Clear Sky Science · pl
Lekka hybrydowa sieć uwag z integracją cech wieloskalowych do inteligentnego rozpoznawania podwodnych celów akustycznych
Nasłuchując statków pod falami
Oceany wypełnione są dźwiękami pochodzącymi od statków, zwierząt i sił przyrody, a rozróżnienie, kto generuje który hałas, jest kluczowe dla bezpieczeństwa, obronności i ochrony życia morskiego. W tym badaniu przedstawiono inteligentny, a jednocześnie kompaktowy system nasłuchowy, który potrafi rozróżniać różne typy statków wyłącznie na podstawie ich podwodnych sygnatur dźwiękowych. Poprzez staranne zaprojektowanie sposobu, w jaki komputer „słyszy” i przetwarza te sygnały, autorzy wykazują, że możliwe jest rozpoznawanie statków z bardzo wysoką dokładnością przy stosunkowo niewielkim zapotrzebowaniu obliczeniowym, co otwiera drogę do powszechnego, niskokosztowego monitoringu podwodnego.
Dlaczego dźwięki statków są istotne
Współczesne oceany to ruchliwe szlaki, a niski pomruk silników i śrub rozchodzi się na duże odległości pod wodą. Możliwość rozpoznania, który statek znajduje się w danym miejscu, pomaga w nawigacji, poszukiwaniach i ratownictwie oraz w działaniach nadzorczych, a także pozwala naukowcom śledzić wpływ hałasu antropogenicznego na wieloryby, ryby i delikatne siedliska. Tradycyjne systemy sonarowe mają trudności, ponieważ dźwięk pod wodą łatwo ulega zniekształceniom przez fale, prądy i echo, a sygnały mieszają się z naturalnym tłem akustycznym. Starsze metody rozpoznawania opierały się też w dużej mierze na ekspertach lub ręcznie dostrajanych zasadach, które wolno się adaptują i nie skalują się do ogromnych ilości danych zbieranych dziś przez czujniki.
Nauczanie maszyn słuchania pod wodą
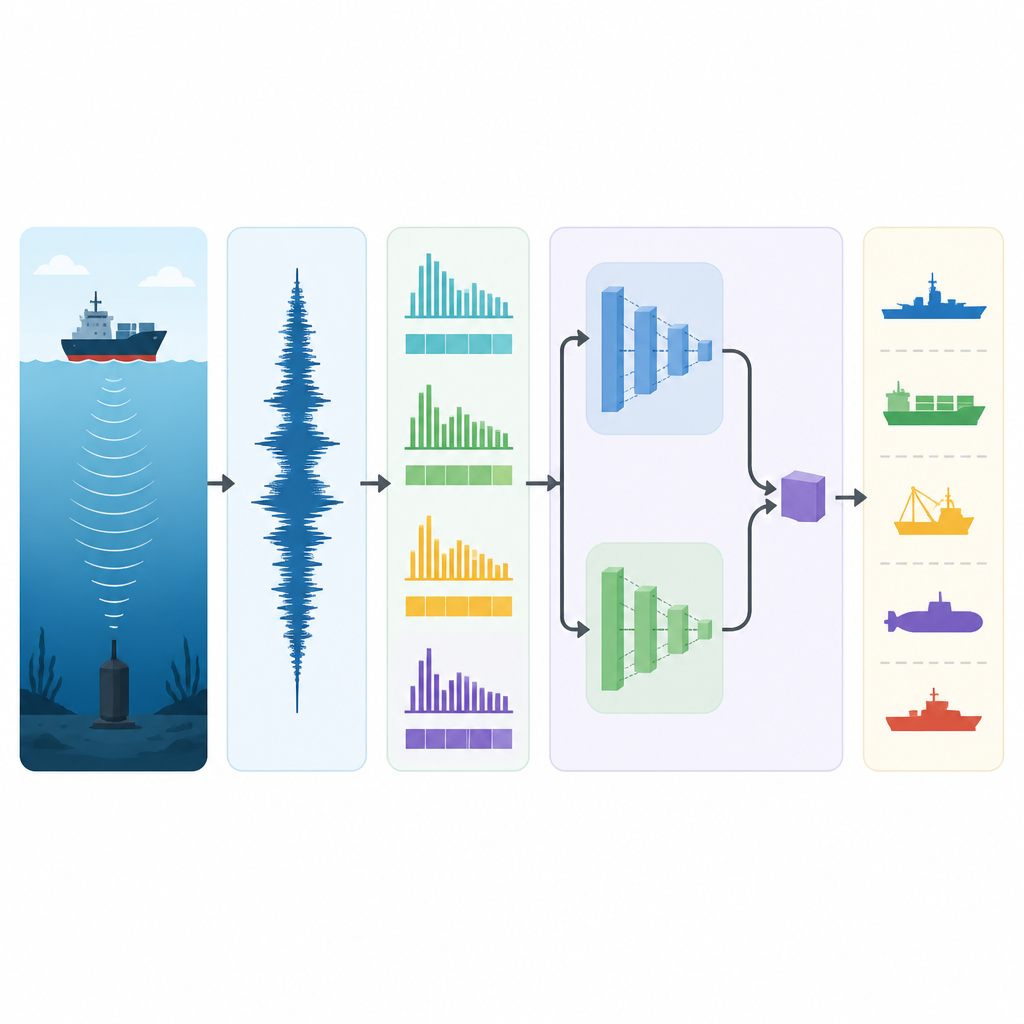
Aby sprostać tym wyzwaniom, badacze zbudowali potok nasłuchowy, który przekształca surowy dźwięk w skompaktowany opis zanim trafi do głównego silnika uczącego się. Najpierw nagrania z dwóch rzeczywistych archiwów hałasu statków są przeskalowywane do wspólnej częstotliwości próbkowania i dzielone na pięciosekundowe klipy. Każdy klip jest następnie kopiowany i delikatnie zmieniany na trzy sposoby: przesunięcie wysokości tonu w wąskim zakresie, aby naśladować efekt Dopplera; rozciąganie lub ściskanie prędkości, by imitować zmiany ruchu statku; oraz dodanie realistycznego, kolorowego szumu, by odtworzyć morski szum tła. Te kroki potrajają ilość danych treningowych i eksponują system na wiele prawdopodobnych wariantów tego samego statku, zmniejszając jego wrażliwość na drobne różnice w warunkach nagrania. Z każdego segmentu system wyodrębnia proste, szybkie cechy opisujące siłę, chropowatość i tonalność dźwięku, w tym częstość przekroczeń zera, całkowitą energię, sposób, w jaki spektrum odpowiada skalom słyszalności ludzkiej, oraz rozkład tonów w klasach wysokości, kończąc na liczbowym odcisku o stałej długości.
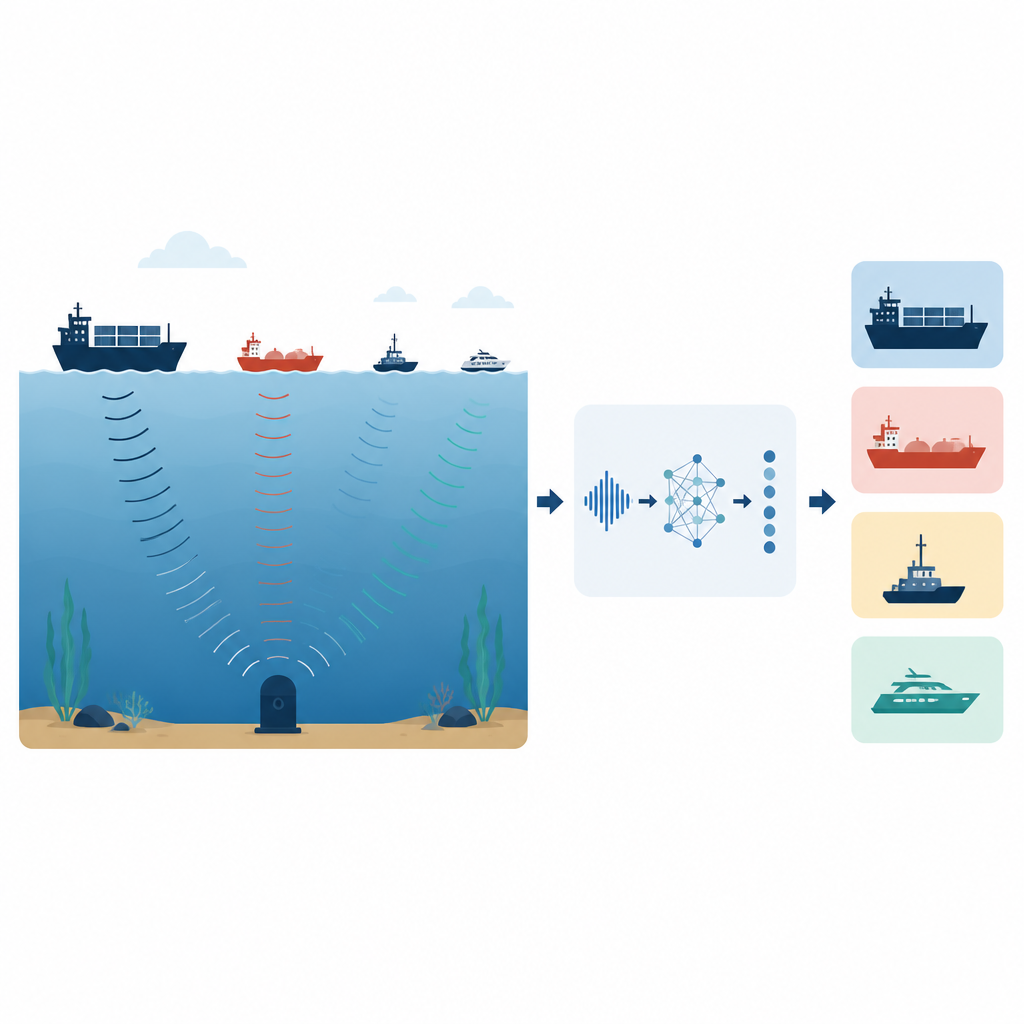
Kompaktowy „mózg” do dźwięku
Rdzeniem metody jest model nazwany Depthwise Separable Convolutional Adaptive Transformer, zaprojektowany tak, by być jednocześnie dokładnym i lekkim. Zaczyna się od specjalnych bloków konwolucyjnych działających jak wiele małych filtrów nasłuchujących krótkoterminowych wzorców w sekwencji cech, takich jak rytmiczne impulsy śrub czy powtarzające się cykle silnika, przy jednoczesnym utrzymaniu niskiej liczby operacji obliczeniowych. Na to nakładają się dwa równoległe „gałęzie” transformera, z których każda analizuje długie fragmenty odcisku dźwiękowego, ale o różnej szczegółowości. Gałęzie te wykorzystują mechanizmy uwagi, by zdecydować, które części sekwencji są najważniejsze, a następnie kondensują swoje obserwacje przez operacje poolingu podsumowujące ogólne zachowanie. Etap adaptacyjnej fuzji uczy się różnie ważyć obie gałęzie dla każdego wejścia, faworyzując jedną, gdy kluczowe są drobne lokalne detale, a drugą, gdy więcej informacji niesie struktura długozasięgowa, zanim przekaże skompaktowane streszczenie do końcowego klasyfikatora zwracającego najbardziej prawdopodobną klasę statku.
Próby systemu
Autorzy ocenili swój projekt na dwóch znanych zbiorach hałasu statków pod wodą: jednym długoterminowym nagranym u wybrzeży Kanady i drugim z wybrzeży Hiszpanii. W obu przypadkach model widział tylko pięciosekundowe klipy i musiał przypisać je do szerokich kategorii statków, takich jak towarowe, pasażerskie, tankowce, holowniki czy grupy oparte na rozmiarze. System osiągnął około 98,8% dokładności na pierwszym zbiorze i 99,2% na drugim, wykorzystując jednocześnie jedynie około pół miliona trenowalnych parametrów i kilka milionów prostych operacji na predykcję. Czyni to model znacznie mniejszym i szybszym niż wiele obecnych modeli głębokiego uczenia, a jednocześnie dorównującym lub przewyższającym je pod względem dokładności. Analizy wizualne wewnętrznych reprezentacji modelu pokazały, że klipy z różnych typów statków tworzą dobrze oddzielone klastry, a standardowe miary, takie jak precyzja, trafność i krzywe ROC, potwierdziły, że system rzadko myli jedną klasę z drugą.
Co to oznacza dla oceanów
Mówiąc prosto, praca ta pokazuje, że mały, starannie zaprojektowany system nasłuchowy może niezawodnie rozróżniać typy statków w hałaśliwych, rzeczywistych warunkach morskich i robić to wystarczająco szybko do zastosowań niemal w czasie rzeczywistym. Łącząc proste, lecz informatywne cechy dźwięku z hybrydowym modelem równoważącym lokalne detale i długoterminowe wzorce, autorzy dostarczają praktycznego schematu dla przyszłych monitorów podwodnych, które mogłyby działać na bojach, robotach czy stacjach przybrzeżnych. Takie narzędzia mogą pomóc w zarządzaniu szlakami żeglugowymi, wspierać badania nad zanieczyszczeniem akustycznym środowiska i ulepszać autonomiczne systemy sonarowe, przy zachowaniu niskich wymagań obliczeniowych pozwalających na pracę na skromnym sprzęcie.
Cytowanie: Mahmud, NA., Zhang, T., Iqbal, Y. et al. A lightweight hybrid attention network with multi-scale feature integration for intelligent recognition of underwater acoustic targets. Sci Rep 16, 16388 (2026). https://doi.org/10.1038/s41598-026-47540-4
Słowa kluczowe: akustyka podwodna, hałas statków, rozpoznawanie sonarowe, uczenie głębokie, monitoring morski