Clear Sky Science · de
Framework zur Schemavalidierung und -bewertung für extrahierte Schemata in JSON-Datenbanken
Warum unsichtbare Datenblaupausen wichtig sind
Moderne Anwendungen – von Onlineshops über Krankenhaus‑Systeme bis zu Sensornetzwerken – speichern Informationen häufig in flexiblen „schemalosen“ Datenbanken. Diese Systeme erleichtern die laufende Weiterentwicklung der Daten, verbergen dabei aber die zugrunde liegende Blaupause, also das Schema, das angibt, welche Felder existieren, wie sie zusammenhängen und wie sie sich über die Zeit verändern. Wenn Entwickler später Daten integrieren, Abfragen optimieren oder einfach verstehen wollen, was gespeichert ist, müssen sie diese verborgene Blaupause zuerst rekonstruieren. Viele Werkzeuge versuchen, solche Schemata automatisch zu schätzen, doch bislang gab es keinen standardisierten, objektiven Weg, diese Schätzungen zu beurteilen.
Ein Maßstab für versteckte Datenstruktur
Dieses Paper stellt das Schema Validation and Evaluation Framework (SVEF) vor, eine systematische Methode zur Messung der Qualität von aus JSON- und JSON-ähnlichen Datenbanken extrahierten Schemata. Anstatt darauf zu schauen, wie ein Schema erzeugt wird, bewertet SVEF ausschließlich, was die resultierende Blaupause über die Daten aussagt, und vergleicht dies mit dem tatsächlich gespeicherten Inhalt. Das Framework zerlegt die Schemaqualität in sechs einleuchtende Aspekte: ob Feldtypen korrekt sind; welche Felder wirklich erforderlich versus optional sind; ob ein Feld sicher mehrere verschiedene Wertarten annehmen kann; wie sauber Listen und Arrays strukturiert sind; wie gut Verknüpfungen zwischen Entitäten wiederhergestellt werden; und wie genau das Schema Veränderungen über die Zeit abbildet. Jeder Aspekt wird mit quantitativen Metriken bewertet, und die Ergebnisse werden zu einem einzigen Gesamtqualitätsindikator zusammengeführt.
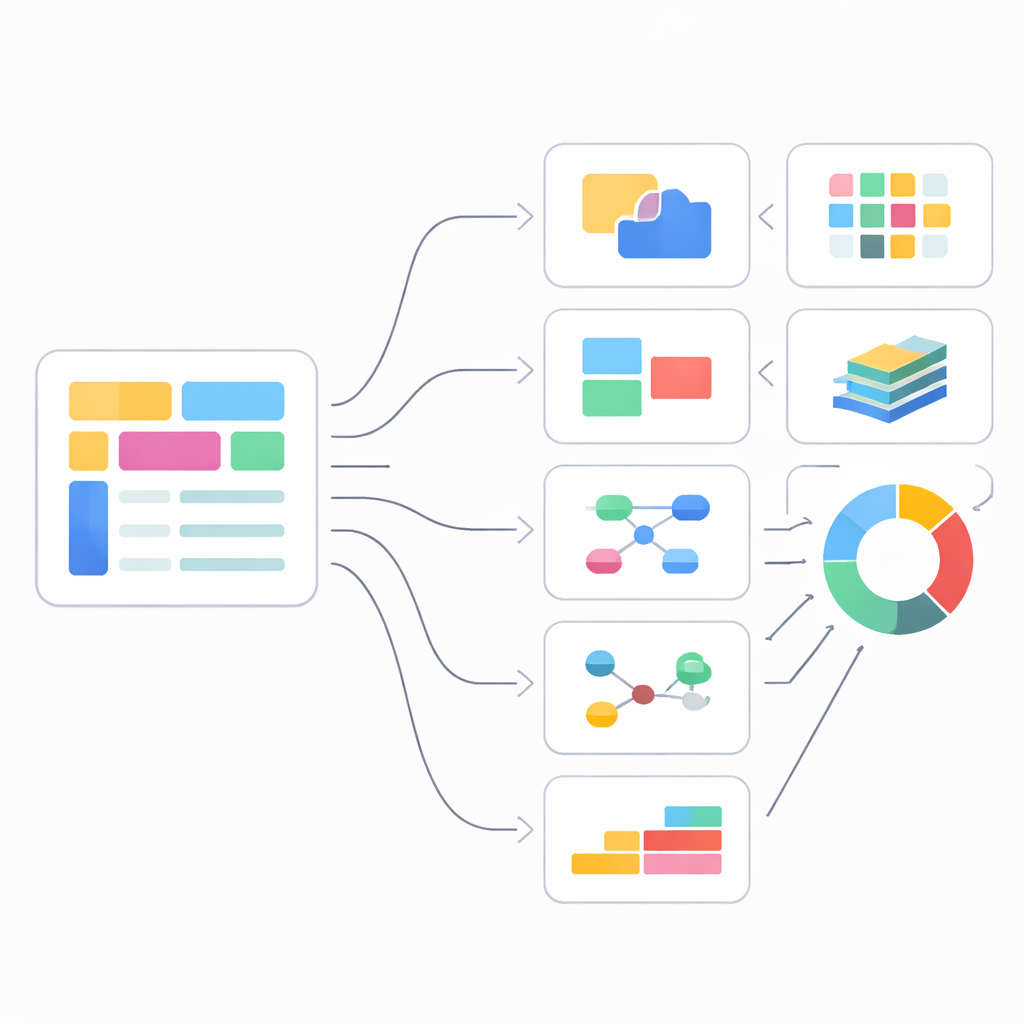
Sechs Blickwinkel auf Datenqualität
Jede der sechs Dimensionen von SVEF untersucht einen typischen Schmerzpunkt bei der Arbeit mit schemalosen Daten. Die Genauigkeit der Datentypen prüft, ob grundlegende Kategorien wie Text, Zahlen und Wahr/Falsch-Werte dem tatsächlichen Inhalt entsprechen. Erforderliche und optionale Felder konzentrieren sich auf Anwesenheitsmuster und gemeinsame Vorkommen: zum Beispiel, dass jede Bestellung eine Bestellnummer haben muss, während ein Rabattcode nur gelegentlich vorkommt und beim Vorhandensein weitere Felder auslösen kann. Die Unterstützung mehrerer Typen erkennt an, dass dasselbe Feld in einigen Datensätzen legitim als Zahl und in anderen als strukturiertes Objekt auftreten kann, und belohnt Schemata, die diese Vielfalt erfassen, ohne zu sehr zu verallgemeinern. Die Konsistenz der Sammlungsstruktur zoomt auf Arrays: sie fragt, ob Listen eine vorhersehbare Tiefe und Elementstruktur haben, anstatt abgeflacht oder als unstrukturierte Wertmengen behandelt zu werden.
Verknüpfungen folgen und der zeitlichen Entwicklung nachgehen
Zwei weitere Dimensionen blicken über einzelne Datensätze hinaus. Die Wiederherstellung von Entitätenbeziehungen bewertet, wie gut ein inferiertes Schema Verknüpfungen wie „Kunde hat viele Bestellungen“ oder „Patient hat viele Behandlungen“ erfasst, selbst wenn diese Verknüpfungen nur durch wiederkehrende Identifikatoren oder verschachtelte Objekte angedeutet werden. SVEF vergleicht das Netzwerk von Entitäten und Verbindungen im inferierten Schema mit einer verlässlichen Referenz unter Verwendung graphbasierter Maße, die lokale Korrektheit und globale Struktur ausbalancieren. Die Erkennung temporaler Entwicklung fragt, ob die Methode Änderungen in der Datenblaupause im Zeitverlauf bemerkt und beschreibt: neue Felder, das Verschwinden alter Felder oder das Aufbrechen einfacher Werte zu reicheren Unterobjekten. Durch das Aufteilen der Daten in Zeitfenster und den Vergleich von Schemata zwischen diesen Fenstern bewertet SVEF sowohl, ob die richtigen Änderungszeitpunkte erkannt werden, als auch, ob die Methode zu empfindlich oder zu träge reagiert.
Das Framework auf die Probe gestellt
Um zu zeigen, was SVEF in der Praxis offenlegt, wendeten die Autoren es auf drei verschiedene Schemaextraktionsverfahren und drei sorgfältig gestaltete Datensätze an: einen E‑Commerce‑Shop, ein Gesundheitssystem und ein Internet‑of‑Things‑Sensornetzwerk. Diese Datensätze waren synthetisch, aber realistisch, mit bekanntem Ground‑Truth‑Schema, das optionale Felder, Union‑Typen, verschachtelte Listen, Referenzen zwischen Entitäten und geplante strukturelle Änderungen über die Zeit enthielt. Alle drei Methoden erzielten gute Ergebnisse bei der grundlegenden Typenerkennung, divergierten jedoch in anderen Bereichen. Ein strukturell fokussierter Ansatz war hervorragend darin, erforderliche Felder zu identifizieren und Schemaentwicklungen nachzuverfolgen; eine beziehungsorientierte Methode war am besten darin, Verknüpfungen zwischen Entitäten abzubilden; und eine semantisch angereicherte Technik ging gemischte Feldtypen und Array‑Regelmäßigkeiten eleganter an. Keine Methode war in allen sechs Dimensionen führend, und ihre Kompromisse wurden erst durch SVEF’s mehrperspektivischen Blick deutlich.
Was das für die Arbeit mit realen Daten bedeutet
Für Praktiker bietet das Framework einen dringend benötigten Maßstab, um Werkzeuge zu bewerten und zu vergleichen, die Datenstrukturen aus schemalosen Speichern rückentwickeln. Anstatt sich auf Ad‑hoc‑Prüfungen oder das Ansehen einzelner Beispielschema zu verlassen, können Teams nun quantifizieren, wie gut eine Methode die Wesentlichkeiten ihrer Daten erfasst, einschließlich subtiler Abhängigkeiten und langfristiger Entwicklungen. Für Forschende weist SVEF darauf hin, wo aktuelle Techniken Schwierigkeiten haben – insbesondere bei konditionalen Feldern, komplexen Arrays und zeitlicher Drift – und zeigt den Weg zu ausgewogeneren Methoden, die strukturelles, semantisches und zeitbewusstes Denken integrieren. Kurz gesagt macht die Arbeit Schemaqualität von einem vagen Eindruck zu einer messbaren Eigenschaft und hilft Organisationen, den unsichtbaren Blaupausen zu vertrauen und sie zu verfeinern, die ihre datengetriebenen Systeme antreiben.
Zitation: Belefqih, S., Barchane, M., Zellou, A. et al. Schema validation and evaluation framework for extracted schemas in JSON databases. Sci Rep 16, 10873 (2026). https://doi.org/10.1038/s41598-026-45554-6
Schlüsselwörter: JSON-Schema, NoSQL-Datenbanken, Schemaerkennung, Datenintegration, temporale Entwicklung