Clear Sky Science · de
Auf dem Weg zu einer verbesserten effizienten ausfallsicheren erweiterten privaten Mengenvereinigung
Warum das Teilen von Listen die Privatsphäre bedrohen kann
Viele Organisationen führen sensible Listen — etwa verdächtige IP‑Adressen, Kundenkennungen oder Teilnehmende medizinischer Studien — die sie mit einer Liste einer anderen Partei zusammenführen möchten, ohne die eigenen Daten offenzulegen. Ein Werkzeug namens private Mengenvereinigung verspricht genau das: Es erlaubt zwei Seiten, die kombinierte Liste eindeutiger Elemente zu erfahren, aber nichts darüber hinaus. Dieser Beitrag zeigt, dass selbst moderne Varianten dieses Werkzeugs während ihrer Ausführung unbemerkt zusätzliche Informationen preisgeben können, und stellt ein neues Design vor, das die Vorteile erhält und gleichzeitig diese versteckten Risiken sowie die Rechenkosten deutlich reduziert.
Was die private Mengenvereinigung schützen will
Stellen Sie sich zwei Unternehmen vor, die ihre Blacklists für Cyberangriffe vergleichen. Beide wollen am Ende die vollständige Liste aller verdächtigen IP‑Adressen haben, die von einer der Seiten beobachtet wurden, um ihre Netzwerke besser zu schützen. Gleichzeitig sind die Erkennungsmethoden — und damit die exakte Blacklist — jeder Firma Geschäftsgeheimnisse. Könnte man ableiten, welche Adressen die andere Seite hat oder nicht hat, könnten daraus Rückschlüsse auf diese Methoden gezogen werden. Klassische Protokolle zur privaten Mengenvereinigung verbergen bereits die direkte Überschneidung der Listen, aber neuere Forschung hat gezeigt, dass sie während der Berechnung selbst oder durch Muster in der Anordnung von Elementen in internen Datenstrukturen noch Hinweise preisgeben können.
Versteckte Lecks in frühen schnellen Methoden
Frühere skalierbare Verfahren beruhten auf einer Vorgehensweise, die zunächst elementweise prüfte, ob jedes Element aus der einen Liste in der anderen vorkommt, und diese Antworten dann nutzte, um nur die „neuen“ Elemente zu liefern. Spätere Arbeiten zeigten, dass dieser Prozess von Natur aus bereits vor Abschluss des Protokolls offenlegt, wie viele Elemente die Listen gemeinsam haben. Ein neugieriger Teilnehmer kann dies ausnutzen, indem er das Protokoll abbricht und mit leicht veränderten Eingaben neu startet und so schrittweise herausfindet, welche konkreten Elemente übereinstimmen. Andere schnelle Verfahren verwendeten Hashing — also das Einordnen von Elementen in Buckets nach einer Hashfunktion — zur Organisation der Daten. Sobald eine Partei erkennt, welche Elemente der anderen einzigartig sind, kann sie das Muster gefüllter und leerer Buckets abgleichen, um zu erschließen, welche ihrer eigenen Elemente definitiv nicht in der anderen Liste vorkommen, eine Form der "hashbasierten" Leckage.
Elemente hinter zufälligen Verkleidungen verbergen
Das neue Protokoll begegnet beiden Problemen gleichzeitig. Noch bevor gehasht wird, führen beide Parteien einen kryptographischen Austausch durch, der jedes Element in ein zufällig aussehendes Token verwandelt. Die entscheidende Eigenschaft ist, dass identische Elemente aus beiden Listen in identische Token überführt werden, während verschiedene Elemente zu unabhängigen Token führen — und keine Seite den geheimen Schlüssel erfährt, der Token wieder in reale Werte zurückführt. Diese verkleideten Token werden dann in hashbasierten Tabellen abgelegt und durch eine Reihe sorgfältig strukturierter, randomisierter Schritte geschickt, die im Wesentlichen entscheiden, ob Token übereinstimmen, ohne offenzulegen, welches Token in welchem Bucket sitzt. Die Wiederholung dieses Prozesses mit frischer Zufälligkeit in jedem Durchlauf verhindert, dass ein Angreifer Informationen über mehrere Ausführungen hinweg korreliert.
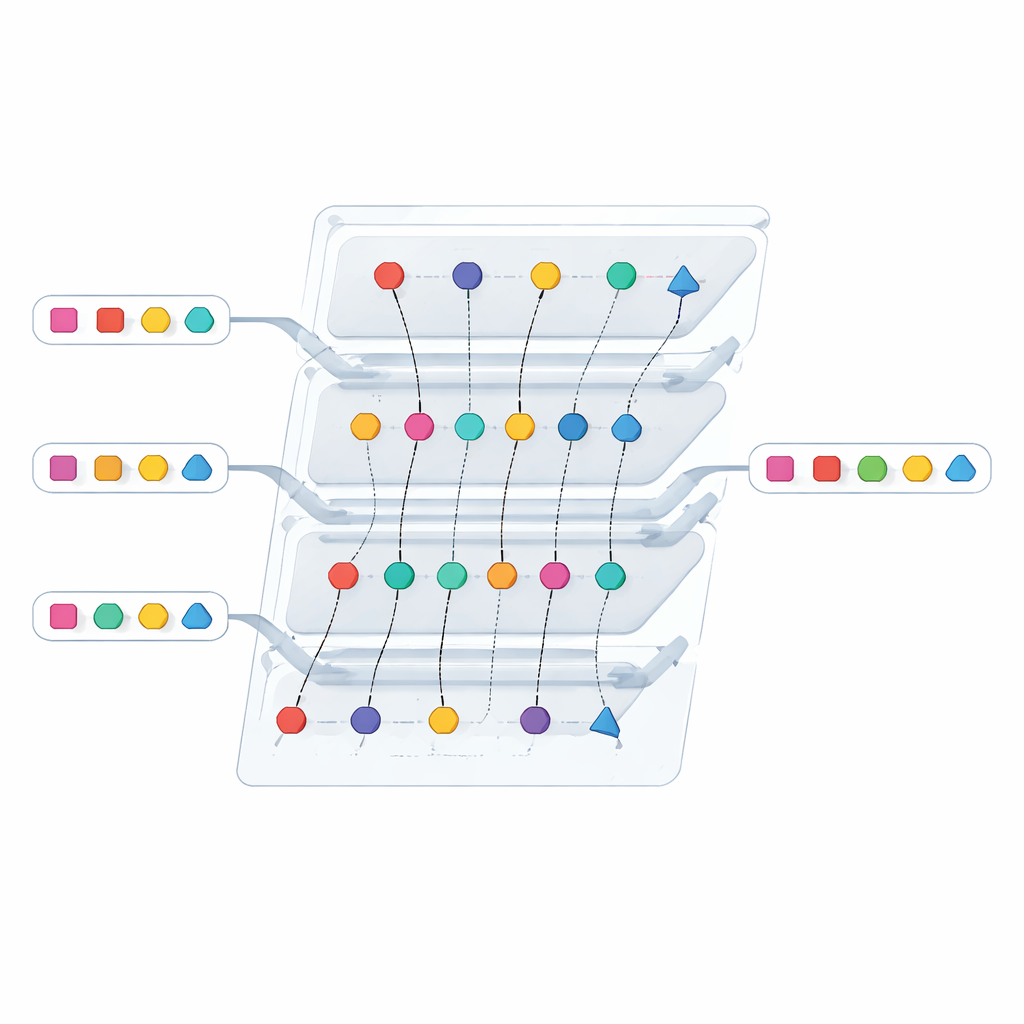
Kostensenkung durch eine intelligentere Datenstruktur
Allein Sicherheit genügt nicht, wenn ein Protokoll zu schwerfällig für den Einsatz im großen Maßstab ist. Die Autoren überarbeiten daher eine der teuersten Komponenten: ein internes Modul, das zuvor auf einem gebündelten kryptographischen Primitive basierte, um viele Elemente gleichzeitig zu vergleichen. Sie ersetzen es durch einen "bidirektionalen" obliviousen Schlüssel‑Wert‑Speicher, eine kompakte Struktur, mit der eine Partei Schlüssel–Wert‑Paare so kodieren kann, dass die andere abfragen kann, ohne etwas darüber zu lernen außer der Anwesenheit eines Schlüssels. Indem zwei solche Kodierungen gegeneinander angeordnet werden, kann das Protokoll feststellen, wann Token zwischen den beiden Listen übereinstimmen, und gleichzeitig Arbeit an leeren oder Dummy‑Buckets vermeiden. Diese Änderung reduziert sowohl die über das Netz gesendeten Daten als auch die Rechenzeit, insbesondere bei großen Listen.
Was die Experimente in der Praxis zeigen
Zur Überprüfung ihrer Ideen implementierten die Autoren ihr Protokoll und verglichen es mit dem besten vorhandenen Entwurf für eine erweiterte private Mengenvereinigung unter denselben, strengeren Datenschutzzielen. Über eine breite Palette von Listengrößen und Netzwerkbedingungen hinweg reduzierte ihre Methode konsistent die Kommunikation um etwa das 1,1‑ bis 3‑Fache und beschleunigte die Laufzeit um ungefähr das 1,0‑ bis 1,7‑Fache. Wichtig ist, dass diese Verbesserungen auch nach Hinzufügen der zusätzlichen kryptographischen Schicht gelten, die hashbasierte Leckage verhindert — eine Schicht, die frühere effiziente Verfahren oft vernachlässigten. Die Ergebnisse deuten darauf hin, dass stärkere Schutzmaßnahmen nicht zwangsläufig mit einem großen Leistungsverlust einhergehen müssen.
Warum das für den realen Datenaustausch wichtig ist
Kurz gesagt zeigt diese Arbeit, wie zwei Parteien sensible Listen kombinieren können, während sie deutlich einschränken, was jede Seite über die Daten der anderen ableiten kann — selbst aus subtilen Nebeneffekten während des Protokolls. Durch das Verkleiden von Elementen vor dem Hashing und die Verwendung sparsamerer interner Strukturen schließt das neue Design bekannte Leckkanäle und bleibt schnell genug für sehr große Datensätze. Das macht die datenschutzschonende Vereinigung von Blacklists, Kundenkennungen oder anderen Identifikatoren praktischer für Unternehmen und Institutionen, die zusammenarbeiten müssen, ohne die Muster in ihren eigenen Daten offenzulegen.
Zitation: Liu, Q., Bae, J. & Lee, JW. Towards an improved efficient leakage-resilient enhanced private set union. Sci Rep 16, 10134 (2026). https://doi.org/10.1038/s41598-026-40531-5
Schlüsselwörter: private Mengenvereinigung, Datenprivatsphäre, kryptographische Protokolle, sicherer Datenaustausch, Leckresistenz