Clear Sky Science · nl
Een information-theoretisch betoog voor de beperking van de huidige biologische alfabetten tot 4 nucleotiden en 20 aminozuren
Waarom de kleine alfabetten van het leven ertoe doen
Al het leven op aarde schrijft zijn genetische en eiwit-"teksten" met verrassend kleine alfabetten: slechts vier chemische letters voor DNA en RNA, en twintig voor eiwitten. Chemici kunnen zich veel meer bouwstenen voorstellen, dus waarom houdt de biologie zich aan deze beperkte sets? Dit artikel betoogt dat het antwoord ligt in hoe gemakkelijk deze moleculen in nuttige vormen kunnen vouwen en hoe efficiënt evolutie door alle mogelijke sequenties kan zoeken. Door ideeën uit de natuurkunde en informatietheorie te verbinden, tonen de auteurs aan dat de vertrouwde alfabetten van het leven net groot genoeg zijn om moleculen betrouwbaar te laten vouwen en tegelijk evolueerbaar te blijven.
Van verwarde ketens naar bruikbare vormen
Eiwitten en RNA beginnen als flexibele ketens die door ontelbare mogelijke vormen bewegen. Slechts een klein deel van die vormen is stabiel en functioneel. Voor functioneel leven moet een keten snel zijn correcte gevouwen vorm vinden zonder willekeurig alle mogelijkheden uit te proberen. De auteurs gebruiken een informatietheoretische invalshoek: wanneer een keten vouwt, "verwerft" hij informatie door één native vorm uit veel alternatieven te kiezen. Deze winst kan gemeten worden als in hoeverre het bereik van mogelijke vormen per positie langs de keten krimpt. Ze vergelijken dit met de informatiewinst wanneer evolutie willekeurige sequenties uitselecteert tot diegenen die daadwerkelijk vouwen, en laten zien dat beide processen in balans moeten zijn om vouwen snel en betrouwbaar te laten verlopen.
Digitale letters koppelen aan fysieke bewegingen
De kerninzichten zijn een eenvoudige wiskundige koppeling tussen drie zaken: de grootte van het chemische alfabet, hoeveel vormen elke positie in een onvervouwde keten kan aannemen, en hoeveel verschillende bouwstenen effectief op die positie voorkomen in echte, geëvolueerde moleculen. Voor een polymeer dat naar een goed gedefinieerde structuur vouwt, voorspelt de theorie dat het aantal toegankelijke onvervulde vormen per positie en de effectieve diversiteit van letters die daar gebruikt worden beide ruwweg gelijk moeten zijn aan de vierkantswortel van de totale alfabetgrootte. Wanneer de auteurs metingen van echte eiwitten en RNA invoeren, vinden ze dat het gemiddelde aantal onvervulde vormen per positie en de effectieve variëteit aan letters per positie dicht bij deze voorspelling liggen, voor beide typen biopolymeren.
Waarom vier nucleotiden en ongeveer twintig aminozuren
Voor RNA suggereren experimentele studies van ruggenmergflexibiliteit en basenpaargebruik dat elke nucleotide ongeveer tweeënhalf relevante onvervulde vormen heeft. Het kwadraat van deze waarde geeft een alfabetgrootte die zeer dicht bij vier ligt, precies wat het leven gebruikt. Voor eiwitten wijzen schattingen van ruggenmergvrijheid en sequentievariatie op ongeveer vier tot vijf effectieve vormen en effectieve letters per positie, wat wijst op een optimaal alfabet in de orde van ongeveer twintig of enkele tientallen aminozuren. Het feit dat de moderne biologie twintig chemisch verschillende aminozuren gebruikt, valt daarmee comfortabel aan de onderkant van dit bereik, in overeenstemming met aanvullende praktische beperkingen zoals hoe complex de eiwitproducerende machinerie kan zijn en hoeveel verschillende zijketentypen betrouwbaar onderscheidbaar blijven.
Winkjes over vroege, soepele eiwitten van het leven
De auteurs zetten dit raamwerk vervolgens in als een venster op vroege evolutie. Ze combineren hun formules met eerdere reconstructies van wanneer verschillende aminozuren in de genetische code opkwamen. In de vroegste stadia lijkt het alfabet te klein geweest om stabiele, netjes gevouwen eiwitten te ondersteunen. In plaats daarvan voorspelt de theorie ketens die hoogst flexibel en gedesordend bleven, maar toch konden samenklonteren tot druppels of losse netwerken die gedacht worden belangrijk te zijn voor primitieve, membraanloze celachtige structuren. Naarmate meer aminozuren werden toegevoegd, passeerde het alfabet een drempel waarbij gevouwen eiwitten mogelijk werden, eerst in de richting van intrinsiek gedesordeerde maar functionele ketens, en pas later met scherp gedefinieerde driedimensionale vormen en efficiënte katalyseurs.
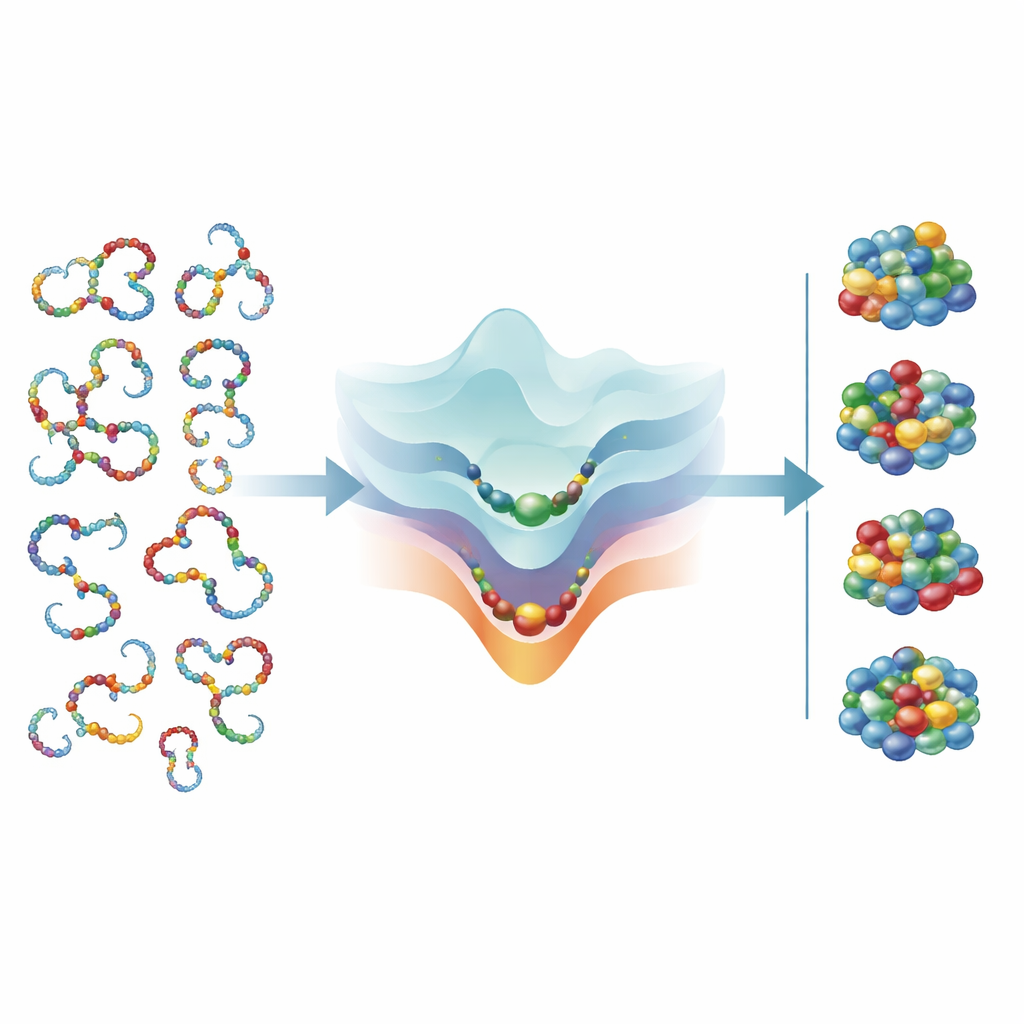
Wat dit betekent voor de grenzen van het leven
In gewone bewoordingen suggereert de studie dat er een gulden middenweg bestaat tussen te weinig chemische letters, wat het moeilijk maakt om specifieke vormen te coderen, en te veel letters, wat het zoeken naar bruikbare moleculen onwerkbaar traag maakt. De vier nucleotiden en twintig aminozuren van de aarde liggen zeer dicht bij die optimale zone, gegeven hoe soepel deze ketens van nature in water zijn. Onder die alfabetgroottes zou evolutie moeite hebben om goed gevouwen moleculen te vinden; erboven brengen extra letters weinig voordeel omdat een enkele stabiele structuur al gecodeerd kan worden. In dit licht zijn de alfabetten van het leven niet willekeurig: het zijn vrijwel-minimale oplossingen die informatierijke moleculen zowel snel laten vouwen als efficiënt laten evolueren.
Bronvermelding: Galpern, E.A., Ferreiro, D.U. & Sánchez, I.E. An information-theoretic argument for the restriction of the current biological alphabets to 4 nucleotides and 20 amino acids. Sci Rep 16, 10751 (2026). https://doi.org/10.1038/s41598-026-46009-8
Trefwoorden: genetische code, eiwitvouwing, RNA-structuur, moleculaire evolutie, biopolymeeralfabetten