Clear Sky Science · ru
Прогнозирование индекса качества воздуха с использованием гибридной модели CEEMDAN-CNN-IGWO-BiGRU-Attention
Почему более точные прогнозы воздуха важны
Жители городов часто слышат, что воздух завтра будет «хорошим» или «вредным», но такие предупреждения могут быть неопределёнными или поступать поздно. В этом исследовании рассматривается простой практический вопрос: можно ли точнее предсказывать качество воздуха изо дня в день, чтобы люди, врачи и городские службы могли планировать заранее? Авторы сосредоточились на Гуанчжоу, крупном южнокитайском городе, и создали новую компьютерную модель, которая преобразует неупорядоченные записи о загрязнении в надёжные прогнозы индекса качества воздуха (AQI) на следующий день, с целью поддержать реальные системы раннего предупреждения.
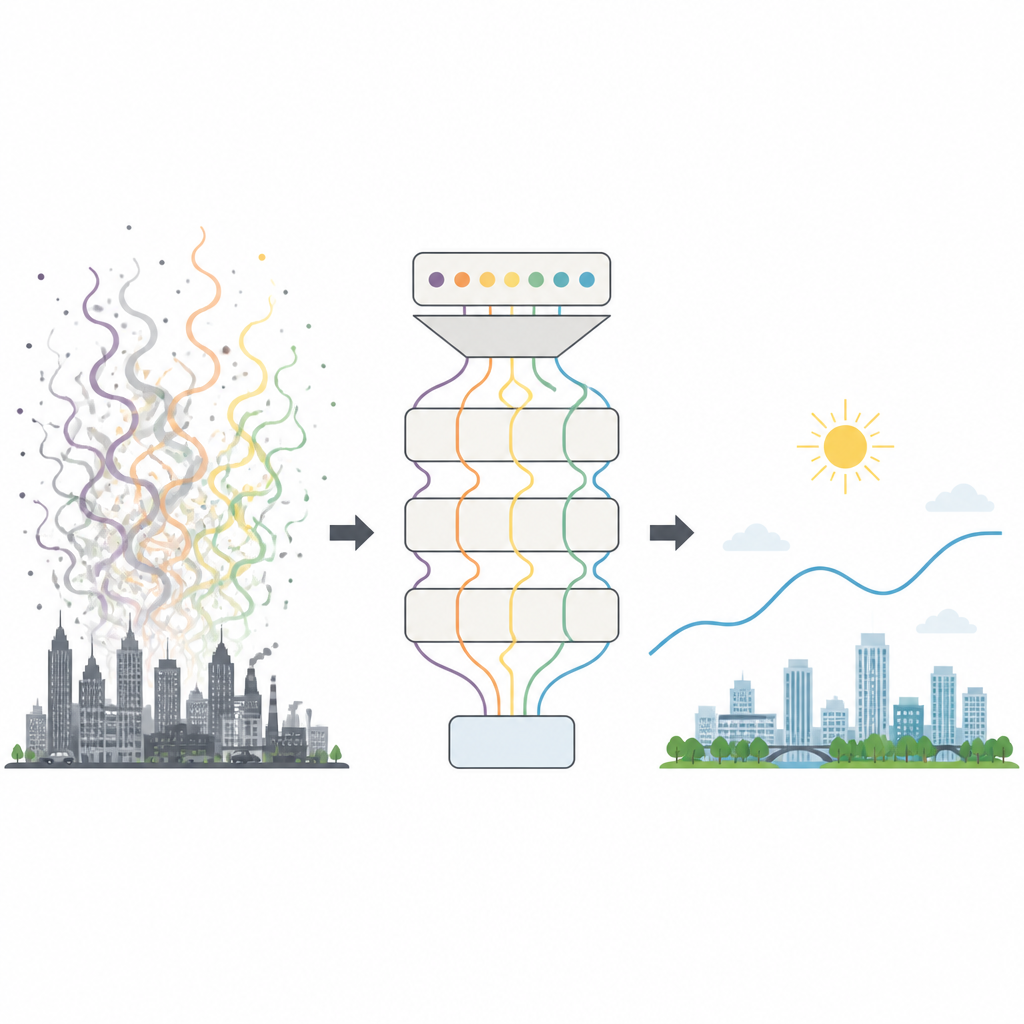
Разбираясь в хаотичном городском воздухе
Качество воздуха формируется множеством переменных факторов — от трафика и заводов до погоды, сезонов и внезапных событий, таких как пыльные бури. В результате показания AQI колеблются сложным, шумным образом, с которым не справляются многие традиционные инструменты прогнозирования. Физически основанные модели требуют огромных вычислительных ресурсов и детальных учётов выбросов, тогда как простые статистические методы с трудом обрабатывают резкие изменения городского смога. Даже многие современные системы машинного обучения затрудняются выделить ключевые закономерности в таких запутанных данных и часто требуют много проб и ошибок для настройки внутренних параметров.
Разбить задачу на более чистые части
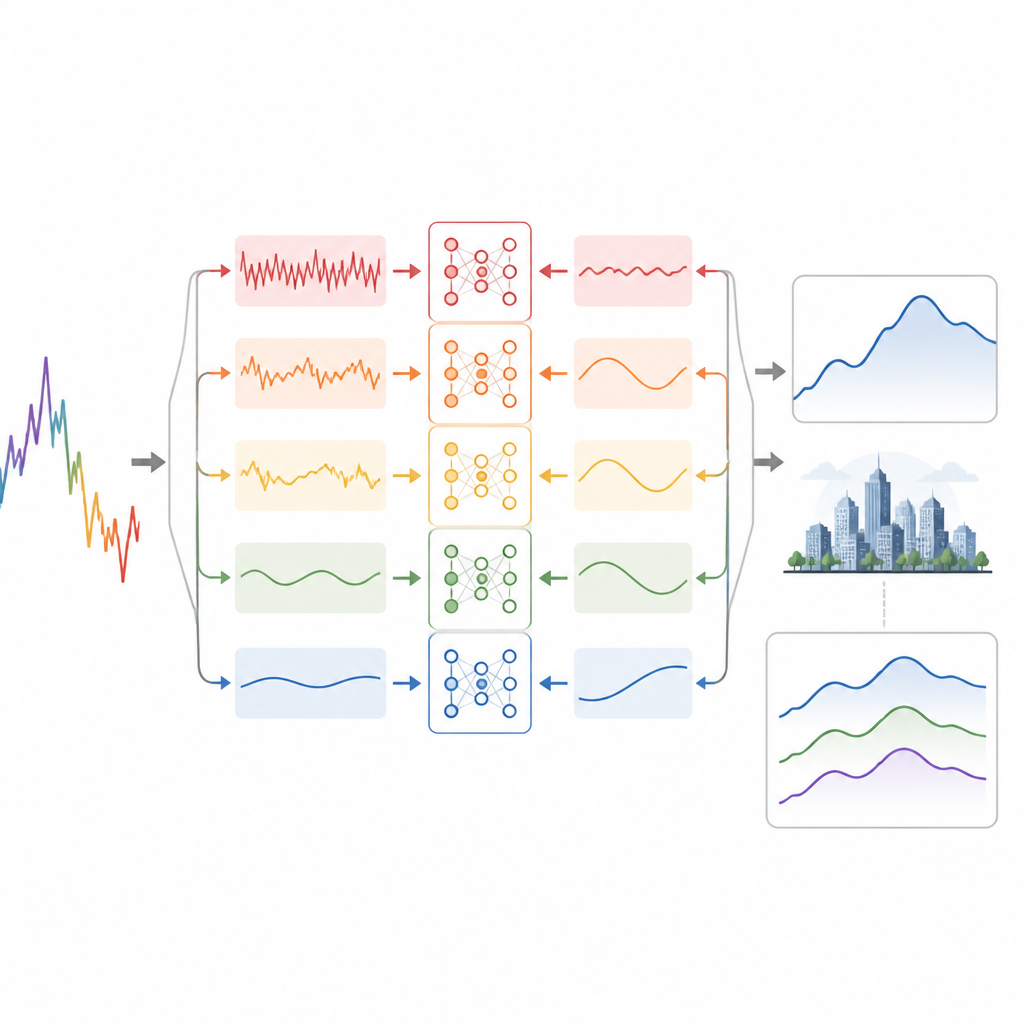
Первый приём исследователей — разделить суточную запись AQI на несколько более гладких слоёв, каждый из которых отражает изменения на своей временной шкале. Они используют метод обработки сигналов, который добавляет небольшие порции искусственного шума, чтобы отделить быстрые колебания, среднечастотные циклы и медленные фоновые тренды, не смешивая их друг с другом. Высокочастотные слои содержат быстрые всплески и случайные флуктуации, средние слои фиксируют значимые суточные и многодневные колебания, а финальный слой отображает долгосрочную тенденцию. Превращая одну шумную кривую в несколько более регулярных подпоследовательностей, общая задача прогнозирования становится проще и целенаправленнее.
Обучая модель «читать» время
Каждый из этих слоёв затем подаётся в специализированную нейросеть, объединяющую два преимущества. Набор одномерных свёрточных блоков ищет короткие локальные шаблоны, такие как повторяющиеся суточные циклы, с помощью фильтров разной длины. Их выходы поступают в двунаправленную рекуррентную сеть, которая смотрит вперёд и назад по временной оси, улавливая, как загрязнение накапливается и рассеивается в течение нескольких дней. Модуль внимания затем выделяет наиболее информативные дни в каждом окне, позволяя модели сосредоточиться на важнейших моментах при формировании прогноза. Наконец, прогнозы со всех слоёв суммируются, чтобы восстановить ожидаемый общий AQI.
Пусть цифровые «волки» настраивают параметры
Современные нейросети имеют много архитектурных выборов: сколько фильтров или блоков использовать, с какой скоростью обучаться и сколько dropout применять. Подбирать эти параметры вручную медленно и часто неэффективно. Чтобы избежать этого, авторы применяют популяционный поиск, вдохновлённый охотничьим поведением серых волков. Виртуальные «волки» исследуют пространство возможных настроек, ориентируясь на то, как хорошо каждая кандидатная сеть прогнозирует AQI на валидационном наборе. Улучшенная стратегия исследования и уточнения кандидатов помогает рою избегать локальных ловушек и наводиться на комбинации, которые поддерживают низкие ошибки прогноза и стабильное обучение.
Насколько хорошо работает подход
Испытанная на одиннадцати годах суточных данных AQI из Гуанчжоу новая система значительно превосходит широкий круг соперников, включая классические методы, стандартные рекуррентные сети и другие гибридные глубокие модели. Она достигает высокого коэффициента детерминации (R² примерно 0,96) и среднего квадратичного отклонения примерно в три раза меньшего, чем у сильной эталонной рекуррентной сети, при этом сохраняет приемлемую точность при прогнозах на три или семь дней вперёд. Тщательные «абляционные» тесты, в которых компоненты системы удаляются по одному, показывают, что каждый элемент — разложение сигнала, свёрточные блоки, двунаправленная память, слой внимания и волкоподобная настройка — вносит существенный вклад в итоговую производительность.
Что это означает для повседневной жизни
Для неспециалиста главная идея такова: авторы создали более умный способ распознавать скрытые ритмы в городских записях о смоге и превращать их в надёжные прогнозы AQI на следующий день. Модель лучше обрабатывает как быстрые колебания загрязнения, так и более длительные сезонные сдвиги по сравнению с существующими инструментами и может достаточно хорошо переноситься на другие города без полного повторного обучения. Хотя ей всё ещё трудно справляться с редкими экстремальными событиями и требуется значительная вычислительная мощность на этапе разработки, после обучения она может выдавать прогноз примерно за полсекунды. В практическом плане такая система может помочь городам выпускать более ранние и точные предупреждения, давая жителям больше времени скорректировать планы на открытом воздухе и защитить своё здоровье.
Цитирование: Fang, Y., Liu, S. & Su, Z. Air quality index prediction using a hybrid CEEMDAN-CNN-IGWO-BiGRU-Attention model. Sci Rep 16, 15908 (2026). https://doi.org/10.1038/s41598-026-46978-w
Ключевые слова: индекс качества воздуха, прогнозирование загрязнения воздуха, глубокое обучение, временные ряды, городская среда