Clear Sky Science · pt
Validação e avaliação de esquemas extraídos em bancos de dados JSON
Por que os projetos invisíveis de dados importam
Aplicações modernas — desde lojas online até sistemas hospitalares e redes de sensores — frequentemente armazenam informações em bancos “sem esquema” flexíveis. Esses sistemas facilitam a evolução dos dados em tempo real, mas ocultam a planta subjacente, ou esquema, que nos diz quais campos existem, como se relacionam e como mudam ao longo do tempo. Quando engenheiros tentam integrar dados, otimizar consultas ou simplesmente entender o que está armazenado, precisam primeiro reconstruir esse projeto oculto. Muitas ferramentas tentam inferir esquemas automaticamente, mas até agora não havia uma forma padrão e objetiva de avaliar quão boas são essas estimativas.
Uma régua para a estrutura de dados oculta
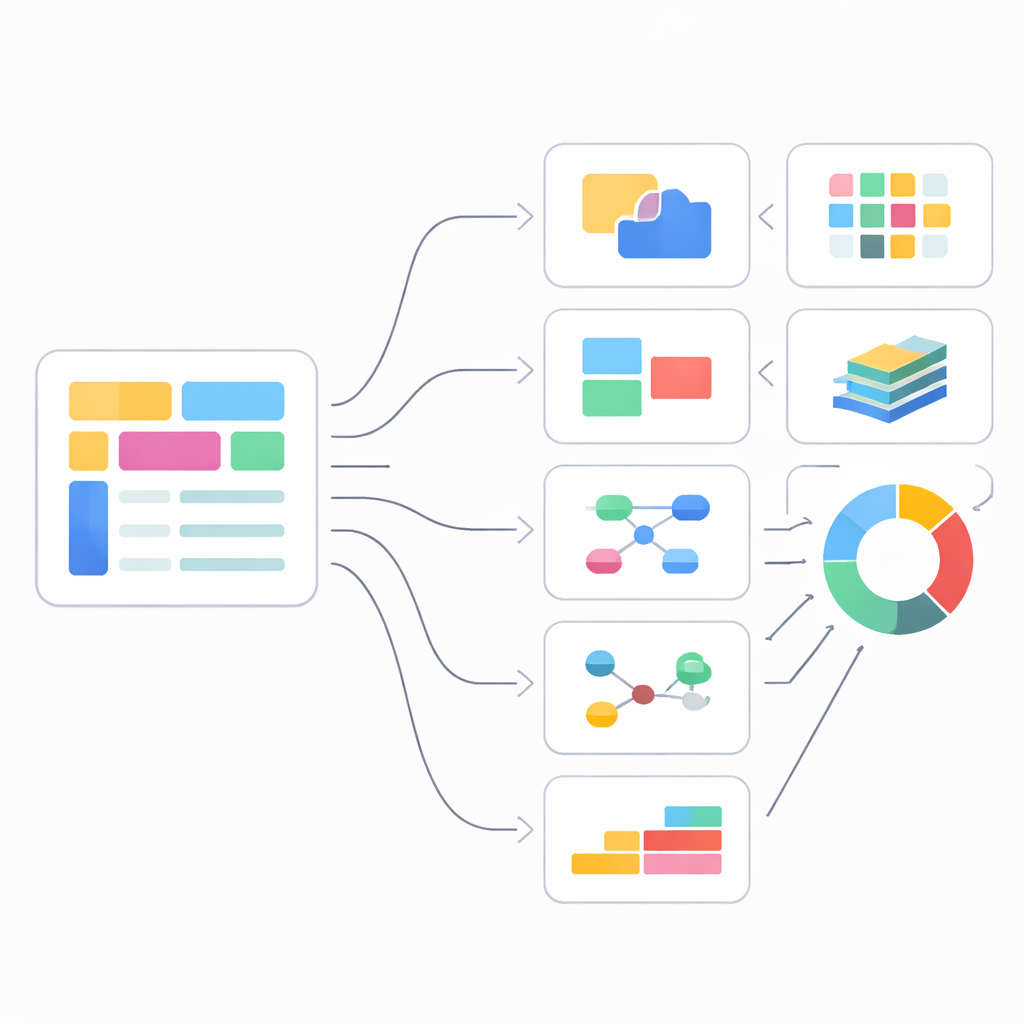
Este artigo apresenta o Framework de Validação e Avaliação de Esquemas (SVEF), um método sistemático para medir a qualidade de esquemas extraídos de bancos JSON e similares. Em vez de focar em como um esquema é produzido, o SVEF observa apenas o que a planta resultante afirma sobre os dados e o confronta com o que está realmente armazenado. O framework divide a qualidade do esquema em seis aspectos intuitivos: se os tipos de campo estão corretos; quais campos são realmente obrigatórios versus opcionais; se um campo pode aceitar com segurança vários tipos de valores; quão bem organizadas estão listas e arrays; quão bem são recuperadas as ligações entre entidades; e quão precisamente o esquema acompanha mudanças ao longo do tempo. Cada aspecto recebe métricas quantitativas, e as pontuações são combinadas em um único indicador geral de qualidade.
Seis lentes sobre a qualidade dos dados
Cada uma das seis dimensões do SVEF examina um ponto de dor comum para quem trabalha com dados sem esquema. A precisão de tipo de dado verifica se categorias básicas, como texto, números e valores verdadeiro/falso, correspondem ao que está realmente presente. Campos obrigatórios e opcionais focam em padrões de presença e coocorrência: por exemplo, que todo pedido deve ter um identificador de pedido, enquanto um código de desconto aparece apenas às vezes e pode acionar outros campos quando presente. Suporte a tipos múltiplos reconhece que o mesmo campo pode legitimamente aparecer como número em alguns registros e como um objeto estruturado em outros, e recompensa esquemas que capturam essa diversidade sem generalizar em excesso. Consistência da estrutura de coleções aprofunda-se em arrays, perguntando se listas têm uma profundidade e estrutura de elementos previsíveis em vez de serem achatadas ou tratadas como sacos não estruturados de valores.
Seguindo ligações e acompanhando o tempo
Outras duas dimensões vão além dos registros individuais. Recuperação de relacionamentos entre entidades avalia quão bem um esquema inferido captura ligações como “cliente tem muitos pedidos” ou “paciente tem muitos tratamentos”, mesmo quando esses vínculos são apenas insinuados por identificadores repetidos ou objetos aninhados. O SVEF compara a rede de entidades e conexões no esquema inferido com uma referência confiável usando medidas baseadas em grafos que equilibram correção local e estrutura global. A detecção de evolução temporal pergunta se o método consegue notar e descrever mudanças na planta dos dados ao longo do tempo: novos campos surgindo, antigos desaparecendo, ou valores simples tornando-se subobjetos mais ricos. Ao fatiar os dados em janelas temporais e comparar esquemas entre elas, o SVEF avalia tanto se os pontos de mudança corretos são detectados quanto se o método é excessivamente sensível ou lento demais.
Colocando o framework à prova
Para ver o que o SVEF revela na prática, os autores o aplicaram a três abordagens diferentes de extração de esquemas e a três conjuntos de dados cuidadosamente projetados: uma loja de comércio eletrônico, um sistema de saúde e uma rede de sensores da Internet das Coisas. Esses conjuntos de dados eram sintéticos, porém realistas, com esquemas “verdadeiros” conhecidos incluindo campos opcionais, atributos de tipo união, listas aninhadas, referências entre entidades e mudanças estruturais planejadas ao longo do tempo. Todos os três métodos se saíram bem no reconhecimento básico de tipos, mas seus pontos fortes divergiram em outras áreas. Uma abordagem com foco estrutural destacou‑se na identificação de campos obrigatórios e no acompanhamento da evolução do esquema; um método orientado a relacionamentos foi melhor em mapear ligações entre entidades; e uma técnica enriquecida semanticamente lidou de forma mais elegante com tipos mistos de campo e regularidades em arrays. Nenhum foi o melhor em todas as seis dimensões, e seus trade‑offs ficaram óbvios apenas quando vistos pela lente multifacetada do SVEF.
O que isso significa para o trabalho com dados no mundo real
Para os profissionais, o framework oferece uma régua tão necessária para julgar e comparar ferramentas que reconstroem a estrutura de dados a partir de repositórios sem esquema. Em vez de confiar em verificações ad hoc ou em inspecionar esquemas de exemplo, equipes podem agora quantificar quão bem um método captura o essencial de seus dados, incluindo dependências sutis e evolução de longo prazo. Para pesquisadores, o SVEF destaca onde as técnicas atuais têm dificuldades — particularmente com campos condicionais, arrays complexos e deriva temporal — e aponta para métodos mais equilibrados que integrem raciocínio estrutural, semântico e sensível ao tempo. Em suma, o trabalho transforma a qualidade do esquema de uma impressão vaga em uma propriedade mensurável, ajudando organizações a confiar e refinar as plantas invisíveis que alimentam seus sistemas orientados a dados.
Citação: Belefqih, S., Barchane, M., Zellou, A. et al. Schema validation and evaluation framework for extracted schemas in JSON databases. Sci Rep 16, 10873 (2026). https://doi.org/10.1038/s41598-026-45554-6
Palavras-chave: Esquema JSON, Bancos de dados NoSQL, inferência de esquema, integração de dados, evolução temporal