Clear Sky Science · pt
Um argumento teórico-informacional para a restrição dos alfabetos biológicos atuais a 4 nucleotídeos e 20 aminoácidos
Por que os pequenos alfabetos da vida importam
Toda a vida na Terra escreve seus “textos” genéticos e proteicos usando alfabetos surpreendentemente pequenos: apenas quatro letras químicas para DNA e RNA, e vinte para proteínas. Os químicos podem conceber muitos mais blocos de construção, então por que a biologia se restringe a esses conjuntos? Este artigo argumenta que a resposta está em quão facilmente essas moléculas conseguem dobrar-se em formas úteis e em quão eficientemente a evolução pode percorrer todas as sequências possíveis. Ao conectar ideias da física e da teoria da informação, os autores mostram que os alfabetos familiares da vida são apenas grandes o suficiente para que as moléculas dobrem de forma confiável e ainda sejam evoluíveis.
De cordas emaranhadas a formas úteis
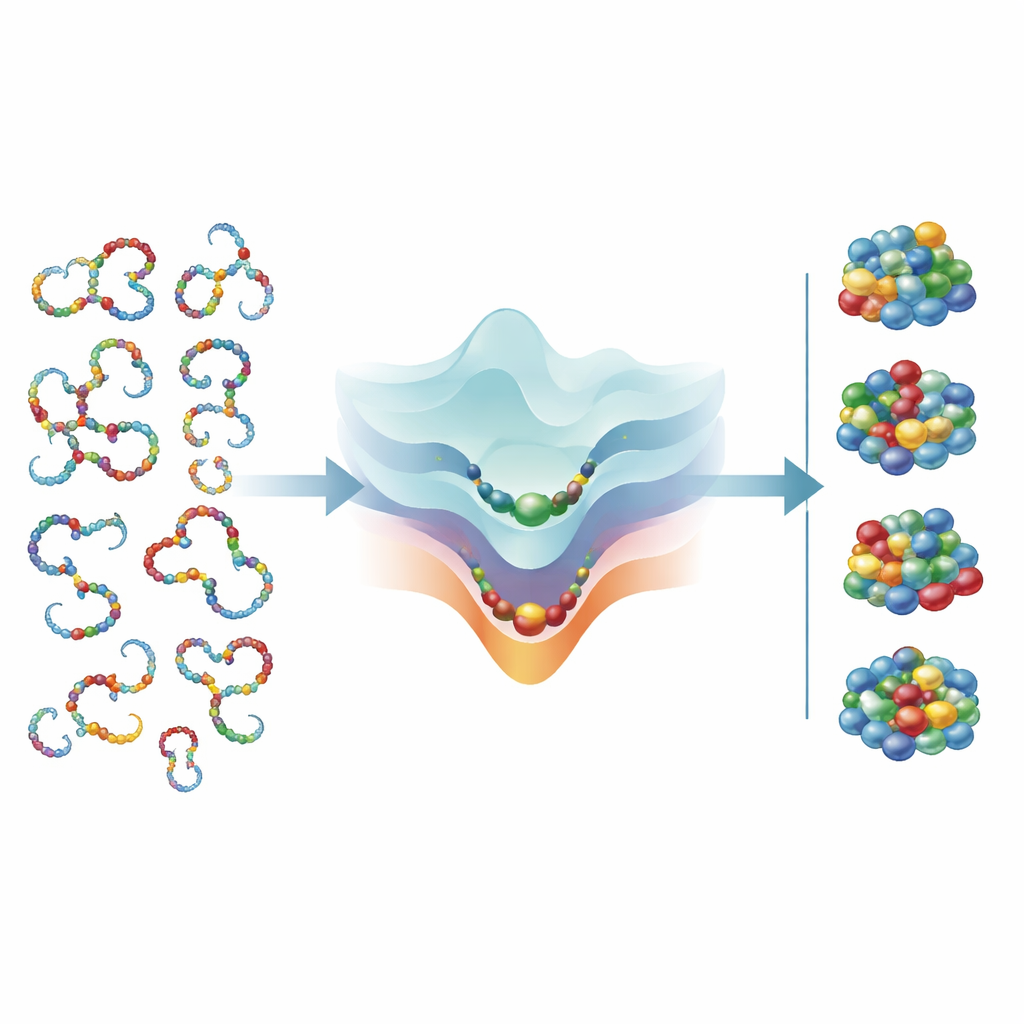
Proteínas e RNA começam como cadeias flexíveis que oscilam por inúmeras formas possíveis. Apenas uma fração minúscula dessas conformações é estável e funcional. Para que a vida funcione, uma cadeia deve encontrar rapidamente sua forma dobrada correta sem testar todas as possibilidades ao acaso. Os autores usam uma lente da teoria da informação: quando uma cadeia dobra, ela “ganha informação” ao selecionar uma forma nativa entre muitas alternativas. Esse ganho pode ser medido por quanto o conjunto de formas possíveis se reduz por posição ao longo da cadeia. Eles comparam isso com a informação obtida quando a evolução filtra sequências aleatórias até aquelas que realmente dobram, mostrando que ambos os processos precisam estar em equilíbrio para que o dobramento seja rápido e confiável.
Casando letras digitais com movimentos físicos
O insight-chave é um elo matemático simples entre três coisas: o tamanho do alfabeto químico, quantas formas cada posição de uma cadeia não dobrada pode adotar e quantos blocos de construção diferentes efetivamente aparecem naquela posição em moléculas reais e evoluídas. Para um polímero que dobra para uma estrutura bem definida, a teoria prevê que o número de conformações acessíveis na cadeia não dobrada por posição e a diversidade efetiva de “letras” usadas ali devem ser aproximadamente iguais à raiz quadrada do tamanho total do alfabeto. Quando os autores inserem medidas de proteínas e RNA reais, constatam que o número médio de formas não dobradas por posição e a variedade efetiva de letras por posição alinham-se de perto com essa previsão, para ambos os tipos de biopolímeros.
Por que quatro nucleotídeos e cerca de vinte aminoácidos
Para o RNA, estudos experimentais da flexibilidade da espinha dorsal e do uso de pares de bases sugerem que cada nucleotídeo tem cerca de duas vírgula cinco conformações relevantes na cadeia não dobrada. Elevar esse valor ao quadrado dá um tamanho de alfabeto muito próximo de quatro, exatamente o que a vida usa. Para proteínas, estimativas da liberdade da espinha dorsal e da variação de sequência implicam cerca de quatro a cinco conformações eficazes e “letras” efetivas por posição, o que aponta para um alfabeto ótimo na faixa de aproximadamente vinte ou algumas dezenas de aminoácidos. O fato de a biologia moderna usar vinte aminoácidos quimicamente distintos encaixa-se confortavelmente na extremidade inferior dessa faixa, consistente com limites práticos adicionais, como a complexidade que a maquinaria de síntese proteica pode suportar e quantos tipos distintos de cadeias laterais podem ser mantidos confiavelmente distintos.
Pistas sobre as primeiras proteínas flexíveis da vida
Os autores então transformam esse arcabouço em uma janela para a evolução inicial. Eles combinam suas fórmulas com reconstruções anteriores de quando diferentes aminoácidos entraram no código genético. Nas fases mais iniciais, o alfabeto parece ter sido pequeno demais para suportar proteínas estáveis e bem dobradas. Em vez disso, a teoria prevê cadeias que permaneciam altamente flexíveis e desordenadas, mas que ainda podiam aglomerar-se em gotículas ou redes frouxas consideradas importantes para estruturas primitivas semelhantes a células sem membrana. À medida que mais aminoácidos foram adicionados, o alfabeto cruzou um limiar onde proteínas dobradas tornaram-se possíveis, favorecendo primeiro cadeias intrinsecamente desordenadas mas funcionais, e só mais tarde permitindo estruturas tridimensionais bem definidas e catalisadores eficientes.
O que isso significa para os limites da vida
Em termos cotidianos, o estudo sugere que existe um ponto ótimo entre ter poucas letras químicas, o que dificulta codificar formas específicas, e ter muitas, o que torna a busca por moléculas viáveis impossivelmente lenta. Os quatro nucleotídeos e os vinte aminoácidos da Terra estão muito próximos desse ponto ótimo, dado quão flexíveis essas cadeias são naturalmente em água. Abaixo desses tamanhos de alfabeto, a evolução teria dificuldade em encontrar moléculas bem dobradas; acima deles, letras adicionais trazem pouca vantagem porque uma única estrutura estável já pode ser codificada. Nessa visão, os alfabetos da vida não são arbitrários: são soluções perto do mínimo que permitem que moléculas ricas em informação dobrem rapidamente e evoluam com eficiência.
Citação: Galpern, E.A., Ferreiro, D.U. & Sánchez, I.E. An information-theoretic argument for the restriction of the current biological alphabets to 4 nucleotides and 20 amino acids. Sci Rep 16, 10751 (2026). https://doi.org/10.1038/s41598-026-46009-8
Palavras-chave: código genético, dobramento de proteínas, estrutura de RNA, evolução molecular, alfabetos de biopolímeros