Clear Sky Science · ru
К более эффективному устойчивому к утечкам улучшенному приватному объединению множеств
Почему обмен списками может угрожать конфиденциальности
Многие организации хранят чувствительные списки — например подозрительные IP‑адреса, идентификаторы клиентов или участников медицинских исследований — которые они хотели бы совместно объединить со списком другой стороны, не раскрывая собственные данные. Инструмент под названием приватное объединение множеств обещает именно это: он позволяет двум сторонам узнать объединённый список уникальных элементов и ничего больше. Эта статья показывает, что даже передовые версии такого инструмента могут незаметно протекать дополнительную информацию во время выполнения, и предлагает новую конструкцию, которая сохраняет преимущества, но существенно снижает эти скрытые риски и вычислительные затраты.
Что пытается защитить приватное объединение множеств
Представьте две компании, сравнивающие черные списки кибератак. Каждая хочет получить полный список всех подозрительных IP‑адресов, замеченных любой из сторон, чтобы лучше защищать свои сети. В то же время методы обнаружения каждой компании — а значит и её точный черный список — являются коммерческой тайной. Если можно узнать, какие адреса есть или отсутствуют у другой стороны, это может раскрыть эти методы. Классические протоколы приватного объединения множеств уже скрывают прямое пересечение списков, но недавние исследования показали, что они всё ещё могут выдавать подсказки во время вычисления или через закономерности в размещении элементов во внутренних структурах данных.
Скрытые утечки в ранних быстрых методах
Ранее масштабируемые схемы опирались на рецепт, который сначала проверял поэлементно, присутствует ли каждый элемент из одного списка в другом, а затем использовал эти ответы, чтобы отдать только «новые» элементы. Позднейшие работы показали, что этот процесс по сути выдаёт, ещё до завершения протокола, сколько элементов списки имеют общего. Любопытный участник может воспользоваться этим, прервать и повторно запустить протокол с слегка изменёнными входными данными, постепенно выясняя, какие именно элементы совпадают. Другие быстрые схемы использовали хеширование — размещение элементов по корзинам в соответствии с хеш‑функцией — для организации данных. Как только одна сторона узнаёт, какие из объектов другой стороны уникальны, она может сопоставить шаблон заполненных и пустых корзин и вывести, какие из собственных элементов определённо отсутствуют в другом списке — форма утечки, основанной на хешировании.
Блокировка элементов за случайными масками
Новый протокол решает обе эти проблемы одновременно. До любого хеширования каждая сторона выполняет криптографический обмен, который превращает каждый элемент в случайно выглядящий маркер. Важное свойство: одинаковые элементы из двух списков преобразуются в одинаковые маркеры, в то время как разные элементы дают несвязанные маркеры — и ни одна сторона не получает секретный ключ, позволяющий связать маркеры с реальными значениями. Эти замаскированные маркеры затем размещаются в хеш‑таблицах и проходят через серию тщательно структурированных рандомизированных шагов, которые фактически решают, совпадают ли маркеры, не раскрывая при этом, какой маркер в какой корзине. Повторение этого процесса с новой случайностью при каждом выполнении предотвращает корреляцию информации между запусками и затрудняет атаку по нескольким исполнениям.
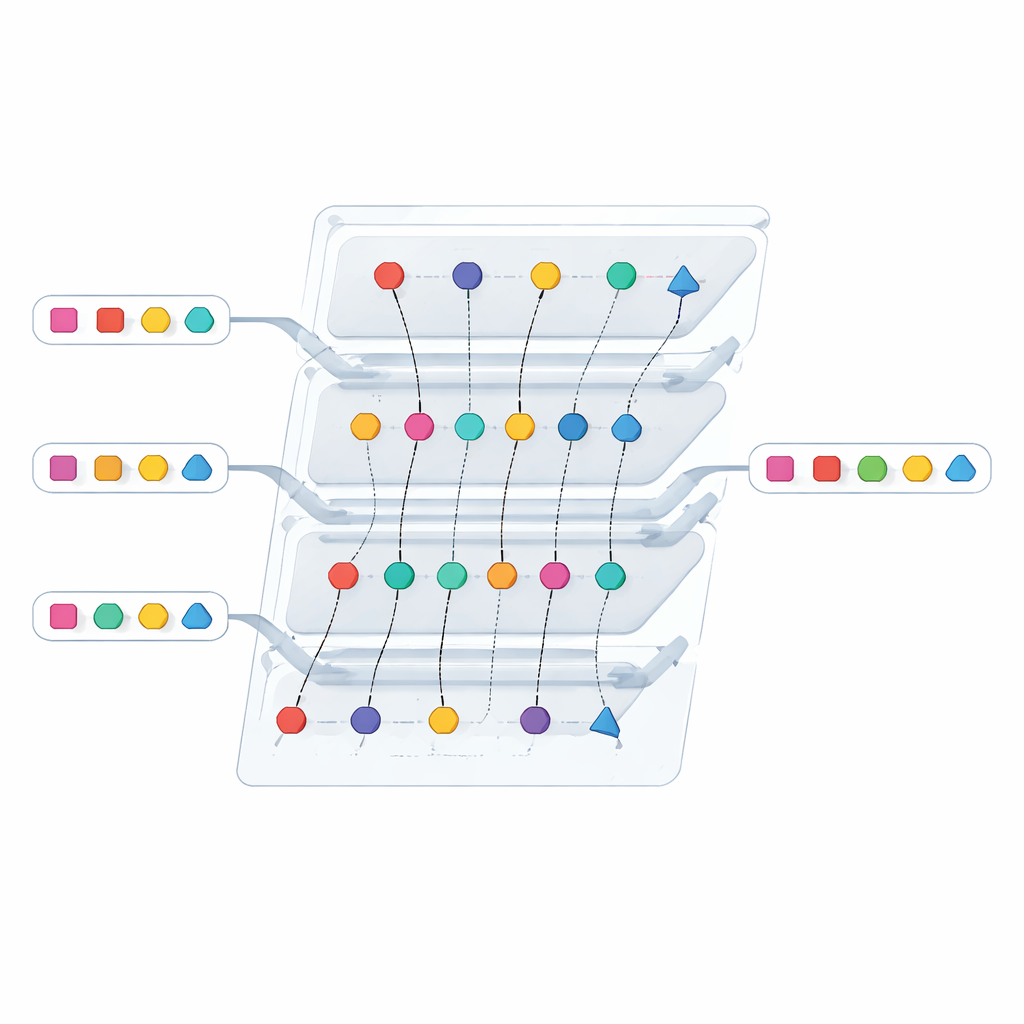
Снижение затрат с помощью более умной структуры данных
Безопасности недостаточно, если протокол слишком тяжёл для применения в масштабе. Авторы поэтому переработали один из самых ресурсоёмких компонентов: внутренний модуль, который ранее полагался на пакетный криптографический примитив для сравнения многих элементов одновременно. Они заменили его «двунаправленным» невидимым хранилищем ключ–значение, компактной структурой, которая позволяет одной стороне кодировать пары ключ–значение так, чтобы другая могла запрашивать их, не узнавая ничего, кроме факта присутствия ключа. Размещая две такие кодировки, взаимодействующие друг с другом, протокол может определить, когда маркеры совпадают между списками, избегая работы по пустым или фиктивным корзинам. Это изменение сокращает как объём передаваемых данных, так и время вычислений, особенно для больших списков.
Что показывают эксперименты на практике
Чтобы проверить свои идеи, авторы реализовали протокол и сравнили его с лучшей существующей конструкцией улучшенного приватного объединения множеств при тех же, более строгих целях приватности. По широкому диапазону размеров списков и сетевых условий их метод последовательно снижал объём коммуникаций примерно в 1.1–3 раза и ускорял время выполнения примерно в 1.0–1.7 раза. Что важно, эти преимущества сохраняются даже после добавления дополнительного криптографического слоя, предотвращающего утечки, основанные на хешировании, которые прежние эффективные схемы игнорировали. Результаты свидетельствуют о том, что более сильная защита не обязательно связана с большой потерей производительности.
Почему это важно для реального обмена данными
Проще говоря, эта работа показывает, как две стороны могут объединять чувствительные списки, резко ограничивая то, что каждая может вывести о данных другой — даже по тонким побочным эффектам во время протокола. Замаскировывая элементы перед хешированием и используя более экономные внутренние структуры, новая конструкция закрывает известные каналы утечек и остаётся достаточно быстрой для очень больших наборов данных. Это делает приватное объединение черных списков, идентификаторов клиентов или других идентификаторов более практичным для компаний и учреждений, которым нужно сотрудничать, не раскрывая структуру собственных данных.
Цитирование: Liu, Q., Bae, J. & Lee, JW. Towards an improved efficient leakage-resilient enhanced private set union. Sci Rep 16, 10134 (2026). https://doi.org/10.1038/s41598-026-40531-5
Ключевые слова: приватное объединение множеств, конфиденциальность данных, криптографические протоколы, безопасный обмен данными, устойчивость к утечкам