Clear Sky Science · ar
شبكة انتباه هجينة خفيفة الوزن بدمج ميزات متعددة المقاييس للتعرف الذكي على الأهداف الصوتية تحت الماء
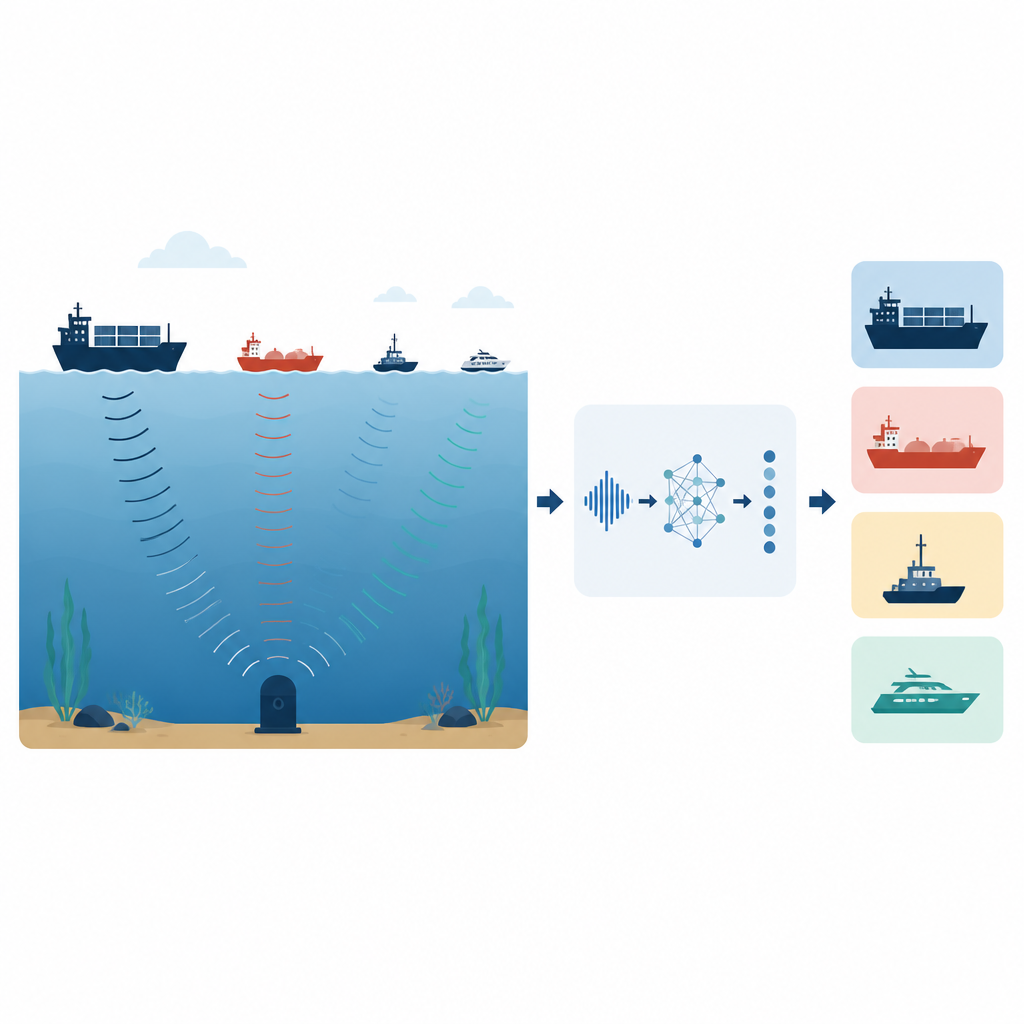
الاستماع إلى السفن تحت الأمواج
تمتلئ المحيطات بأصوات من السفن والحيوانات والقوى الطبيعية، وفصل من يصدر أي ضجيج أمر حيوي للسلامة والدفاع وحماية الحياة البحرية. تطرح هذه الدراسة نظام استماع ذكي ومضغوط قادر على التمييز بين أنواع السفن باستخدام بصمات صوتها تحت الماء فقط. من خلال تشكيل طريقة استماع الحاسوب ومعالجة هذه الإشارات بعناية، يبيّن المؤلفون أنه من الممكن التعرف على السفن بدقة عالية جداً مع استخدام طاقة حوسبة ضئيلة بشكل مدهش، ما يفتح الباب لمراقبة بحرية رخيصة ومنتشرة.
لماذا تهم أصوات السفن
المحيطات الحديثة طرق مائية مزدحمة، وهدير المحركات والمراوح منخفض التردد ينتقل لمسافات طويلة تحت الماء. القدرة على تحديد أي سفينة وأين تساعد الملاحة والبحث والإنقاذ والمراقبة، كما تتيح للعلماء تتبّع تأثير الضوضاء البشرية على الحيتان والأسماك والموائل الحسّاسة. تعاني أنظمة السونار التقليدية لأن الصوت تحت الماء يتشوه بسهولة بفعل الأمواج والتيارات والانعكاسات، وتختلط الإشارات بضوضاء الخلفية الطبيعية. كما اعتمدت طرق التعرف القديمة بشكل كبير على الخبراء البشر أو قواعد مضبوطة يدوياً، وهي بطيئة في التكيف ولا تتناسب مع الأحجام الضخمة من البيانات التي تجمعها المستشعرات اليوم.
تعليم الآلات على السمع تحت الماء
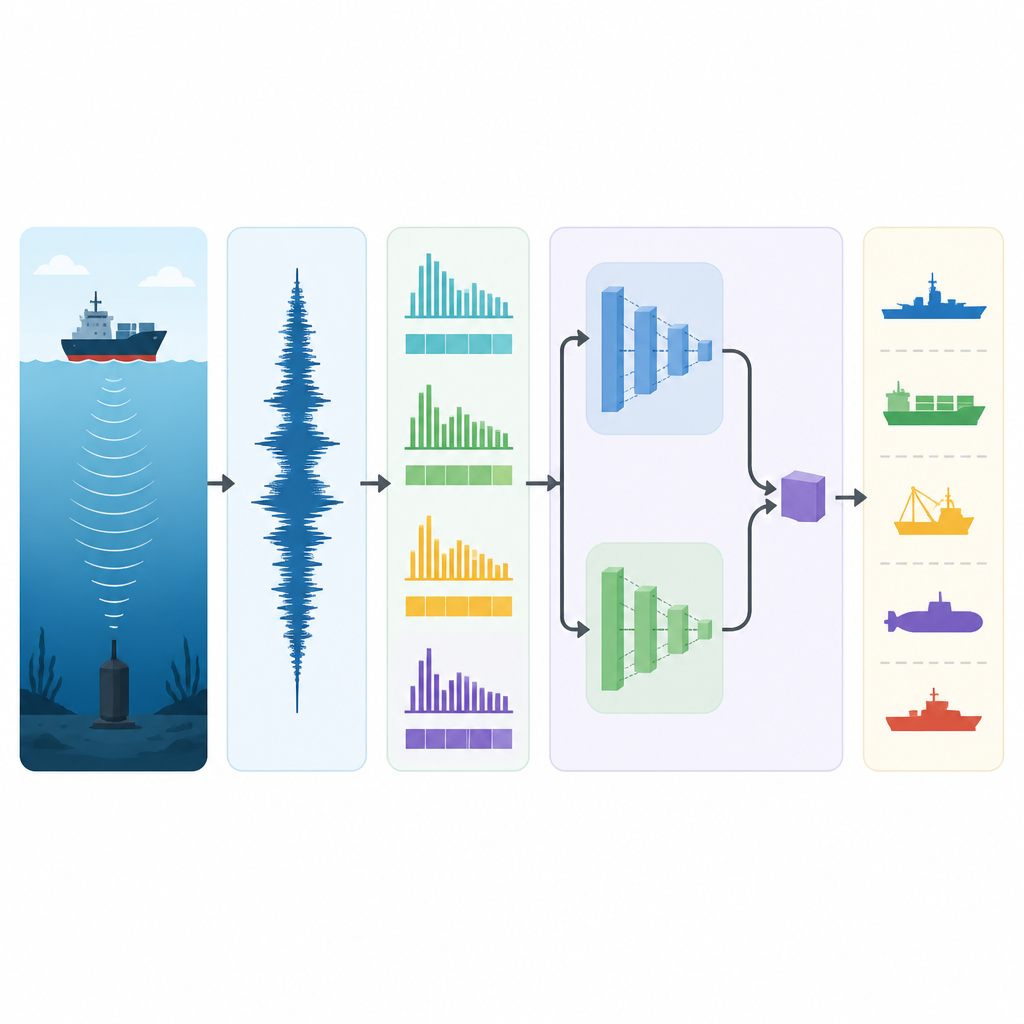
لمواجهة هذه التحديات بنى الباحثون سلسلة معالجة تعيد تشكيل الصوت الخام إلى وصف مضغوط قبل أن يصل إلى المحرك التعلمي الرئيسي. أولاً، تُعاد عينات التسجيلات من أرشيفي ضوضاء السفن الواقعيين إلى معدل مشترك وتُقسّم إلى مقاطع مدتها خمس ثوانٍ. تُنسخ كل مقطع ثم تُعدّل بلطف بثلاث طرق: تُغيّر طبقة الصوت ضمن نطاق ضيق لمحاكاة تأثيرات دوبلر، وتُمدد أو تُضغط سرعته لمحاكاة تغيّر حركة السفينة، ويُضاف نمط ضوضاء ملون واقعي لمحاكاة همهمة المحيط. تضاعف هذه الخطوات كمية بيانات التدريب ثلاث مرات وتعرّض النظام للعديد من النسخ المحتملة لنفس السفينة، ما يجعله أقل حساسية للتغيرات الطفيفة في طريقة تسجيل الصوت. من كل مقطع يستخرج النظام ميزات بسيطة وسريعة تلتقط شدة الصوت وخشونته وطابعه النغمي، بما في ذلك عدد مرات عبوره للصفر، والطاقة الكلية، وكيف يشبه طيفه مقياس السمع البشري، وكيف تتوزع نغماته عبر فئات النغمات، لتنتهي ببصمة رقمية بطول ثابت.
مخّ مدمج للصوت
جوهر الطريقة هو نموذج يسمى التحويل التكيفية الالتفافية القابلة للفصل بالعمق (Depthwise Separable Convolutional Adaptive Transformer)، مصمم ليكون دقيقاً وخفيف الوزن في آن واحد. يبدأ بكتل التفاف خاصة تعمل مثل العديد من المرشحات الصغيرة التي تستمع لأنماط قصيرة الأمد في تسلسل الميزات، مثل نبضات المراوح الإيقاعية أو دورات المحرك المتكررة، مع الحفاظ على انخفاض عدد الحسابات. فوق ذلك يشغّل النموذج فرعين من نوع المحول (Transformer) متوازيين، كل منهما ينظر إلى فترات طويلة من بصمة الصوت لكن بمستويات تفصيل مختلفة. تستخدم هذه الفروع آليات انتباه لتقرير أي أجزاء التسلسل أكثر أهمية، ثم تُوجز نتائجها عبر عمليات تجميع تلخص السلوك العام. يتعلّم مرحلة دمج تكيّفية وزن الفرعين بشكل مختلف لكل إدخال، مفضّلة أحدهما عندما تكون التفاصيل المحلية الدقيقة حاسمة والآخر عندما تحمل البنية طويلة المدى معلومات أكبر، قبل أن يمرر ملخصاً مضغوطاً إلى مُصنّف نهائي يخرج فئة السفينة الأكثر احتمالاً.
اختبار النظام
قيّم المؤلفون تصميمهم على مجموعتي تسجيلات ضوضاء سفن تحت الماء معروفتين، إحداهما مجموعة بيانات طويلة المدى مسجلة قبالة سواحل كندا والأخرى من السواحل الإسبانية. في كلتا الحالتين رأى النموذج مقاطع مدتها خمس ثوانٍ فقط وكان عليه تصنيفها إلى فئات عامة للسفن مثل شحن، ركاب، ناقلة، قاطرة، أو مجموعات حسب الحجم. حقق النظام نحو 98.8 في المئة دقة على مجموعة البيانات الأولى و99.2 في المئة على الثانية، بينما استخدم نحو نصف مليون معامل قابل للتدريب وعدة ملايين من العمليات الأساسية لكل توقع. هذا يجعله أصغر وأسرع بكثير من العديد من نماذج التعلم العميق الحالية، ومع ذلك طابقها أو تفوق عليها في الدقة. أظهرت تحليلات بصرية للتُمثيلات الداخلية للنموذج أن المقاطع من أنواع السفن المختلفة تشكل عناقيد مفصولة جيداً، وأكدت مقاييس معيارية مثل الدقة والاستدعاء ومنحنيات المستلم أن النظام نادراً ما يخلط بين فئة وأخرى.
ماذا يعني هذا للمحيطات
بعبارات بسيطة، تُظهر هذه العمل أن نظام استماع صغير ومصمم بعناية يمكنه التمييز بين أنواع السفن بشكل موثوق في بيئات بحرية صاخبة وحقيقية، ويمكنه القيام بذلك بسرعة كافية للاستخدام بالقرب من الوقت الحقيقي. من خلال إقران ميزات صوتية بسيطة لكنها غنية بالمعلومات مع نموذج هجين يوازن بين التفاصيل المحلية والأنماط طويلة المدى، يقدّم المؤلفون مخططاً عملياً لمراقبات بحرية مستقبلية يمكن تشغيلها على عوامات أو روبوتات أو محطات رصيفية. يمكن أن تساعد مثل هذه الأدوات في إدارة الممرات الملاحية، ودعم الدراسات البيئية لتلوث الضوضاء، وتحسين أنظمة السونار الذاتية، كل ذلك مع إبقاء متطلبات الحوسبة منخفضة بما يكفي لتناسب أجهزة متواضعة.
الاستشهاد: Mahmud, NA., Zhang, T., Iqbal, Y. et al. A lightweight hybrid attention network with multi-scale feature integration for intelligent recognition of underwater acoustic targets. Sci Rep 16, 16388 (2026). https://doi.org/10.1038/s41598-026-47540-4
الكلمات المفتاحية: علم الصوت تحت الماء, ضوضاء السفن, تمييز بالسونار, التعلّم العميق, المراقبة البحرية