Clear Sky Science · en
A selective machine learning algorithm for severe periodontitis labeling from questionnaire data
Why Your Dentist’s Questions Matter
Many large health studies would love to track gum disease, because unhealthy gums are linked to heart problems, diabetes, lung disease, and even COVID-19 complications. But carefully measuring gum health tooth by tooth is slow, expensive, and not always feasible in big population projects. Instead, researchers often rely on simple questionnaires asking people about bleeding gums, loose teeth, or past gum treatments. This study explores whether smart computer methods can reliably use those self-reported answers to pick out people with very severe gum disease and those with no gum disease at all, without doing a full dental exam.
Gum Disease, Health, and the Data Gap
Periodontitis is a chronic infection of the tissues that hold the teeth in place. More than half of adults worldwide are affected, and a substantial fraction have severe forms that can lead to tooth loss and trouble eating. Because gum disease is so common and tied to general health, it is an important target for medical research. Yet many population studies simply do not have the time or funding to perform detailed dental charts. They often record just a brief screening index and a self-reported oral health questionnaire. The challenge is that people may misunderstand questions or rate their own oral health differently, which can introduce errors and blur the line between mild, moderate, and severe disease.
Turning Simple Questions into Reliable Signals
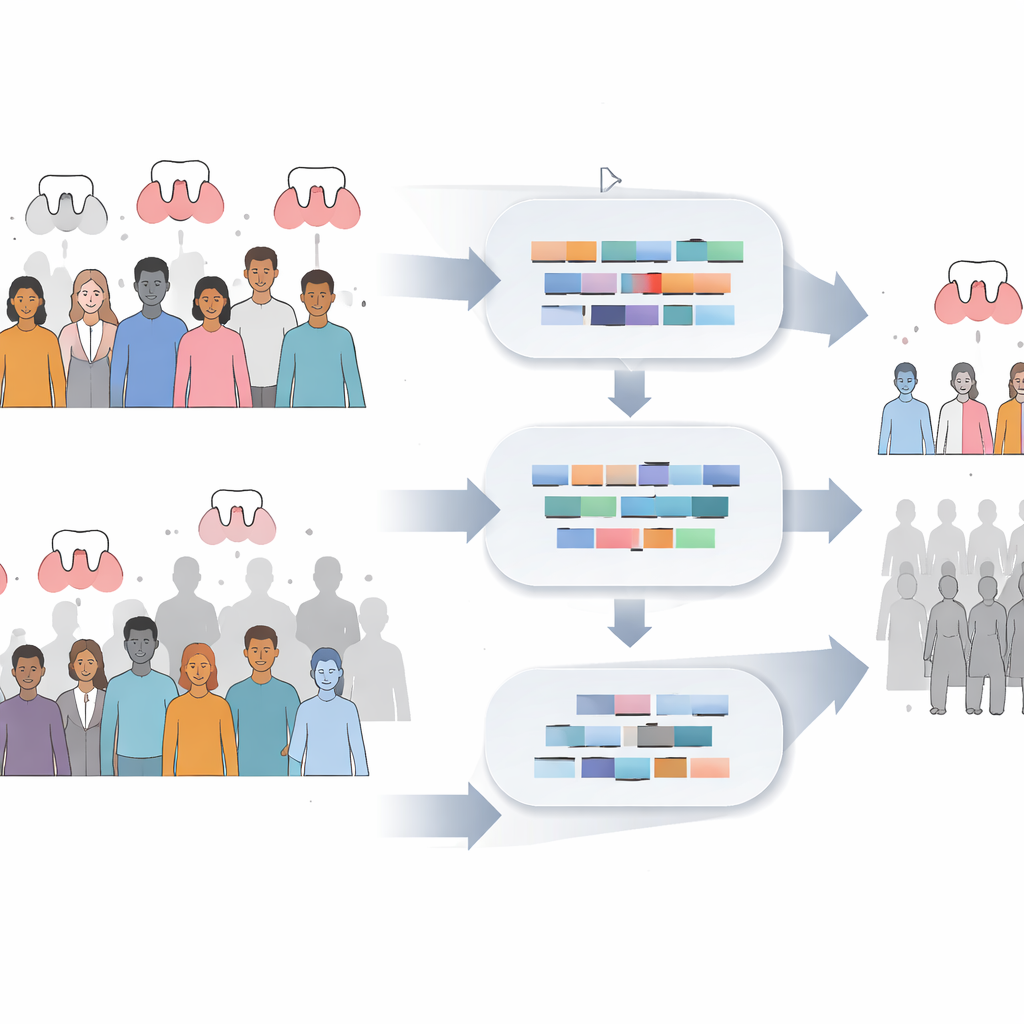
The researchers combined three existing Dutch datasets, totaling 498 adults, each with answers to eight oral-health questions, basic information like age and sex, and a standard gum health score called CPITN. This score was used to sort people into three groups: no periodontitis, moderate disease, and severe disease. For the computer models, only the extremes—no disease and severe disease—were of interest; moderate cases were set aside as too ambiguous. The team then carefully "cleaned" the questionnaire data, for example by recoding someone who reported having gum treatment as also having had gum disease, even if they had checked otherwise. They also excluded records where people gave the same pattern of answers but had conflicting clinical labels, treating those as noisy or unreliable.
Building a Two-Step Smart Filter
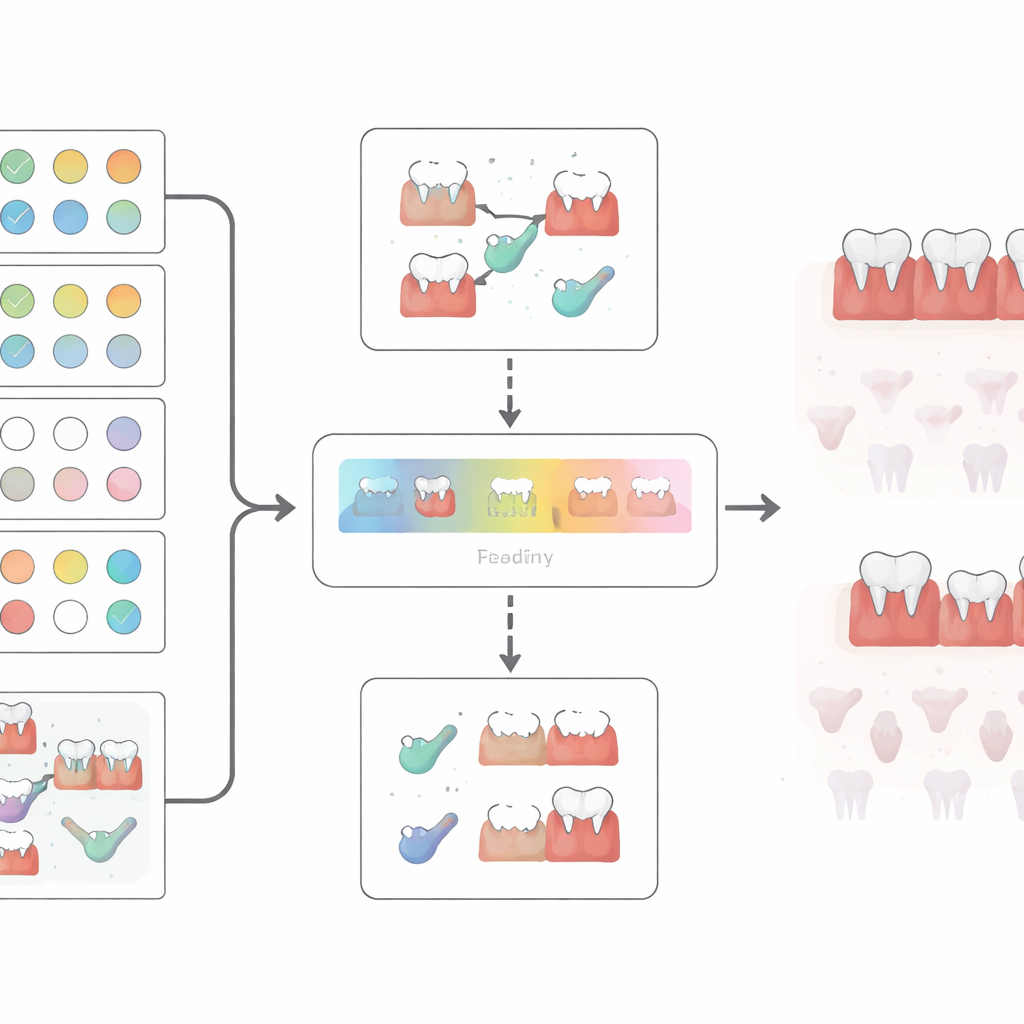
Instead of trusting a single model, the authors created a two-stage pipeline. The first model, called Separator-A, scanned the cleaned data and produced an initial prediction of whether a person likely had severe gum disease or no disease, along with a probability score. Only predictions with very high certainty were kept. From those, the team applied simple expert rules based on specific questions—for instance, certain combinations of “gum disease” and “gum treatment” answers needed to match the clinical record—to carve out a subset of clearly consistent cases. A second model, Separator-Z, was then trained only on this carefully curated subset. Finally, the researchers defined a narrow probability band where Separator-Z was allowed to make decisions and forced the system to abstain—give no label—outside that band, especially for moderate cases that sit between healthy and severely diseased.
What the Computer Learned About Gums
After all the filtering and rule-setting, only 12 out of 278 eligible extreme cases (about 4%) were ultimately labeled with full confidence—six with severe disease and six with no disease. Within that tiny group, the model separated the two ends perfectly. The questions that mattered most were whether a person reported gum disease (after adjustment), how they rated their overall oral health, and whether they had undergone gum treatment. These features remained important even after stricter rules were applied, suggesting that people’s perception of their gum health and treatment history can be surprisingly informative when distilled with care. Crucially, none of the moderate cases were mistakenly classified as either clearly healthy or severely diseased within the chosen confidence zone.
What This Means for Future Health Studies
This work shows that it is possible to use simple self-reported questionnaires, plus a targeted machine-learning pipeline, to reliably identify a very small subset of people who almost certainly have severe gum disease or none at all—without putting anyone in a dental chair. The trade-off is that the algorithm purposely ignores most participants, acting more like a high-precision triage tool than a general screening test. That makes it especially useful for expensive follow-up studies, such as blood-based “omics” analyses, where researchers only want the clearest examples of disease and health. The authors caution that their method needs to be tested in larger and more diverse populations, and it should not be used for clinical diagnosis. Still, the approach hints at a broader future where carefully designed algorithms turn everyday questionnaires into trustworthy tools for studying chronic diseases at scale.
Citation: Stamatelou, E., Nijland, N., Su, N. et al. A selective machine learning algorithm for severe periodontitis labeling from questionnaire data. Sci Rep 16, 13422 (2026). https://doi.org/10.1038/s41598-026-43934-6
Keywords: periodontitis, oral health questionnaires, machine learning, epidemiology, biobank research