Clear Sky Science · es
Predicción del índice de calidad del aire mediante un modelo híbrido CEEMDAN-CNN-IGWO-BiGRU-Atención
Por qué importan previsiones de aire más claras
Los habitantes de las ciudades suelen escuchar que el aire de mañana será “bueno” o “nocivo”, pero esas advertencias pueden ser vagas o llegar tarde. Este estudio aborda una pregunta práctica simple: ¿podemos predecir con mayor precisión la calidad del aire día a día para que la gente, los médicos y las autoridades municipales puedan planificar con antelación? Los autores se centran en Cantón, una gran ciudad del sur de China, y construyen un nuevo modelo informático que transforma registros de contaminación desordenados en previsiones fiables del Índice de Calidad del Aire (ICA) para el día siguiente, con el objetivo de apoyar sistemas de alerta temprana en la práctica.
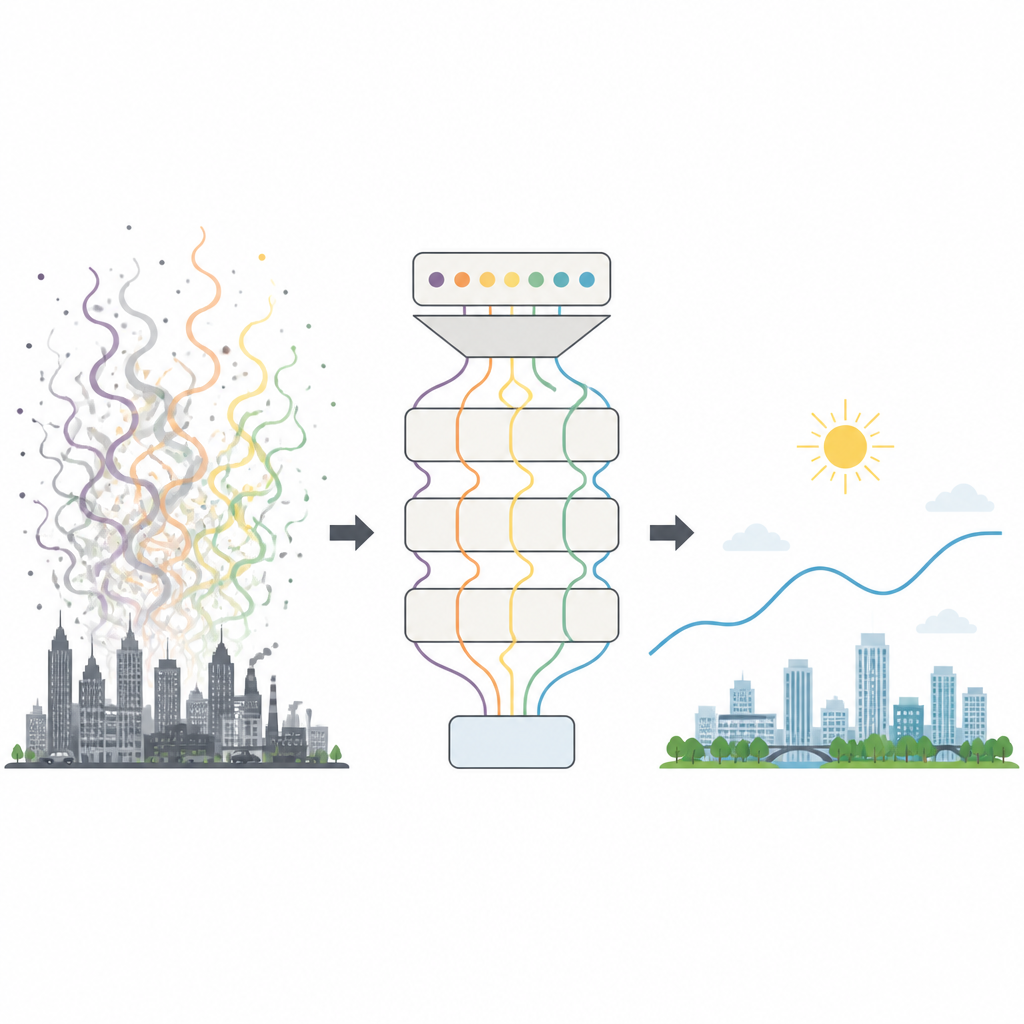
Entendiendo el aire caótico de la ciudad
La calidad del aire está moldeada por muchas fuerzas cambiantes, desde el tráfico y las fábricas hasta el tiempo, las estaciones y eventos repentinos como tormentas de polvo. Como resultado, las lecturas del ICA fluctúan de manera compleja y ruidosa que supera a muchas herramientas de predicción antiguas. Los modelos tradicionales basados en física requieren enorme capacidad de cálculo e inventarios detallados de emisiones, mientras que los métodos estadísticos simples luchan con los altibajos del smog urbano real. Incluso muchos sistemas modernos de aprendizaje automático siguen encontrando difícil extraer patrones clave de datos tan enmarañados y a menudo requieren tediosos ajustes por prueba y error para configurar sus parámetros internos.
Dividir el problema en piezas más limpias
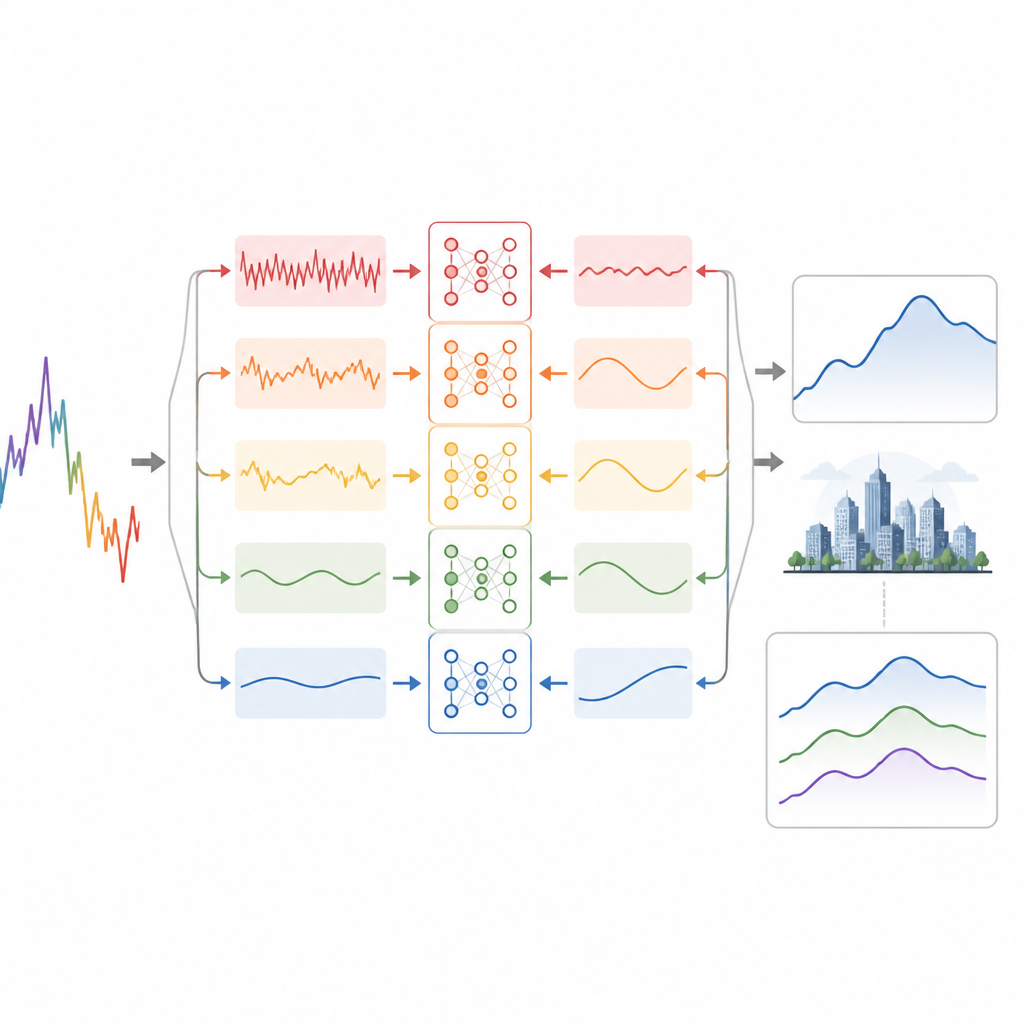
El primer recurso de los investigadores es descomponer la serie diaria del ICA en varias capas más suaves, cada una captando cambios en una escala temporal distinta. Usan un método de procesamiento de señales que añade pequeñas cantidades de ruido artificial para separar oscilaciones rápidas, ciclos de mediano plazo y tendencias de fondo lentas sin mezclarlas. Las capas de alta frecuencia contienen picos rápidos y fluctuaciones aleatorias, mientras que las capas intermedias concentran la mayoría de las oscilaciones significativas día a día y en varios días, y la capa final sigue la tendencia a largo plazo. Al convertir una curva desordenada en varias subseries más regulares, el reto global de predicción se vuelve más sencillo y específico.
Enseñar al modelo a leer el tiempo
Cada una de estas capas se introduce luego en una red neuronal especializada que combina dos fortalezas. Un conjunto de bloques convolucionales unidimensionales detecta patrones locales cortos, como ciclos diarios repetidos, usando filtros de distintas longitudes. Sus salidas pasan a una red recurrente bidireccional que mira tanto hacia adelante como hacia atrás en el eje temporal, captando cómo la contaminación se acumula y se disipa durante varios días. Un módulo de atención resalta los días más informativos en cada ventana, permitiendo que el modelo se concentre en lo que más importa al formular una previsión. Finalmente, las predicciones de todas las capas se suman para reconstruir el ICA global esperado.
Dejar que lobos digitales ajusten los controles
Las redes neuronales modernas tienen muchas decisiones de diseño, como cuántos filtros o unidades usar, la velocidad de aprendizaje y cuánto dropout aleatorio aplicar. Elegir estos valores a mano es lento y a menudo subóptimo. Para evitarlo, los autores emplean una búsqueda poblacional inspirada en el comportamiento de caza de los lobos grises. Lobos virtuales recorren el espacio de configuraciones posibles, guiados por lo bien que cada red candidata predice el ICA en un conjunto de validación. Una estrategia mejorada para explorar y refinar estos candidatos ayuda a la manada a escapar de cárceles locales y a centrarse en combinaciones que mantienen bajos los errores de predicción y un aprendizaje estable.
Qué tan bien funciona el enfoque
Probado con once años de datos diarios del ICA de Cantón, el nuevo marco supera claramente a una amplia gama de competidores, incluidos métodos clásicos, redes recurrentes estándar y otros modelos híbridos profundos. Logra un alto coeficiente de determinación (R² de aproximadamente 0,96) y un error cuadrático medio aproximadamente un tercio del de una red recurrente de referencia potente, y aún mantiene una precisión razonable cuando se le pide prever a tres o siete días vista. Pruebas de “ablación” cuidadosas, en las que se eliminan piezas del sistema una por una, muestran que cada componente —la descomposición de la señal, los bloques convolucionales, la memoria bidireccional, la capa de atención y el ajuste basado en lobos— contribuye de forma significativa al rendimiento final.
Qué significa esto para la vida cotidiana
Para un público no especializado, la conclusión es que los autores han desarrollado una forma más inteligente de leer los ritmos ocultos en los registros de smog urbano y convertirlos en previsiones fiables del ICA para el día siguiente. El modelo maneja mejor que las herramientas existentes tanto los cambios rápidos de contaminación como las variaciones estacionales más largas, y puede transferirse razonablemente bien a otras ciudades sin necesidad de reentrenar desde cero. Aunque todavía tiene dificultades con eventos extremos raros y exige un esfuerzo computacional significativo durante el desarrollo, una vez entrenado puede generar previsiones en aproximadamente medio segundo. En términos prácticos, este tipo de sistema podría ayudar a las ciudades a emitir advertencias más tempranas y precisas, dando a los residentes más tiempo para ajustar planes al aire libre y proteger su salud.
Cita: Fang, Y., Liu, S. & Su, Z. Air quality index prediction using a hybrid CEEMDAN-CNN-IGWO-BiGRU-Attention model. Sci Rep 16, 15908 (2026). https://doi.org/10.1038/s41598-026-46978-w
Palabras clave: índice de calidad del aire, pronóstico de la contaminación del aire, aprendizaje profundo, series temporales, entorno urbano