Clear Sky Science · pl
W kierunku ulepszonego, efektywnego i odpornrego na wycieki rozszerzonego łączenia zbiorów prywatnych
Dlaczego udostępnianie list może zagrażać prywatności
Wiele organizacji przechowuje wrażliwe listy — na przykład podejrzane adresy IP, identyfikatory klientów czy uczestników badań medycznych — które chciałyby połączyć z listą drugiej strony, nie ujawniając własnych danych. Narzędzie zwane łączeniem zbiorów prywatnych (private set union) obiecuje właśnie to: pozwala dwóm stronom poznać połączoną listę unikalnych elementów i nic poza tym. W artykule pokazano, że nawet najnowocześniejsze wersje tego narzędzia mogą po cichu ujawniać dodatkowe informacje podczas działania, oraz przedstawiono nowy projekt, który zachowuje korzyści, jednocześnie znacząco zmniejszając te ukryte ryzyka i koszty obliczeniowe.
Co łączenie zbiorów prywatnych ma chronić
Wyobraźmy sobie dwie firmy porównujące czarne listy ataków sieciowych. Każda chce uzyskać pełną listę wszystkich podejrzanych adresów IP widzianych przez którąkolwiek stronę, aby lepiej bronić sieci. Jednocześnie metody wykrywania każdej firmy — a zatem jej dokładna czarna lista — są tajemnicą handlową. Jeśli dałoby się wywnioskować, które adresy posiada druga strona lub których nie posiada, można by odkryć te metody. Klasyczne protokoły łączenia zbiorów prywatnych już ukrywają bezpośrednią część wspólną list, ale ostatnie badania wykazały, że mogą one nadal ujawniać wskazówki w trakcie obliczeń albo przez wzory w rozmieszczeniu elementów wewnątrz struktur danych.
Ukryte wycieki we wcześniejszych szybkich metodach
Wcześniejsze skalowalne schematy opierały się na procedurze, która najpierw sprawdzała element po elemencie, czy każdy element z jednej listy pojawia się w drugiej, a potem używała tych odpowiedzi, by przekazać tylko „nowe” elementy. Późniejsze prace pokazały, że ten proces z natury ujawnia, zanim protokół się zakończy, ile elementów listy mają wspólnych. Ciekawski uczestnik może to wykorzystać, przerywając i ponownie uruchamiając protokół z nieznacznie zmodyfikowanymi wejściami, stopniowo dowiadując się, które konkretnie elementy pokrywają się. Inne szybkie schematy używały haszowania — umieszczania elementów w kubełkach według funkcji haszującej — do organizacji danych. Gdy jedna strona dowiaduje się, które z elementów drugiej strony są unikalne, może skros-sprawdzić wzór zapełnionych i pustych kubełków, by odgadnąć, które z jej własnych elementów na pewno nie występują w drugiej liście — to forma wycieku opartego na haszowaniu.
Zamykanie elementów za losowymi przebraniami
Nowy protokół przeciwdziała obu tym problemom jednocześnie. Zanim nastąpi jakiekolwiek haszowanie, każda strona przeprowadza wymianę kryptograficzną, która zamienia każdy element w losowo wyglądający token. Kluczową własnością jest to, że identyczne elementy z obu list zamieniają się w identyczne tokeny, podczas gdy różne elementy dają niezwiązane tokeny — i żadna ze stron nie poznaje sekretnego klucza łączącego tokeny z rzeczywistymi wartościami. Te ukryte tokeny są następnie umieszczane w tabelach opartych na haszowaniu i przechodzą przez serię starannie ustrukturyzowanych, zrandomizowanych kroków, które w efekcie decydują, czy tokeny pasują, bez ujawniania, który token znajduje się w którym kubełku. Powtarzanie tego procesu z nową losowością przy każdym uruchomieniu uniemożliwia atakującemu korelowanie informacji między kolejnymi wykonaniami.
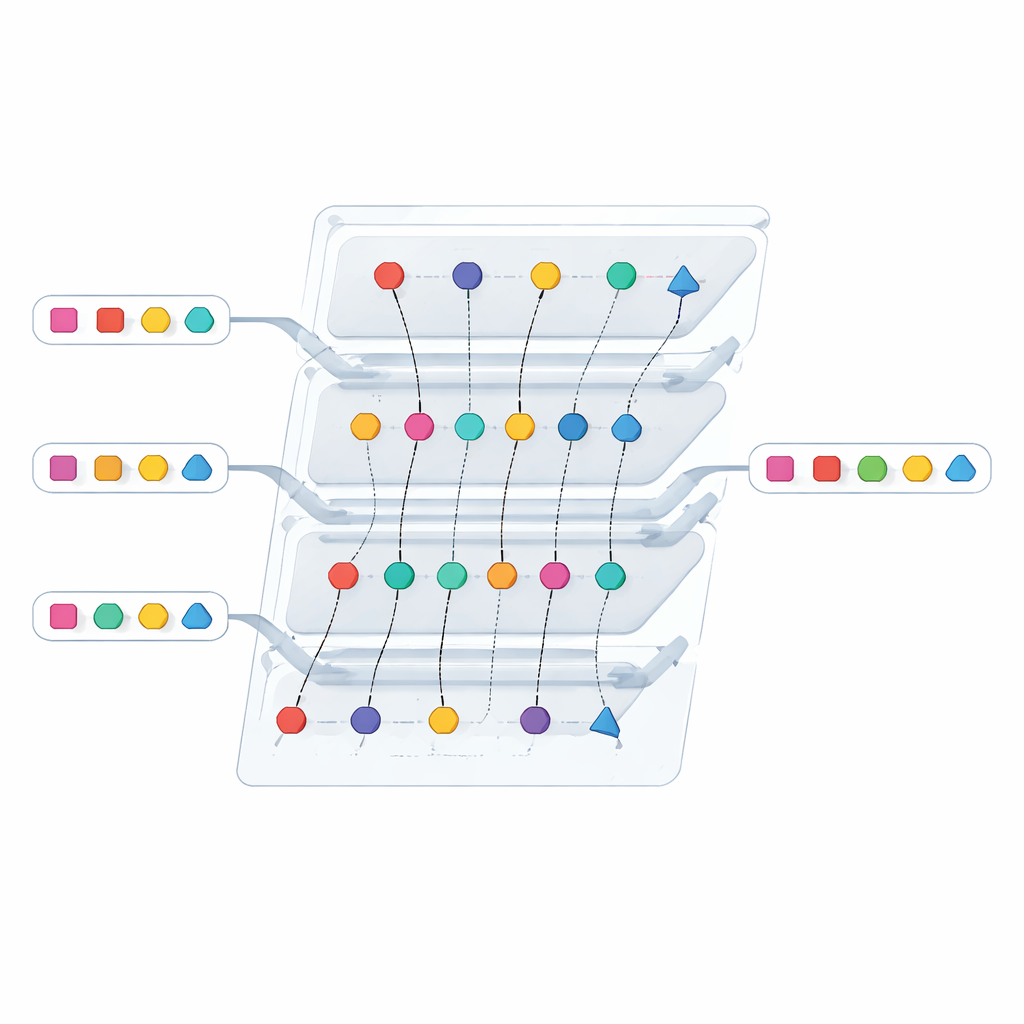
Obniżenie kosztów dzięki sprytniejszej strukturze danych
Bezpieczeństwo samo w sobie nie wystarczy, jeśli protokół jest zbyt ciężki do zastosowania w skali. Autorzy przeprojektowali więc jeden z najbardziej kosztownych komponentów: moduł wewnętrzny, który wcześniej opierał się na zbiorczym prymitywie kryptograficznym do porównywania wielu elementów naraz. Zastąpili go „dwukierunkowym” niejawnego magazynem par klucz–wartość (oblivious key‑value store), zwartą strukturą pozwalającą jednej stronie zakodować pary klucz–wartość tak, że druga może je zapytać, nie dowiadując się niczego poza tym, czy dany klucz występuje. Układając dwie takie kodowania w relację wzajemną, protokół może wykryć, kiedy tokeny pokrywają się między dwiema listami, unikając pracy na pustych lub falszywych kubełkach. Ta zmiana znacząco zmniejsza zarówno ilość danych przesyłanych przez sieć, jak i czas obliczeń, zwłaszcza dla dużych list.
Co pokazują eksperymenty w praktyce
Aby przetestować swoje pomysły, autorzy zaimplementowali protokół i porównali go z najlepszym istniejącym projektem rozszerzonego łączenia zbiorów prywatnych przy tych samych, bardziej rygorystycznych celach prywatności. W szerokim zakresie rozmiarów list i warunków sieciowych ich metoda konsekwentnie zmniejszała komunikację o około 1,1–3 razy i przyspieszała czas działania o około 1,0–1,7 razy. Co ważne, te korzyści utrzymują się nawet po dodaniu dodatkowej warstwy kryptograficznej, która zapobiega wyciekom opartym na haszowaniu — czynnikowi, który wcześniejsze wydajne schematy pomijały. Wyniki sugerują, że silniejsza ochrona nie musi iść w parze z dużą utratą wydajności.
Dlaczego to ma znaczenie dla rzeczywistej wymiany danych
Mówiąc prosto, praca ta pokazuje, jak dwie strony mogą połączyć wrażliwe listy, znacznie ograniczając to, co każda może wywnioskować o danych drugiej strony — nawet z subtelnych efektów ubocznych podczas protokołu. Poprzez ukrywanie elementów przed haszowaniem i użycie oszczędniejszych struktur wewnętrznych, nowy projekt zamyka znane kanały wycieków i pozostaje wystarczająco szybki dla bardzo dużych zbiorów danych. To sprawia, że prywatne łączenie czarnych list, identyfikatorów klientów czy innych identyfikatorów jest bardziej praktyczne dla firm i instytucji, które muszą współpracować, nie ujawniając jednocześnie struktury własnych danych.
Cytowanie: Liu, Q., Bae, J. & Lee, JW. Towards an improved efficient leakage-resilient enhanced private set union. Sci Rep 16, 10134 (2026). https://doi.org/10.1038/s41598-026-40531-5
Słowa kluczowe: łączenie zbiorów prywatnych, prywatność danych, protokoły kryptograficzne, bezpieczne udostępnianie danych, odporność na wycieki