Clear Sky Science · fr
Prédiction de l’indice de qualité de l’air à l’aide d’un modèle hybride CEEMDAN-CNN-IGWO-BiGRU-Attention
Pourquoi des prévisions de la qualité de l’air plus claires comptent
Les citadins entendent souvent dire que l’air de demain sera « bon » ou « malsain », mais ces alertes peuvent être vagues ou trop tardives. Cette étude s’attaque à une question pratique simple : peut‑on prédire la qualité de l’air au jour le jour avec plus de précision afin que les habitants, les médecins et les responsables municipaux puissent mieux anticiper ? Les auteurs se concentrent sur Guangzhou, grande ville du sud de la Chine, et développent un nouveau modèle informatique qui transforme des relevés de pollution désordonnés en prévisions fiables de l’indice de qualité de l’air (AQI) pour le lendemain, dans le but de soutenir des systèmes d’alerte réels.
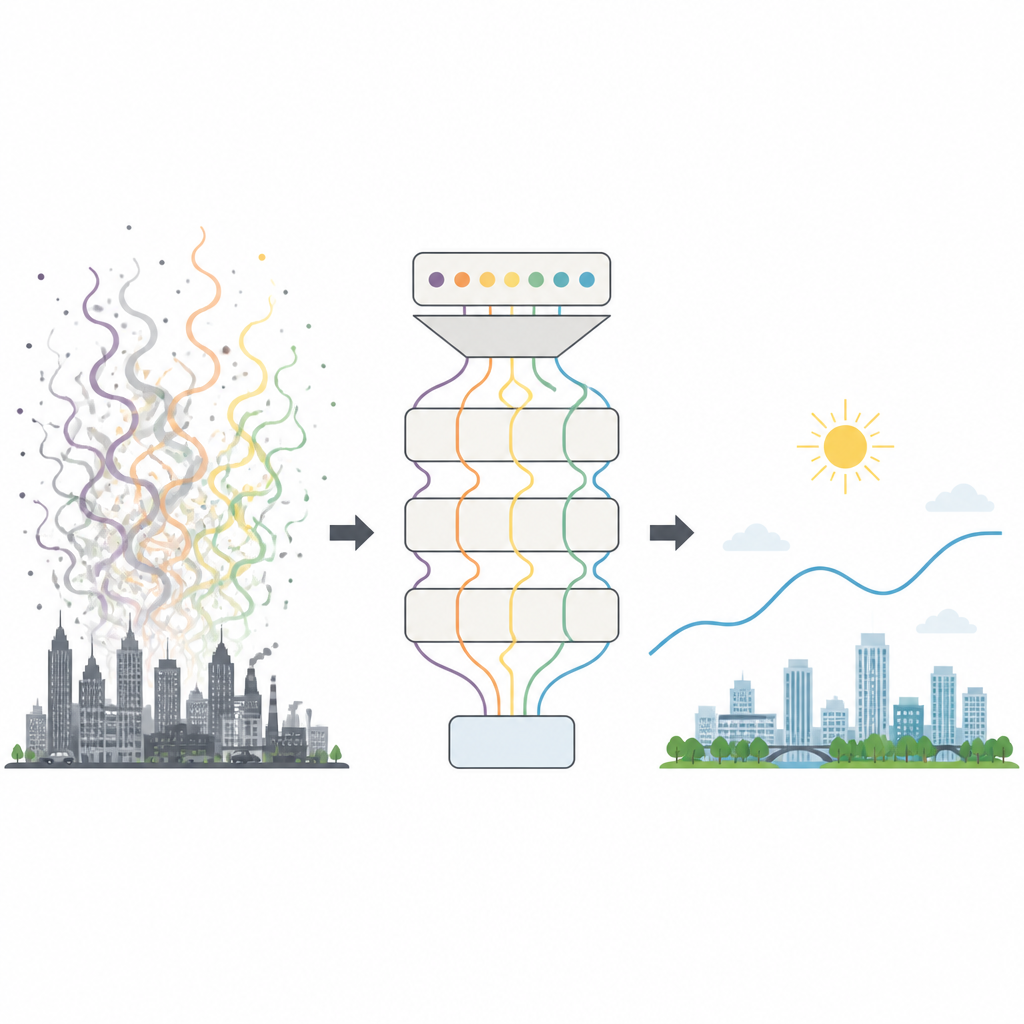
Rendre lisible un air urbain chaotique
La qualité de l’air résulte de nombreuses forces changeantes, du trafic et des usines aux conditions météorologiques, aux saisons et aux événements soudains comme les tempêtes de poussière. En conséquence, les mesures d’AQI fluctuent de manière complexe et bruitée, ce qui met à mal de nombreux outils de prévision plus anciens. Les modèles atmosphériques classiques basés sur la physique exigent une énorme puissance de calcul et des inventaires d’émissions détaillés, tandis que les méthodes statistiques simples peinent face aux variations du smog urbain réel. Même beaucoup de systèmes modernes d’apprentissage automatique ont du mal à extraire les motifs clés de données aussi emmêlées et nécessitent souvent des essais‑erreurs fastidieux pour régler leurs paramètres internes.
Fractionner le problème en morceaux plus propres
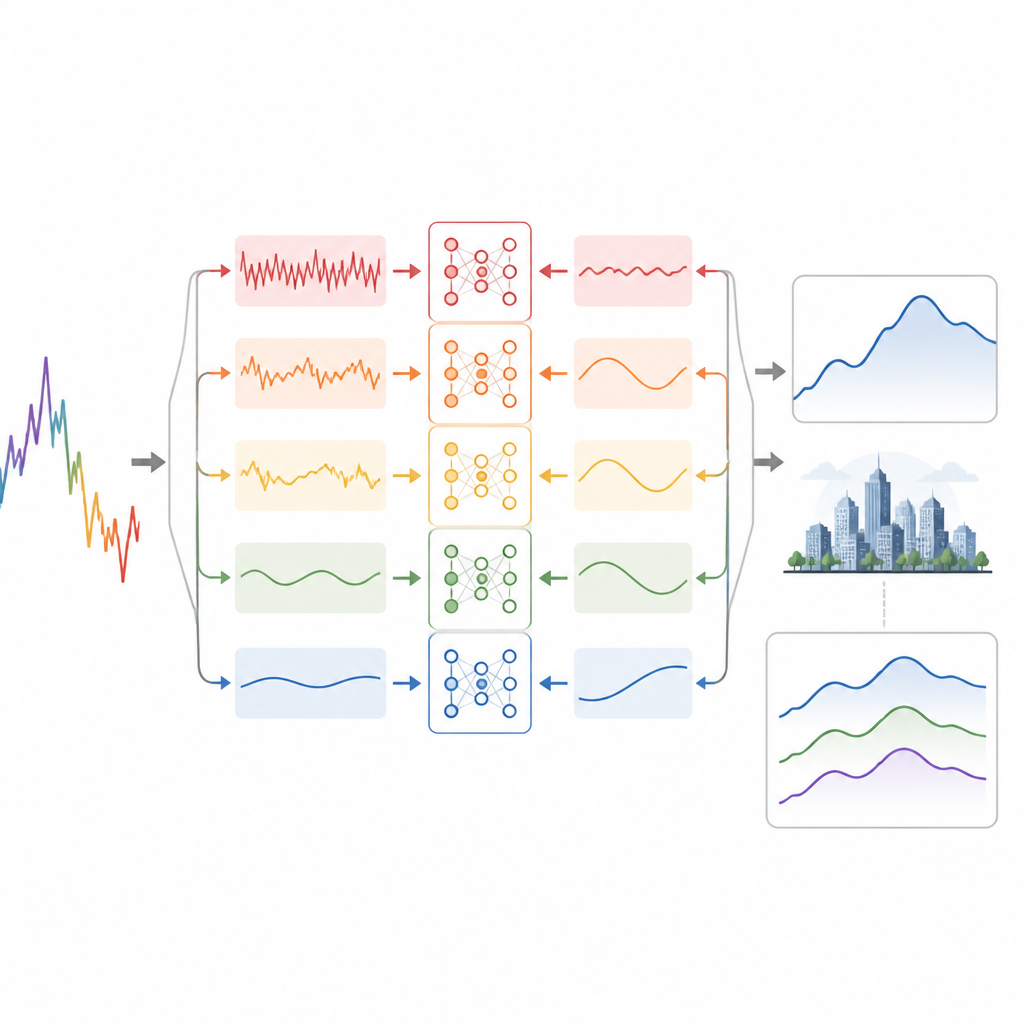
Le premier tour de force des chercheurs est de scinder la série journalière d’AQI en plusieurs couches plus lisses, chacune capturant des variations à une échelle temporelle différente. Ils utilisent une méthode de traitement du signal qui ajoute de petites quantités de bruit artificiel pour séparer les oscillations rapides, les cycles à moyen terme et les tendances de fond lentes sans les mélanger. Les couches haute fréquence contiennent des pics rapides et des fluctuations aléatoires, les couches intermédiaires portent la plupart des oscillations signifiantes jour après jour et sur plusieurs jours, et la couche finale retrace la tendance à long terme. En transformant une courbe désordonnée en plusieurs sous‑séries plus régulières, le défi de prévision global devient plus simple et plus ciblé.
Apprendre au modèle à « lire » le temps
Chacune de ces couches est ensuite entrée dans un réseau neuronal spécialisé qui combine deux forces. Un ensemble de blocs convolutionnels unidimensionnels repère des motifs locaux courts, comme des cycles quotidiens répétés, en utilisant des filtres de différentes longueurs. Leurs sorties sont alimentées dans un réseau récurrent bidirectionnel qui regarde à la fois vers l’avant et vers l’arrière sur l’axe temporel, captant comment la pollution s’accumule et se dissipe sur plusieurs jours. Un module d’attention met ensuite en évidence les journées les plus informatives de chaque fenêtre, permettant au modèle de se concentrer sur ce qui compte le plus pour établir une prévision. Enfin, les prédictions de toutes les couches sont recombinées pour reconstituer l’AQI global prévu.
Laisser des « loups » numériques régler les boutons
Les réseaux neuronaux modernes comportent de nombreux choix de conception, comme le nombre de filtres ou d’unités à utiliser, la vitesse d’apprentissage et le taux de dropout. Les choisir manuellement est lent et souvent sous‑optimal. Pour éviter cela, les auteurs utilisent une recherche basée sur une population inspirée du comportement de chasse des loups gris. Des « loups » virtuels explorent l’espace des réglages possibles, guidés par la qualité des prévisions d’AQI sur un jeu de validation. Une stratégie améliorée pour explorer et affiner ces candidats aide l’essaim à échapper aux impasses locales et à converger vers des combinaisons qui maintiennent des erreurs de prédiction faibles et un apprentissage stable.
Quelle est l’efficacité de l’approche
Testé sur onze ans de données journalières d’AQI de Guangzhou, le nouveau cadre surpasse nettement un large éventail d’adversaires, y compris des méthodes classiques, des réseaux récurrents standards et d’autres modèles profonds hybrides. Il atteint un coefficient de détermination élevé (R² d’environ 0,96) et une erreur quadratique moyenne environ trois fois plus faible que celle d’un réseau récurrent performant, et conserve une précision raisonnable lorsqu’on lui demande de prévoir à trois ou sept jours. Des tests d’ablation soigneux, où les composantes du système sont retirées une à une, montrent que chaque élément — la décomposition du signal, les blocs convolutionnels, la mémoire bidirectionnelle, la couche d’attention et le réglage par loups — contribue de manière significative à la performance finale.
Ce que cela change pour la vie quotidienne
Pour un non‑spécialiste, l’essentiel est que les auteurs ont construit une méthode plus intelligente pour lire les rythmes cachés des relevés de smog urbain et les convertir en prévisions fiables de l’AQI pour le lendemain. Le modèle gère mieux que les outils existants à la fois les fluctuations rapides de pollution et les variations saisonnières plus longues, et peut se transférer assez bien à d’autres villes sans réentraînement complet. S’il peine encore face aux événements extrêmes rares et exige un effort informatique important pendant la phase de développement, une fois entraîné il peut générer des prévisions en environ une demi‑seconde. Concrètement, ce type de système pourrait aider les villes à émettre des avertissements plus précoces et plus précis, donnant aux habitants plus de temps pour adapter leurs activités extérieures et protéger leur santé.
Citation: Fang, Y., Liu, S. & Su, Z. Air quality index prediction using a hybrid CEEMDAN-CNN-IGWO-BiGRU-Attention model. Sci Rep 16, 15908 (2026). https://doi.org/10.1038/s41598-026-46978-w
Mots-clés: indice de qualité de l’air, prévision de la pollution de l’air, apprentissage profond, séries temporelles, environnement urbain