Clear Sky Science · fr
Cadre de validation et d’évaluation des schémas extraits dans les bases de données JSON
Pourquoi les plans de données invisibles comptent
Les applications modernes — des boutiques en ligne aux systèmes hospitaliers en passant par les réseaux de capteurs — stockent souvent des informations dans des bases « sans schéma » flexibles. Ces systèmes facilitent l’évolution des données à la volée, mais dissimulent le plan sous‑jacent, ou schéma, qui indique quels champs existent, comment ils se relient et comment ils évoluent dans le temps. Quand des ingénieurs cherchent ensuite à intégrer des données, optimiser des requêtes ou simplement comprendre ce qui est stocké, ils doivent d’abord reconstruire ce plan caché. De nombreux outils tentent d’inférer automatiquement ces schémas, mais jusqu’à présent il n’existait pas de méthode standard et objective pour juger de la qualité réelle de ces estimations.
Une règle pour la structure de données cachée
Cet article présente le Cadre de Validation et d’Évaluation des Schémas (SVEF), une méthode systématique pour mesurer la qualité des schémas extraits de bases JSON et JSON‑like. Plutôt que de se concentrer sur la façon dont un schéma est produit, SVEF examine uniquement ce que le plan résultant affirme au sujet des données et le vérifie par rapport à ce qui est réellement stocké. Le cadre décompose la qualité du schéma en six aspects intuitifs : si les types de champs sont corrects ; quels champs sont réellement obligatoires ou optionnels ; si un champ peut légitimement accepter plusieurs types de valeurs ; à quel point les listes et tableaux sont organisés de manière cohérente ; dans quelle mesure les liens entre entités sont retrouvés ; et à quel point le schéma suit fidèlement les changements au fil du temps. Chaque aspect est noté par des métriques quantitatives, et les scores sont agrégés en un indicateur global de qualité.
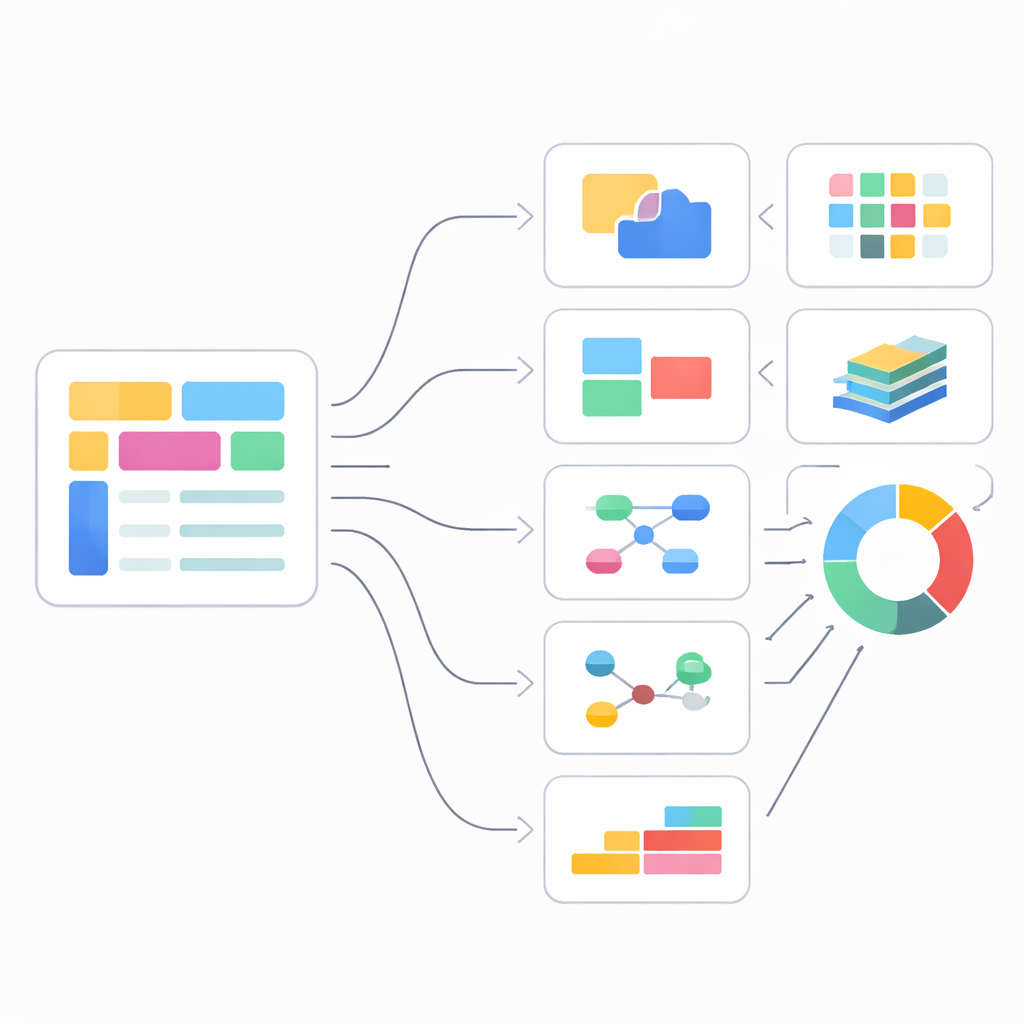
Six regards sur la qualité des données
Chacune des six dimensions de SVEF examine un point sensible courant pour les personnes qui manipulent des données sans schéma. L’exactitude des types vérifie si des catégories de base telles que texte, nombres et booléens correspondent à ce qui est réellement présent. Les champs obligatoires et optionnels se concentrent sur les motifs de présence et de co‑occurrence : par exemple, que chaque commande doit avoir un identifiant de commande, tandis qu’un code de réduction n’apparaît que parfois et peut déclencher d’autres champs lorsqu’il est présent. Le support de types multiples reconnaît qu’un même champ peut légitimement apparaître comme un nombre dans certains enregistrements et comme un objet structuré dans d’autres, et récompense les schémas qui capturent cette diversité sans trop généraliser. La cohérence de la structure des collections se penche sur les tableaux, en s’interrogeant sur le fait que les listes aient une profondeur et une structure d’éléments prévisibles plutôt que d’être aplaties ou traitées comme des sacs de valeurs non structurés.
Suivre les liens et suivre le temps
Deux dimensions supplémentaires vont au‑delà des enregistrements individuels. La récupération des relations entre entités évalue dans quelle mesure un schéma inféré capture des liens tels que « client a plusieurs commandes » ou « patient a plusieurs traitements », même lorsque ces liens ne sont suggérés que par des identifiants répétés ou des objets imbriqués. SVEF compare le réseau d’entités et de connexions du schéma inféré avec une référence de confiance en utilisant des mesures basées sur les graphes qui équilibrent correction locale et structure globale. La détection de l’évolution temporelle examine si la méthode peut repérer et décrire les changements du plan de données au fil du temps : apparition de nouveaux champs, disparition d’anciens, ou transformation de valeurs simples en sous‑objets plus riches. En découpant les données en fenêtres temporelles et en comparant les schémas entre elles, SVEF juge à la fois si les bons points de changement sont détectés et si la méthode est trop sensible ou trop lente.
Tester le cadre en pratique
Pour voir ce que SVEF révèle en pratique, les auteurs l’ont appliqué à trois approches différentes d’extraction de schéma et à trois jeux de données soigneusement conçus : une boutique en ligne, un système de santé et un réseau de capteurs Internet des objets. Ces jeux de données étaient synthétiques mais réalistes, avec des schémas de « vérité terrain » connus incluant des champs optionnels, des attributs de type union, des listes imbriquées, des références entre entités et des changements structurels planifiés dans le temps. Les trois méthodes se sont bien comportées pour la reconnaissance basique des types, mais leurs points forts divergeaient ailleurs. Une approche focalisée sur la structure excellait pour identifier les champs obligatoires et suivre l’évolution du schéma, une méthode orientée relations était la meilleure pour cartographier les liens entre entités, et une technique enrichie sémantiquement gérait plus élégamment les types mixtes de champs et les régularités des tableaux. Aucune n’était la meilleure sur les six dimensions, et leurs compromis n’apparaissaient clairement que lorsqu’on les examinait à travers la lentille multi‑angle de SVEF.
Ce que cela change pour le travail sur les données en pratique
Pour les praticiens, le cadre offre une règle de mesure bien nécessaire pour juger et comparer les outils qui rétro‑ingénient la structure des données à partir de magasins sans schéma. Plutôt que de s’appuyer sur des vérifications ad hoc ou d’évaluer à l’œil des schémas d’exemple, les équipes peuvent désormais quantifier la capacité d’une méthode à capturer l’essentiel de leurs données, y compris des dépendances subtiles et l’évolution à long terme. Pour les chercheurs, SVEF met en lumière les points où les techniques actuelles peinent — en particulier avec les champs conditionnels, les tableaux complexes et la dérive temporelle — et oriente vers des méthodes plus équilibrées qui intègrent raisonnement structurel, sémantique et temporel. En bref, ce travail transforme la qualité du schéma d’une impression vague en une propriété mesurable, aidant les organisations à faire confiance et à affiner les plans invisibles qui alimentent leurs systèmes pilotés par les données.
Citation: Belefqih, S., Barchane, M., Zellou, A. et al. Schema validation and evaluation framework for extracted schemas in JSON databases. Sci Rep 16, 10873 (2026). https://doi.org/10.1038/s41598-026-45554-6
Mots-clés: schéma JSON, bases de données NoSQL, inférence de schéma, intégration de données, évolution temporelle