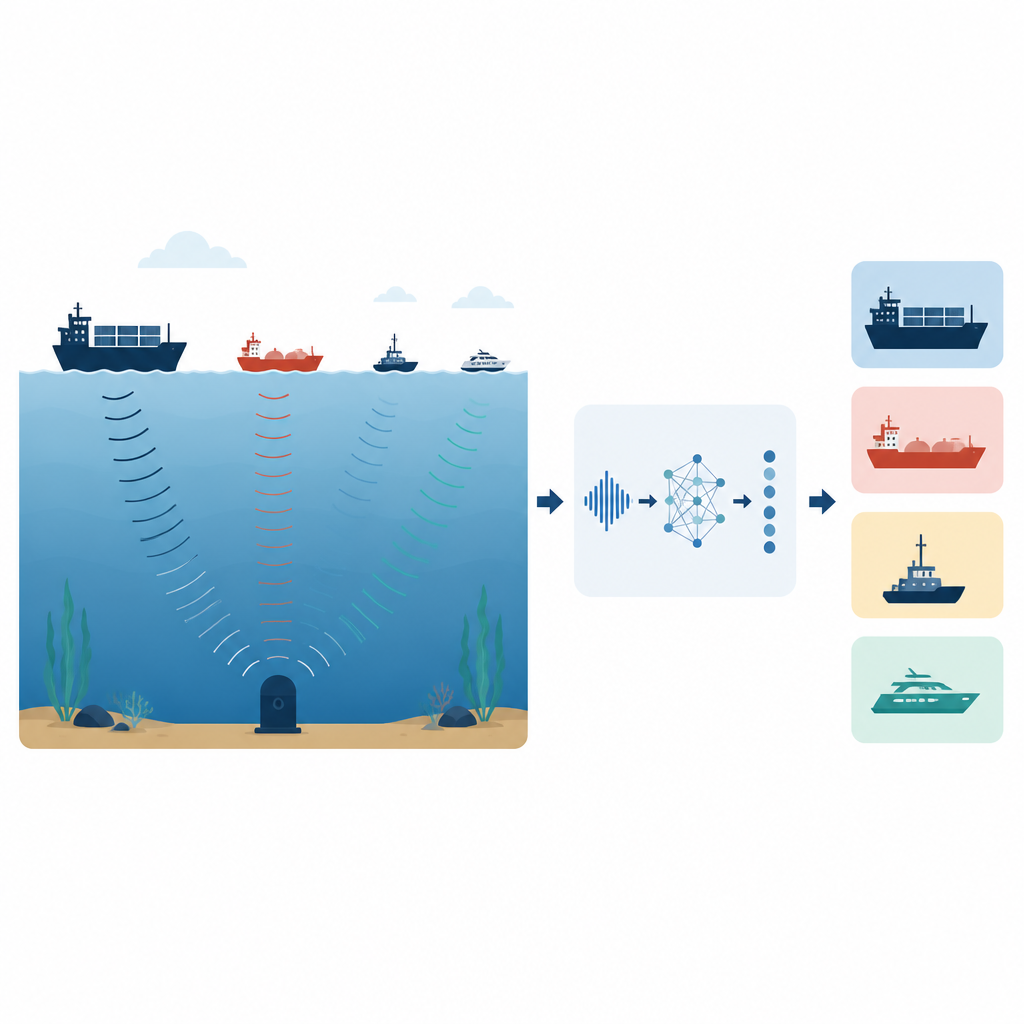
Океаны полны звуков от судов, животных и природных явлений, и разделение источников этих шумов жизненно важно для безопасности, обороны и защиты морской жизни. В этой работе представлен умный, но компактный слушающий модуль, который умеет различать типы кораблей только по их подводным звуковым сигнатурам. Тщательно настроив то, как алгоритм «слышит» и обрабатывает эти сигналы, авторы показывают, что можно распознавать суда с очень высокой точностью при минимальных вычислительных затратах, что открывает путь к массовому и недорогому подводному мониторингу.
Почему важны звуки кораблей
Современные моря — это оживлённые трассы, а низкий гул двигателей и винтов распространяется на большие расстояния под водой. Возможность определить, какое судно где находится, помогает навигации, поиску и спасению, наблюдению, а также позволяет учёным отслеживать влияние антропогенного шума на китов, рыбу и уязвимые экосистемы. Традиционные сонарные системы испытывают сложности, потому что подводный звук легко искажается волнами, течениями и эхо, а сигналы смешиваются с природным фоновым шумом. Старые методы распознавания также сильно опирались на экспертов или вручную настроенные правила, которые медленно адаптируются и не масштабируются до огромных объёмов данных, которые сейчас собирают датчики.
Обучая машины слышать под водой
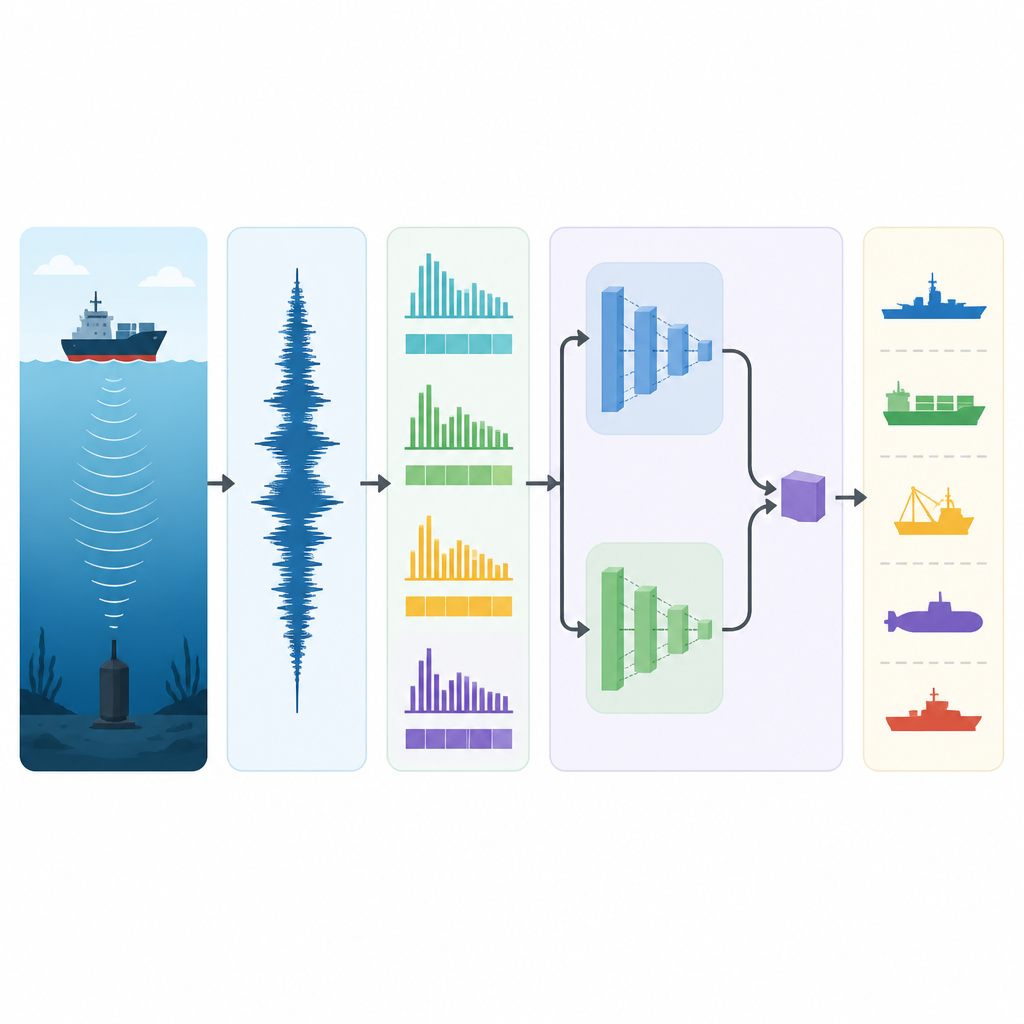
Чтобы решить эти задачи, исследователи построили конвейер прослушивания, который преобразует сырые записи в компактное представление ещё до попадания в основную обучающую часть. Сначала записи из двух реальных архивов шумов кораблей приводят к общей частоте дискретизации и разбивают на пятиметровые (пятимерные?) отрезки по пять секунд. Каждый отрезок затем копируется и мягко изменяется тремя способами: сдвигом высоты тона в узком диапазоне, чтобы смоделировать эффект Доплера; растяжением или сжатием скорости для имитации изменений движения судна; и добавлением реалистичного цветного шума, чтобы эмулировать океанский фон. Эти приёмы утраивают объём обучающих данных и показывают системе множество правдоподобных вариантов одного и того же судна, делая её менее чувствительной к мелким изменениям в записи. С каждого сегмента система извлекает простые и быстрые признаки, фиксирующие громкость, шероховатость и тональность звука, включая число пересечений нуля, общую энергию, то, насколько спектр соответствует шкалам восприятия человека, и распределение тонов по классам высоты, получая в итоге числовой отпечаток фиксированной длины.
Компактный «мозг» для звука
Сердцем метода служит модель, названная Depthwise Separable Convolutional Adaptive Transformer — разработанная как точная, так и экономная по ресурсам. Она начинается со специальных сверточных блоков, которые действуют как множество маленьких фильтров, отслеживающих кратковременные паттерны в последовательности признаков, например ритмические импульсы винтов или повторяющиеся циклы работы двигателя, при этом сохраняя низкую вычислительную нагрузку. На этой основе модель запускает две ветви трансформера параллельно, каждая из которых просматривает длинные отрезки звукового отпечатка, но с разным уровнем детализации. Эти ветви используют механизмы внимания, чтобы определить, какие части последовательности наиболее значимы, а затем сводят найденное с помощью операций пуллинга, суммирующих общее поведение. Адаптивная стадия слияния обучается взвешивать две ветви по-разному для каждого входа — отдавая предпочтение одной при необходимости тонких локальных деталей и другой, когда важна дальняя структура — прежде чем передать компактное резюме в финальный классификатор, выдающий наиболее вероятный класс судна.
Испытание системы
Авторы оценили свою архитектуру на двух известных коллекциях подводных шумов судов: одном долгосрочном наборе записей, сделанном у берегов Канады, и другом — с побережья Испании. В обоих случаях модель видела только пятиминутные (пятисекундные?) фрагменты и должна была отнести их к широким категориям судов, таким как грузовое, пассажирское, танкер, буксир или группы по размеру. Система показала около 98.8 процента точности на первом наборе и 99.2 процента на втором, при этом используя лишь порядка полумиллиона обучаемых параметров и несколько миллионов простых операций на один прогноз. Это делает её намного компактнее и быстрее многих современных глубоких моделей, при этом по точности она не уступает и даже превосходит их. Визуальный анализ внутренних представлений модели показал, что клипы разных типов судов образуют хорошо отделённые кластеры, а стандартные метрики — точность, полнота и кривые приёмника — подтверждают, что система редко путает классы между собой.
Что это значит для океанов
Популярно говоря, эта работа демонстрирует, что небольшая, тщательно спроектированная система прослушивания может надёжно различать типы судов в шумных реальных морских условиях и делать это достаточно быстро для почти реального времени. Сочетая простые, но информативные звуковые признаки с гибридной моделью, уравновешивающей локальные детали и долгосрочные паттерны, авторы предлагают практическую схему для будущих подводных мониторов, которые могут работать на буях, роботах или прибрежных станциях. Такие инструменты помогут управлять судоходными путями, поддерживать экологические исследования шумового загрязнения и улучшать автономные сонарные системы, оставаясь при этом достаточно экономными по вычислительным ресурсам для установки на скромном оборудовании.
Цитирование: Mahmud, NA., Zhang, T., Iqbal, Y. et al. A lightweight hybrid attention network with multi-scale feature integration for intelligent recognition of underwater acoustic targets. Sci Rep 16, 16388 (2026). https://doi.org/10.1038/s41598-026-47540-4
Ключевые слова: подводная акустика, шум кораблей, распознавание сонаром, глубокое обучение, морской мониторинг