Clear Sky Science · nl
Voorspelling van de luchtkwaliteitsindex met een hybride CEEMDAN-CNN-IGWO-BiGRU-Attention-model
Waarom duidelijkere luchtvoorspellingen ertoe doen
Stadsbewoners horen vaak dat de lucht van morgen “goed” of “ongezond” zal zijn, maar zulke waarschuwingen kunnen vaag of te laat zijn. Deze studie pakt een eenvoudige, praktische vraag aan: kunnen we de dag-tot-dag luchtkwaliteit nauwkeuriger voorspellen zodat mensen, artsen en stadsbestuurders beter kunnen plannen? De auteurs richten zich op Guangzhou, een grote stad in Zuid-China, en bouwen een nieuw rekenmodel dat rommelige vervuilingsregistraties omzet in betrouwbare AQI-voorspellingen voor de volgende dag, met als doel echte waarschuwingssystemen te ondersteunen.
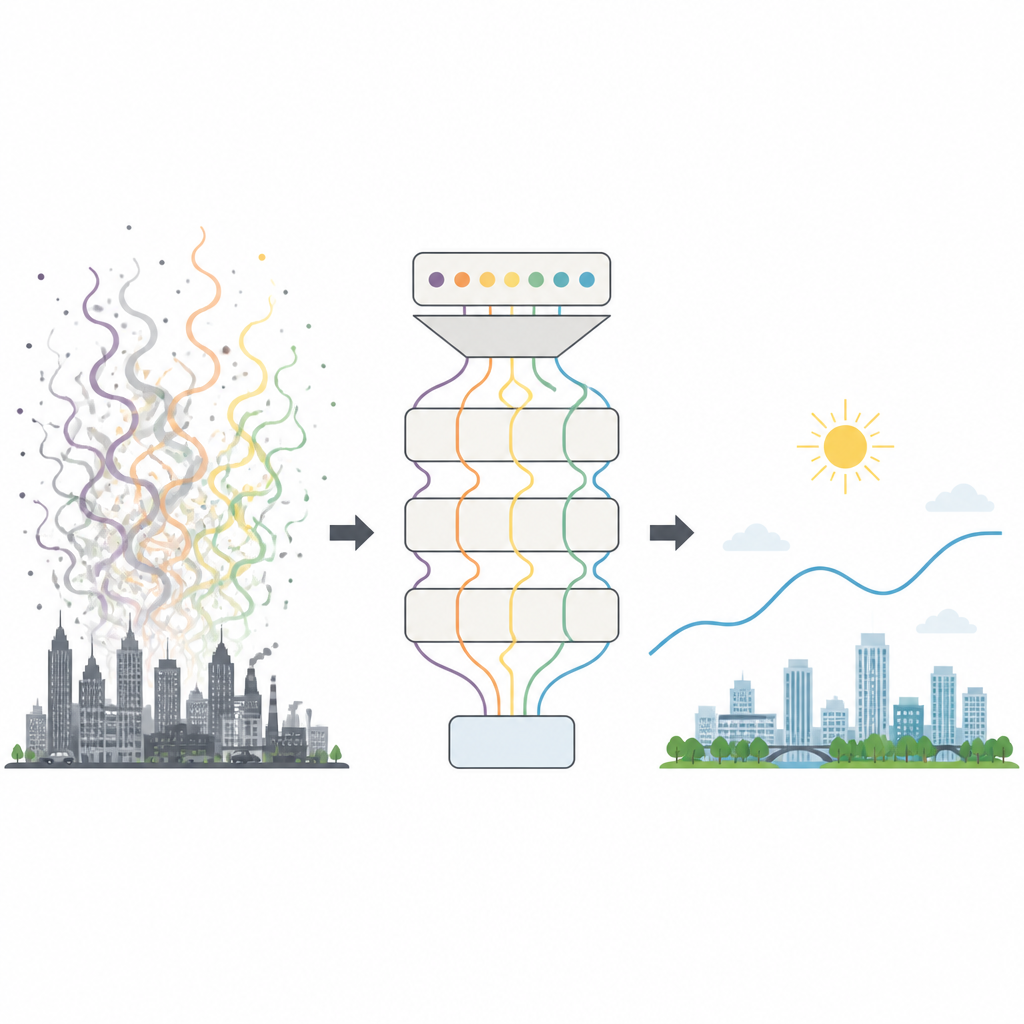
De rommelige stedelijke lucht begrijpen
Luchtkwaliteit wordt gevormd door veel veranderlijke factoren, van verkeer en fabrieken tot weer, seizoenen en plotselinge gebeurtenissen zoals zandstormen. Daardoor schommelen AQI-waarden op ingewikkelde, rumoerige manieren die veel oudere voorspellingsinstrumenten ontregelen. Traditionele fysische luchtmodellen vergen enorme rekenkracht en gedetailleerde emissie-inventarissen, terwijl eenvoudige statistische methoden moeite hebben met de ups en downs van echte stedelijke smog. Zelfs veel moderne machine learning-systemen vinden het nog moeilijk om belangrijke patronen uit zulke verwarde data te halen en vereisen vaak tijdrovend trial-and-error om hun interne instellingen af te stemmen.
Het probleem in schonere stukjes knippen
De eerste truc van de onderzoekers is het opsplitsen van de dagelijkse AQI-reeks in meerdere soepelere lagen, die elk veranderingen op een ander tijdschaal vastleggen. Ze gebruiken een signaalverwerkingsmethode die kleine hoeveelheden kunstmatig geluid toevoegt om snelle rimpelingen, middellange cycli en langzame achtergrondtrends van elkaar te scheiden zonder ze te vermengen. Hoogfrequente lagen bevatten snelle pieken en willekeurige schommelingen, terwijl middenlagen de meeste betekenisvolle dag-tot-dag en meerdaagse schommelingen bevatten, en de laatste laag de langetermijntrend volgt. Door één rommelige curve in meerdere meer regelmatige subseries te transformeren, wordt de algehele voorspellingsuitdaging eenvoudiger en gerichter.
Het model leren tijd te lezen
Elk van deze lagen wordt vervolgens gevoed aan een gespecialiseerd neuraal netwerk dat twee sterktes combineert. Een reeks eendimensionale convolutielagen zoekt naar korte lokale patronen, zoals herhaalde dagelijkse cycli, met filters van verschillende lengtes. Hun uitkomsten gaan naar een bidirectioneel recurrent netwerk dat zowel vooruit als achteruit over de tijdsas kijkt, en vastlegt hoe vervuiling zich over meerdere dagen opbouwt en weer verdwijnt. Een attention-module markeert vervolgens de meest informatieve dagen in elk venster, zodat het model zich kan concentreren op wat het belangrijkst is bij het vormen van een voorspelling. Ten slotte worden de voorspellingen uit alle lagen bij elkaar opgeteld om de verwachte totale AQI te reconstrueren.
Digitale “wolven” de knoppen laten afstellen
Moderne neurale netwerken kennen veel ontwerpskeuzes, zoals hoeveel filters of units te gebruiken, hoe snel te leren en hoeveel willekeurige dropout toe te passen. Die handmatig kiezen is traag en vaak suboptimaal. Om dat te voorkomen gebruiken de auteurs een populatiegebaseerde zoekmethode geïnspireerd op het jachtgedrag van grijze wolven. Virtuele “wolven” verkennen de ruimte van mogelijke instellingen, gestuurd door hoe goed elk kandidaat-netwerk AQI voorspelt op een validatieset. Een verbeterde strategie voor verkenning en verfijning helpt de zwerm lokale doodlopende paden te vermijden en te convergeren naar combinaties die de voorspellingsfouten laag en het leren stabiel houden.
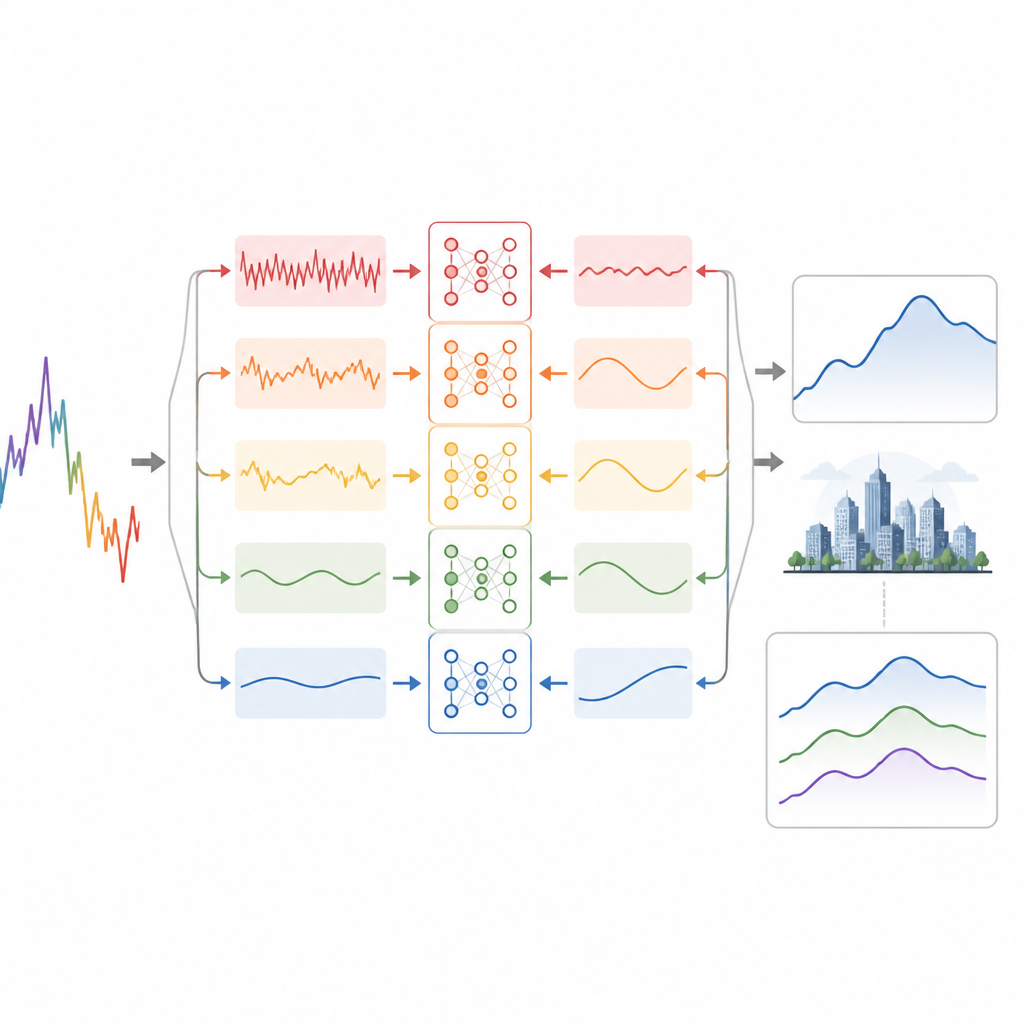
Hoe goed werkt de aanpak
Getest op elf jaar dagelijkse AQI-gegevens uit Guangzhou overtreft het nieuwe raamwerk duidelijk een breed scala aan concurrenten, waaronder klassieke methoden, standaard recurrente netwerken en andere hybride deep-modellen. Het behaalt een hoge verklaarde variantie (R² van ongeveer 0,96) en een mean squared error van ongeveer een derde van die van een sterk baseline recurrent netwerk, en behoudt nog steeds redelijke nauwkeurigheid bij voorspellingen drie of zeven dagen vooruit. Zorgvuldige "ablation"-tests, waarbij onderdelen van het systeem één voor één worden verwijderd, tonen aan dat elk component—de signaalscheiding, de convolutieblokken, het bidirectionele geheugen, de attention-laag en de wolven-gebaseerde afstemming—zinvol bijdraagt aan de uiteindelijke prestatie.
Wat dit betekent voor het dagelijks leven
Voor niet-specialisten is de kern dat de auteurs een slimmer manier hebben ontwikkeld om de verborgen ritmes in stedelijke smogregistraties te lezen en om te zetten in betrouwbare AQI-voorspellingen voor de volgende dag. Het model verwerkt zowel snelle vervuilingsschommelingen als langere seizoenswisselingen beter dan bestaande hulpmiddelen en kan redelijk goed worden overgedragen naar andere steden zonder volledig opnieuw te trainen. Hoewel het nog steeds moeite heeft met zeldzame extreme gebeurtenissen en tijdens de ontwikkelingsfase aanzienlijke rekeninspanning vereist, kan het eenmaal getraind voorspellingen in ongeveer een halve seconde genereren. In praktische termen zou zo’n systeem steden kunnen helpen eerdere, preciezere waarschuwingen uit te geven, waardoor bewoners meer tijd krijgen om buitenactiviteiten aan te passen en hun gezondheid te beschermen.
Bronvermelding: Fang, Y., Liu, S. & Su, Z. Air quality index prediction using a hybrid CEEMDAN-CNN-IGWO-BiGRU-Attention model. Sci Rep 16, 15908 (2026). https://doi.org/10.1038/s41598-026-46978-w
Trefwoorden: luchtkwaliteitsindex, voorspelling van luchtvervuiling, deep learning, tijdreeks, stedelijke omgeving