Clear Sky Science · es
Un argumento desde la teoría de la información para la restricción de los alfabetos biológicos actuales a 4 nucleótidos y 20 aminoácidos
Por qué importan los diminutos alfabetos de la vida
Toda la vida en la Tierra escribe sus “textos” genéticos y proteicos usando alfabetos sorprendentemente pequeños: apenas cuatro letras químicas para el ADN y el ARN, y veinte para las proteínas. Los químicos pueden imaginar muchos más bloques constructivos, así que ¿por qué la biología se limita a estos conjuntos reducidos? Este artículo sostiene que la respuesta reside en la facilidad con que estas moléculas pueden plegarse en formas útiles y en la eficiencia con la que la evolución puede explorar el conjunto de secuencias posibles. Al conectar ideas de la física y la teoría de la información, los autores muestran que los alfabetos familiares de la vida son apenas lo bastante grandes para que las moléculas se plieguen de forma fiable y, al mismo tiempo, sigan siendo evolucionables.
De cuerdas enredadas a formas útiles
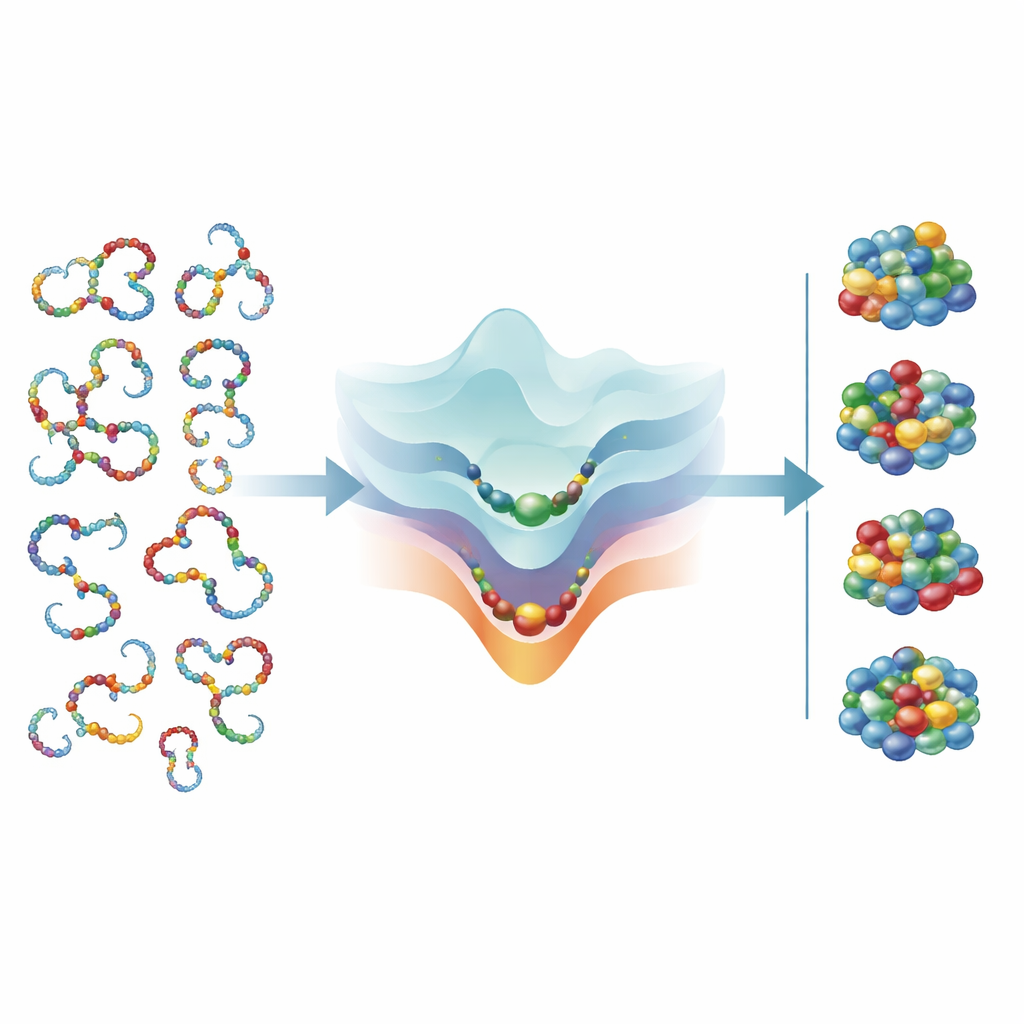
Las proteínas y el ARN empiezan como cadenas flexibles que vibran entre innumerables conformaciones posibles. Solo una fracción mínima de esas conformaciones es estable y funcional. Para que la vida funcione, una cadena debe encontrar rápidamente su forma plegada correcta sin probar cada posibilidad al azar. Los autores usan una lente de teoría de la información: cuando una cadena se pliega, “gana información” al seleccionar una estructura nativa entre muchas alternativas. Esta ganancia puede medirse como cuánto se reduce el conjunto de formas posibles por posición a lo largo de la cadena. Lo comparan con la información ganada cuando la evolución filtra secuencias aleatorias hasta aquellas que realmente se pliegan, mostrando que ambos procesos deben estar balanceados para que el plegamiento sea rápido y fiable.
Emparejar letras digitales con movimientos físicos
La idea clave es un vínculo matemático sencillo entre tres cosas: el tamaño del alfabeto químico, cuántas formas puede adoptar cada posición en una cadena desplegada y cuántos bloques constructivos distintos aparecen efectivamente en esa posición en moléculas reales y evolucionadas. Para un polímero que se pliega a una estructura bien definida, la teoría predice que el número de conformaciones desplegadas accesibles por posición y la diversidad efectiva de letras usadas allí deberían ser ambos aproximadamente iguales a la raíz cuadrada del tamaño total del alfabeto. Cuando los autores introducen mediciones de proteínas y ARN reales, encuentran que el número medio de conformaciones desplegadas por posición y la variedad efectiva de letras por posición coinciden de forma ajustada con esta predicción, en ambos tipos de biopolímeros.
Por qué cuatro nucleótidos y unos veinte aminoácidos
Para el ARN, estudios experimentales sobre la flexibilidad de la columna vertebral y el uso de pares de bases sugieren que cada nucleótido tiene alrededor de dos o tres conformaciones relevantes en estado desplegado. Elevar este valor al cuadrado da un tamaño de alfabeto muy cercano a cuatro, precisamente lo que usa la vida. Para las proteínas, estimaciones de la libertad de la columna vertebral y de la variación de secuencia implican aproximadamente cuatro o cinco conformaciones efectivas y letras efectivas por posición, lo que apunta a un alfabeto óptimo en el orden de unas veinte o unas pocas docenas de aminoácidos. El hecho de que la biología moderna utilice veinte aminoácidos químicamente distintos encaja cómodamente en el extremo inferior de ese rango, coherente con límites prácticos adicionales como la complejidad del aparato de fabricación proteica y cuántos tipos de cadenas laterales pueden mantenerse distintamente reconocibles.
Pistas sobre las primeras proteínas flexibles de la vida
Los autores convierten a continuación este marco en una ventana sobre la evolución temprana. Combinan sus fórmulas con reconstrucciones previas de cuándo distintos aminoácidos entraron en el código genético. En las etapas más tempranas, el alfabeto parece haber sido demasiado pequeño para sostener proteínas estables y bien plegadas. En su lugar, la teoría predice cadenas que permanecían muy flexibles y desordenadas, pero que aun así podían agregarse en gotas o redes sueltas pensadas como importantes para estructuras primitivas similares a células sin membrana. A medida que se añadieron más aminoácidos, el alfabeto cruzó un umbral donde las proteínas plegadas se volvieron posibles, favoreciendo primero cadenas intrínsecamente desordenadas pero funcionales y, solo más tarde, permitiendo estructuras tridimensionales bien definidas y catalizadores eficientes.
Qué significa esto para los límites de la vida
En términos cotidianos, el estudio sugiere que existe un punto óptimo entre tener muy pocas letras químicas, lo que dificulta codificar formas específicas, y tener demasiadas, lo que hace que la búsqueda de moléculas útiles sea improbablemente lenta. Los cuatro nucleótidos y los veinte aminoácidos de la Tierra se sitúan muy cerca de ese punto óptimo, dado lo flexibles que son naturalmente estas cadenas en agua. Por debajo de esos tamaños de alfabeto, la evolución tendría dificultades para encontrar moléculas bien plegadas; por encima de ellos, las letras adicionales aportan poco beneficio porque ya puede codificarse una estructura estable. En esta visión, los alfabetos de la vida no son arbitrarios: son soluciones cercanas al mínimo que permiten que moléculas ricas en información se plieguen con rapidez y evolucionen con eficacia.
Cita: Galpern, E.A., Ferreiro, D.U. & Sánchez, I.E. An information-theoretic argument for the restriction of the current biological alphabets to 4 nucleotides and 20 amino acids. Sci Rep 16, 10751 (2026). https://doi.org/10.1038/s41598-026-46009-8
Palabras clave: código genético, plegamiento de proteínas, estructura del ARN, evolución molecular, alfabetos de biopolímeros