Clear Sky Science · ru
Избирательный алгоритм машинного обучения для маркировки тяжёлого пародонтита по данным опросников
Почему важны вопросы стоматолога
Многие крупные медицинские исследования хотели бы отслеживать заболевания дёсен, поскольку их связь с сердечными заболеваниями, диабетом, заболеваниями лёгких и даже осложнениями при COVID-19 хорошо документирована. Но точное покзубное измерение состояния дёсен занимает много времени, дорого и не всегда выполнимо в масштабных популяционных проектах. Поэтому исследователи часто опираются на простые опросники: вопросы о кровоточивости дёсен, шатающихся зубах или перенесённых лечении дёсен. В этом исследовании проверяется, могут ли современные компьютерные методы надежно использовать такие самоотчёты, чтобы выделять людей с очень тяжёлой формой заболевания и тех, у кого нет болезни вовсе, без проведения полного стоматологического осмотра.
Пародонтит, здоровье и пробелы в данных
Пародонтит — хроническая инфекция тканей, удерживающих зубы в альвеолах. Более половины взрослых во всём мире подвержены этому заболеванию, и у значительной части наблюдаются тяжёлые формы, приводящие к потере зубов и затруднению приёма пищи. Поскольку заболевание дёсен столь распространено и связано с общим состоянием здоровья, оно представляет собой важную цель для медицинских исследований. Однако многие популяционные исследования просто не имеют времени или средств для подробной стоматологической картирования. Часто фиксируют лишь краткий скрининговый индекс и самоотчёт по здоровью полости рта. Проблема в том, что люди могут неправильно понимать вопросы или по‑разному оценивать своё состояние, что вносит ошибки и размывает границы между лёгкими, умеренными и тяжёлыми формами болезни.
Превращение простых вопросов в надёжные сигналы
Исследователи объединили три существующие голландские выборки, в сумме 498 взрослых, у каждого из которых были ответы на восемь вопросов о здоровье полости рта, базовые данные вроде возраста и пола, а также стандартная оценка состояния дёсен — CPITN. Эта шкала использовалась для разделения людей на три группы: без пародонтита, с умеренным заболеванием и с тяжёлым пародонтитом. Для компьютерных моделей интерес представляли только крайние группы — отсутствие болезни и тяжёлая форма; умеренные случаи были отложены как слишком неоднозначные. Команда затем аккуратно «очистила» данные опросников, например перекодировав участников, заявивших о прохождении лечения дёсен, как имевших пародонтит, даже если они отмечали иное. Также исключали записи, где люди давали одинаковые паттерны ответов, но имели противоречивые клинические ярлыки, рассматривая такие случаи как шумные или ненадёжные.
Построение двухступенчатого умного фильтра
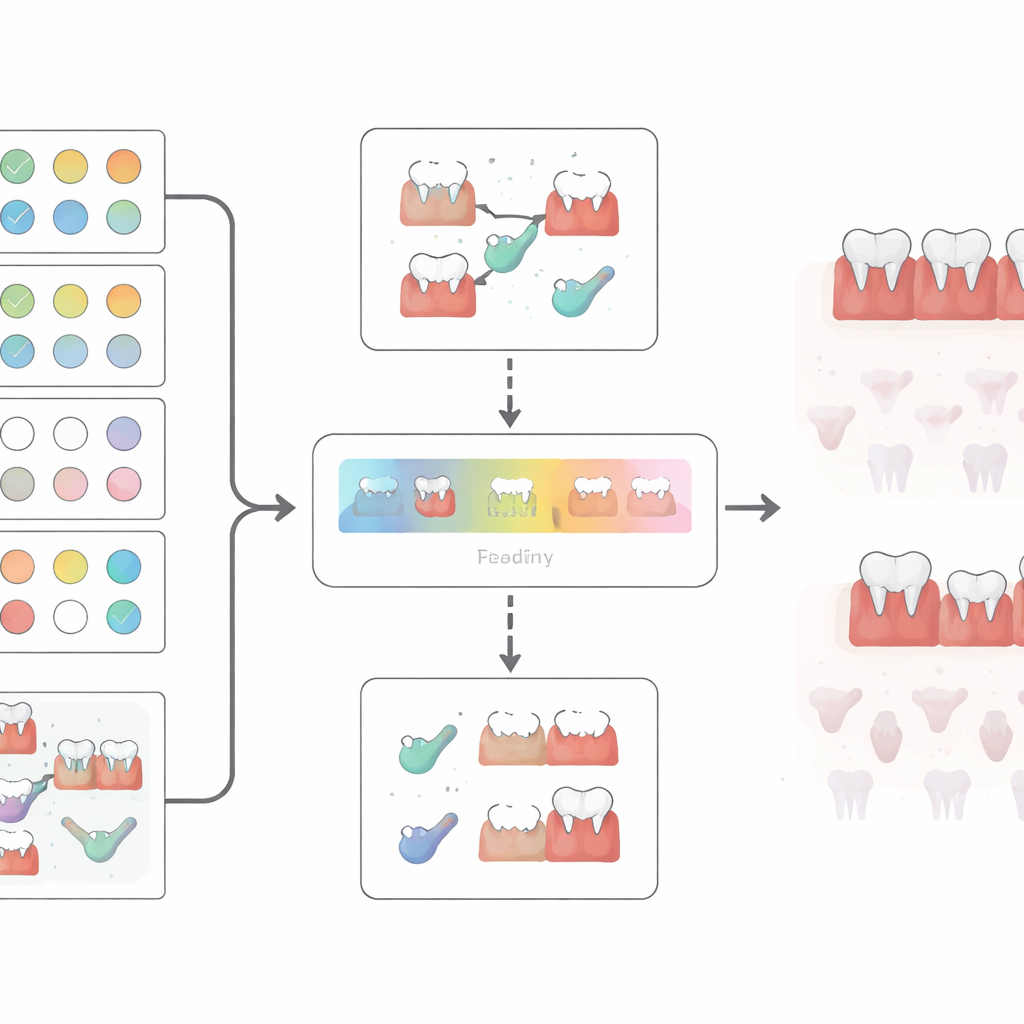
Вместо доверия одной модели авторы создали конвейер из двух этапов. Первая модель, названная Separator-A, просматривала очищенные данные и выдавал первичную вероятность того, что человек, вероятно, имеет тяжёлый пародонтит или не болеет, вместе с оценкой вероятности. Сохранялись только предсказания с очень высокой уверенностью. Из них команда применяла простые экспертные правила, основанные на конкретных вопросах — например, определённые сочетания ответов о «пародонтите» и «лечении дёсен» должны были соответствовать клинической записи — чтобы выделить подмножество явно согласованных случаев. Вторая модель, Separator-Z, затем обучалась только на этом тщательно подобранном подмножестве. Наконец, исследователи определили узкую полосу вероятностей, в которой Separator-Z допускался к принятию решений, и заставляли систему воздерживаться — не присваивать ярлык — за пределами этой полосы, особенно для умеренных случаев, находящихся посередине между здоровьем и тяжёлой болезнью.
Чему компьютер научился о дёснах
После всех фильтраций и правил в окончательную метку с полной уверенностью попали только 12 из 278 подходящих крайних случаев (примерно 4%) — шесть с тяжёлым заболеванием и шесть без болезни. В этой крошечной группе модель разделила два полюса идеально. Наиболее значимыми вопросами оказались: сообщал ли человек о пародонтите (после корректировки), как они оценивали своё общее состояние полости рта и проходили ли лечение дёсен. Эти признаки оставались важными даже после применения более строгих правил, что говорит о том, что восприятие людьми своего состояния дёсен и история лечения могут быть удивительно информативны при аккуратной обработке. Крайне важно, что ни один из умеренных случаев не был ошибочно отнесён ни к явно здоровым, ни к явно тяжело больным внутри выбранной зоны уверенности.
Что это значит для будущих эпидемиологических исследований
Эта работа показывает, что возможно использовать простые самоотчётные опросники в сочетании с целенаправленным конвейером машинного обучения, чтобы надёжно идентифицировать очень небольшое подмножество людей, которые почти наверняка имеют тяжёлый пародонтит или, наоборот, не поражены — без необходимости сажать кого‑то в стоматологическое кресло. Компромисс в том, что алгоритм сознательно игнорирует большую часть участников, действуя скорее как инструмент триажа с высокой точностью, чем как общий скрининг. Это делает его особенно полезным для дорогостоящих последующих исследований, например молекулярных «омикс»-анализов по крови, где исследователям нужны только самые однозначные примеры болезни и здоровья. Авторы предупреждают, что их метод нужно проверять на более крупных и разнообразных популяциях, и он не пригоден для клинической диагностики. Тем не менее подход намекает на более широкое будущее, в котором тщательно спроектированные алгоритмы превращают повседневные опросники в надёжные инструменты для изучения хронических заболеваний в масштабе.
Цитирование: Stamatelou, E., Nijland, N., Su, N. et al. A selective machine learning algorithm for severe periodontitis labeling from questionnaire data. Sci Rep 16, 13422 (2026). https://doi.org/10.1038/s41598-026-43934-6
Ключевые слова: пародонтит, опросы о состоянии полости рта, машинное обучение, эпидемиология, исследования биобанков