Clear Sky Science · it
Verso un union privata migliorata ed efficiente, resistente alle fughe di informazioni
Perché condividere elenchi può mettere a rischio la privacy
Molte organizzazioni conservano elenchi sensibili — come indirizzi IP sospetti, ID clienti o partecipanti a studi medici — che vorrebbero combinare con l’elenco di un’altra parte senza esporre i propri dati. Uno strumento chiamato unione insiemi privata promette esattamente questo: permette a due parti di apprendere l’elenco combinato degli elementi unici, ma nulla di più. Questo articolo mostra che anche le versioni più avanzate di questo strumento possono silenziosamente perdere informazioni durante l’esecuzione, e introduce un nuovo progetto che mantiene i benefici riducendo nettamente questi rischi nascosti e il costo computazionale.
Ciò che l’unione insiemi privata cerca di proteggere
Immaginate due aziende che confrontano blacklist di attacchi informatici. Ciascuna vuole ottenere l’elenco completo di tutti gli indirizzi IP sospetti rilevati da entrambe, per difendere meglio le proprie reti. Allo stesso tempo, i metodi di rilevamento di ciascuna azienda — e quindi la sua blacklist esatta — sono segreti commerciali. Se si potesse dedurre quali indirizzi l’altra parte possiede o non possiede, si rischierebbe di scoprire quei metodi. I protocolli classici di unione insiemi privata già nascondono l’intersezione diretta tra gli elenchi, ma ricerche recenti hanno rivelato che possono comunque rivelare indizi durante il calcolo stesso o attraverso schemi nel modo in cui gli elementi sono disposti nelle strutture dati interne.
Fughe nascoste nei metodi rapidi precedenti
I precedenti schemi scalabili si basavano su una procedura che verificava, elemento per elemento, se ogni elemento di un elenco appariva nell’altro, e poi usava quelle risposte per fornire solo gli elementi “nuovi”. Lavori successivi hanno mostrato che questo processo rivela intrinsecamente, prima che il protocollo finisca, quanti elementi gli elenchi condividono. Un partecipante curioso può sfruttare questo abortendo e rieseguendo il protocollo con input leggermente modificati, apprendere gradualmente quali elementi specifici si sovrappongono. Altri schemi veloci usavano l’hashing — collocando gli elementi in “bin” secondo una funzione di hash — per organizzare i dati. Una volta che una parte apprende quali degli elementi dell’altra sono unici, può incrociare il modello di bin pieni e vuoti per dedurre quali dei propri elementi sicuramente non compaiono nell’altro elenco, una forma di perdita informativa «basata su hash».
Bloccare gli elementi dietro travestimenti casuali
Il nuovo protocollo affronta entrambi i problemi contemporaneamente. Prima che avvenga qualsiasi hashing, ciascuna parte esegue uno scambio crittografico che trasforma ogni elemento in un token dall’aspetto casuale. La proprietà cruciale è che elementi identici nei due elenchi vengono trasformati in token identici, mentre elementi diversi producono token non correlati — e nessuna delle parti apprende la chiave segreta che collega i token ai valori reali. Questi token camuffati vengono quindi posizionati in tabelle basate su hash e fatti passare attraverso una serie di passaggi casualizzati e strutturati con cura che decidono, di fatto, se i token corrispondono, senza rivelare quale token si trova in quale bin. Ripetere questo processo con nuova casualità a ogni esecuzione impedisce a un attaccante di correlare informazioni tra più esecuzioni.
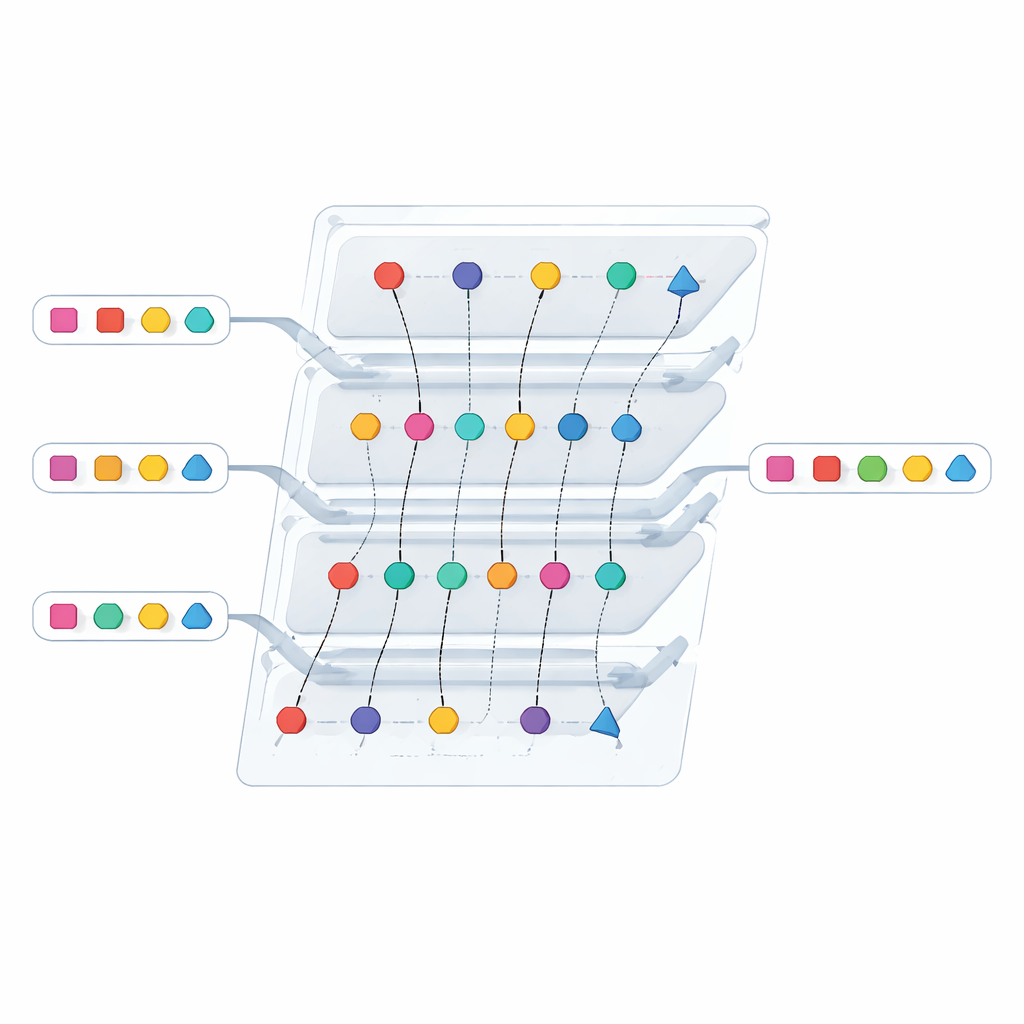
Ridurre i costi con una struttura dati più intelligente
La sicurezza da sola non basta se un protocollo è troppo pesante per essere usato su larga scala. Gli autori ridisegnano quindi uno dei componenti più costosi: un modulo interno che prima si basava su un primitivo crittografico in batch per confrontare molti elementi contemporaneamente. Lo sostituiscono con un archivio chiave‑valore obliquo «bidirezionale», una struttura compatta che permette a una parte di codificare coppie chiave‑valore in modo che l’altra possa interrogarle senza apprendere nulla oltre alla presenza di una chiave. Disponendo due di queste codifiche in modo che interagiscano tra loro, il protocollo può rilevare quando i token si allineano tra i due elenchi evitando lavoro su bin vuoti o fittizi. Questo cambiamento riduce drasticamente sia la quantità di dati inviati in rete sia il tempo di calcolo, specialmente per elenchi di grandi dimensioni.
Cosa mostrano gli esperimenti nella pratica
Per mettere alla prova le loro idee, gli autori hanno implementato il protocollo e lo hanno confrontato con il miglior progetto esistente di unione insiemi privata avanzata sotto gli stessi obiettivi di privacy più rigorosi. Su un’ampia gamma di dimensioni degli elenchi e condizioni di rete, il loro metodo ha ridotto costantemente la comunicazione di circa 1,1–3 volte e ha accelerato i tempi di esecuzione di circa 1,0–1,7 volte. È importante notare che questi miglioramenti valgono anche dopo l’aggiunta dello strato crittografico extra che impedisce le fughe basate su hash, che gli schemi efficienti precedenti avevano trascurato. I risultati suggeriscono che una protezione più forte non deve necessariamente comportare un grande peggioramento delle prestazioni.
Perché questo conta per la condivisione reale dei dati
In termini semplici, questo lavoro mostra come due parti possano combinare elenchi sensibili limitando fortemente ciò che ciascuna può inferire sui dati dell’altra — anche a partire da effetti collaterali sottili durante il protocollo. Travestendo gli elementi prima dell’hashing e utilizzando strutture interne più parsimoniose, il nuovo progetto chiude i canali di perdita noti e resta sufficientemente veloce per set di dati molto grandi. Ciò rende più pratica l’unione che preserva la privacy di blacklist, ID clienti o altri identificatori per aziende e istituzioni che devono collaborare senza esporre i pattern nei propri dati.
Citazione: Liu, Q., Bae, J. & Lee, JW. Towards an improved efficient leakage-resilient enhanced private set union. Sci Rep 16, 10134 (2026). https://doi.org/10.1038/s41598-026-40531-5
Parole chiave: unione insiemi privata, privacy dei dati, protocolli crittografici, condivisione sicura dei dati, resilienza alle fughe di informazioni