Clear Sky Science · en
Schema validation and evaluation framework for extracted schemas in JSON databases
Why invisible data blueprints matter
Modern apps—from online shops to hospital systems and sensor networks—often store information in flexible “schemaless” databases. These systems make it easy to evolve data on the fly, but they hide the underlying blueprint, or schema, that tells us what fields exist, how they relate, and how they change over time. When engineers later try to integrate data, optimise queries, or simply understand what is stored, they first need to reconstruct this hidden blueprint. Many tools attempt to guess such schemas automatically, but until now there has been no standard, objective way to judge how good those guesses really are.
A yardstick for hidden data structure
This paper introduces the Schema Validation and Evaluation Framework (SVEF), a systematic way to measure the quality of schemas extracted from JSON and JSON-like databases. Instead of focusing on how a schema is produced, SVEF looks only at what the resulting blueprint says about the data and checks it against what is actually stored. The framework breaks schema quality into six intuitive aspects: whether field types are correct; which fields are truly required versus optional; whether a field can safely take several different kinds of values; how cleanly lists and arrays are organised; how well links between entities are recovered; and how accurately the schema tracks changes over time. Each aspect is scored with quantitative metrics, and the scores are combined into a single overall quality indicator.
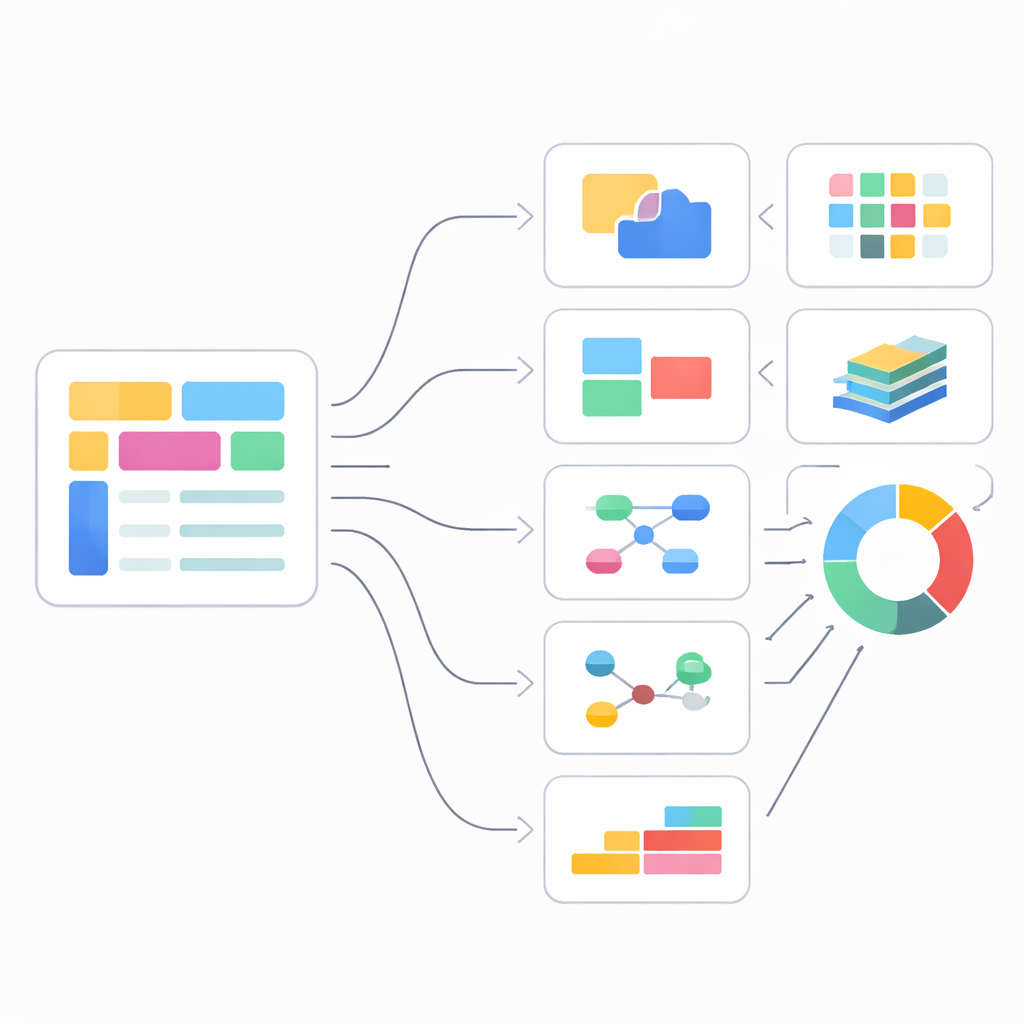
Six lenses on data quality
Each of SVEF’s six dimensions examines a common pain point for people working with schemaless data. Data type accuracy checks if basic categories such as text, numbers, and true/false values match what is truly present. Required and optional fields focus on patterns of presence and co‑occurrence: for example, that every order must have an order identifier, while a discount code appears only sometimes and may trigger other fields when present. Multiple type support recognises that the same field may legitimately appear as a number in some records and a structured object in others, and rewards schemas that capture this diversity without overgeneralising. Collection structure consistency zooms in on arrays, asking whether lists have a predictable depth and element structure instead of being flattened or treated as unstructured bags of values.
Following links and following time
Two further dimensions look beyond individual records. Entity relationship recovery evaluates how well an inferred schema captures links such as “customer has many orders” or “patient has many treatments,” even when these links are only hinted at by repeated identifiers or nested objects. SVEF compares the network of entities and connections in the inferred schema with a trusted reference using graph‑based measures that balance local correctness and global structure. Temporal evolution detection asks whether the method can notice and describe changes in the data blueprint over time: new fields appearing, old ones disappearing, or simple values turning into richer sub‑objects. By slicing data into time windows and comparing schemas across them, SVEF judges both whether the right change points are detected and whether the method is overly sensitive or too sluggish.
Putting the framework to the test
To see what SVEF reveals in practice, the authors applied it to three different schema‑extraction approaches and three carefully designed datasets: an e‑commerce store, a healthcare system, and an Internet‑of‑Things sensor network. These datasets were synthetic but realistic, with known “ground‑truth” schemas including optional fields, union‑type attributes, nested lists, references between entities, and planned structural changes over time. All three methods did well at basic type recognition, but their strengths diverged elsewhere. A structurally focused approach excelled at identifying required fields and tracking schema evolution, a relationship‑oriented method was best at mapping links between entities, and a semantically enriched technique handled mixed field types and array regularities more gracefully. None was strongest on all six dimensions, and their trade‑offs became obvious only when viewed through SVEF’s multi‑angle lens.
What this means for real‑world data work
For practitioners, the framework offers a much‑needed yardstick for judging and comparing tools that reverse‑engineer data structure from schemaless stores. Instead of relying on ad hoc checks or eyeballing example schemas, teams can now quantify how well a method captures the essentials of their data, including subtle dependencies and long‑term evolution. For researchers, SVEF highlights where current techniques struggle—particularly with conditional fields, complex arrays, and temporal drift—and points toward more balanced methods that integrate structural, semantic, and time‑aware reasoning. In short, the work turns schema quality from a vague impression into a measurable property, helping organisations trust and refine the invisible blueprints that power their data‑driven systems.
Citation: Belefqih, S., Barchane, M., Zellou, A. et al. Schema validation and evaluation framework for extracted schemas in JSON databases. Sci Rep 16, 10873 (2026). https://doi.org/10.1038/s41598-026-45554-6
Keywords: JSON schema, NoSQL databases, schema inference, data integration, temporal evolution