Clear Sky Science · pt
Um quadro de seleção de fatores condicionantes considerando heterogeneidade amostral no mapeamento da suscetibilidade a fluxos de detritos
Por que isso importa para quem vive próximo às montanhas
Em vales montanhosos íngremes, uma súbita enxurrada de lama, rochas e água pode descer sem aviso, varrendo casas, estradas e vidas. Esses desastres, conhecidos como fluxos de detritos, tendem a se tornar mais frequentes e danosos à medida que a ocupação avança em áreas de risco e os eventos de chuva extrema se intensificam. O estudo resumido aqui faz uma pergunta aparentemente simples, mas com grandes implicações para a segurança: como podemos fazer mapas que mostrem com mais precisão quais vales têm mais probabilidade de ser atingidos em seguida, especialmente quando encostas próximas não se comportam da mesma maneira?
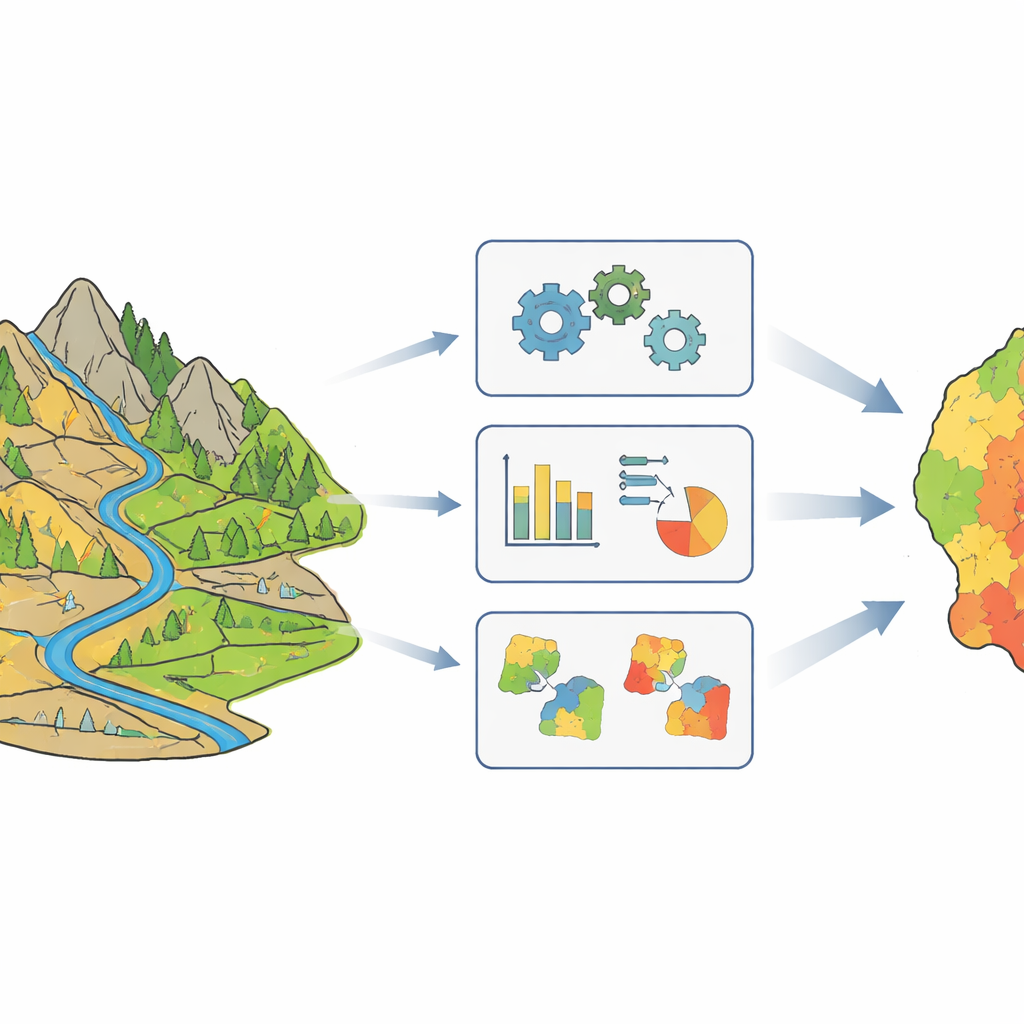
Percebendo que um mapa único não funciona para tudo
O mapeamento de suscetibilidade a fluxos de detritos é a prática de sombreamento da paisagem segundo a probabilidade de ocorrências em diferentes locais. Tradicionalmente, os cientistas tratam uma região inteira como se seguisse um único padrão uniforme: supõe-se que o mesmo conjunto de ingredientes — como declividade, precipitação, tipo de rocha, vegetação e distância a estradas ou falhas — importe da mesma forma em todo lugar. Os autores argumentam que isso é irrealista para um condado grande e acidentado como Beichuan, no sudoeste da China, onde os danos sísmicos, os tipos de rocha e as formas dos vales variam drasticamente de um lugar para outro. Em cenários assim, apoiar-se em uma “receita” global pode ocultar diferenças locais importantes e enfraquecer previsões justamente onde elas são mais necessárias.
Dividindo a paisagem em partes mais semelhantes
Para capturar essas diferenças, a equipe primeiro dividiu Beichuan em grupos de bacias de fluxo de detritos que compartilham condições ambientais semelhantes. Eles usaram uma técnica chamada clusterização fuzzy C-means, que não força cada vale a pertencer a uma única categoria rígida, mas permite filiação parcial a vários grupos. Essa flexibilidade reflete melhor a realidade do que fronteiras duras: dois vales vizinhos podem ser em grande parte semelhantes e ainda assim diferir em alguns aspectos chave. Após testar várias opções, os pesquisadores concluíram que dividir a área em quatro clusters forneceu o melhor equilíbrio entre capturar a diversidade e manter exemplos suficientes em cada grupo para treinar modelos confiáveis.
Descobrindo quais ingredientes locais importam mais
Dentro de cada um dos quatro grupos, os autores então investigaram quais fatores ambientais eram realmente mais úteis para prever onde os fluxos de detritos ocorrem. Eles confiaram em uma pontuação baseada em informação que mede quanto saber um determinado fator — como declividade, precipitação ou vegetação — reduz a incerteza sobre a ocorrência de fluxos de detritos. Isso revelou que diferentes clusters são controlados por diferentes fatores dominantes. Em um grupo, encostas íngremes foram o ingrediente principal; em outro, a orientação da encosta foi a mais importante; em um terceiro, a umidade e a concentração de água foram chave; e no último, chuvas intensas se destacaram como o gatilho primário. Ao eliminar os dois fatores mais fracos em cada grupo, a equipe simplificou seus modelos ao mesmo tempo em que manteve os sinais mais informativos.
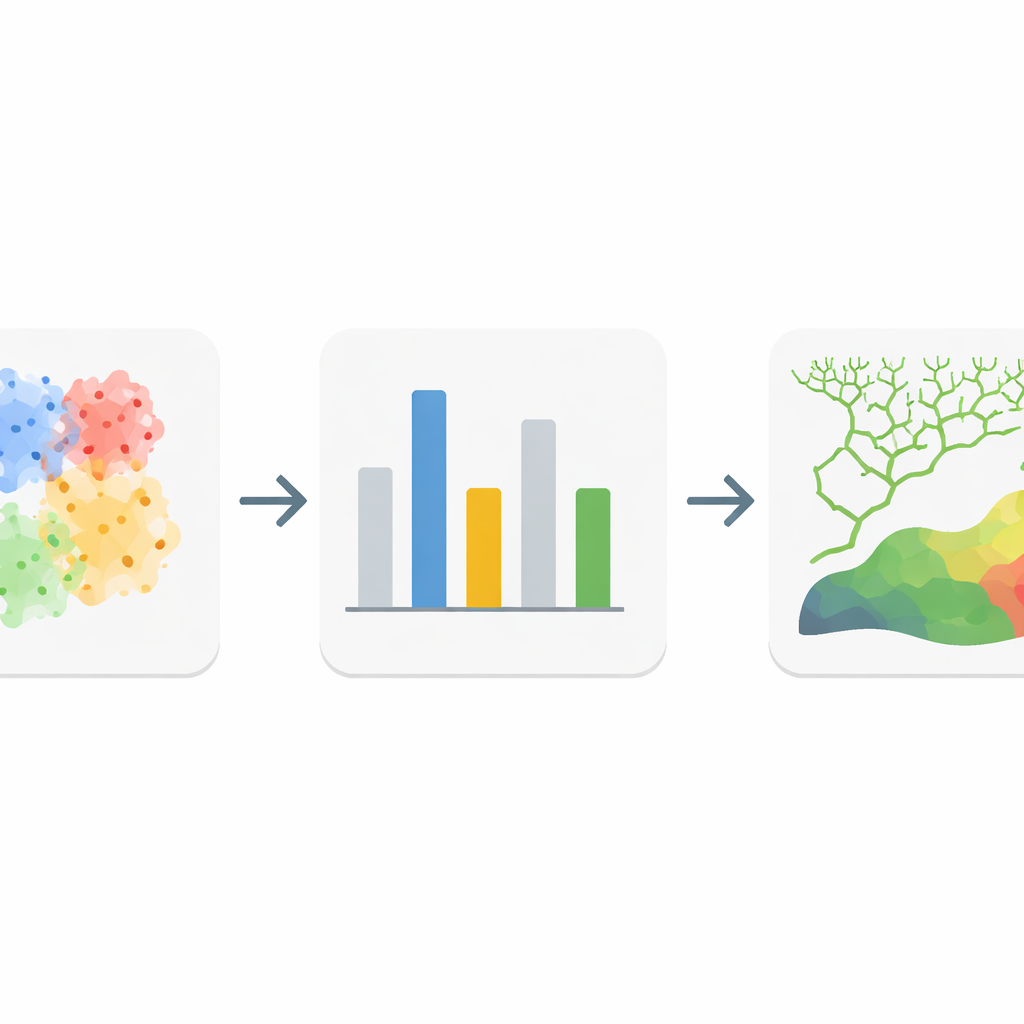
Construindo modelos de previsão mais inteligentes para cada área
Munidos desses conjuntos de fatores adaptados, os pesquisadores treinaram um método popular de aprendizado de máquina, florestas aleatórias (random forests), separadamente para todo o condado e para cada uma das quatro sub-regiões clusterizadas. Eles compararam versões que usavam todos os fatores com versões que usavam apenas os fatores selecionados localmente. O desempenho foi avaliado com várias medidas padrão de qualidade de classificação, incluindo o quão bem os modelos distinguiam entre bacias com e sem fluxos de detritos conhecidos. Modelos treinados nos clusters localmente homogêneos apresentaram desempenho consistentemente superior ao modelo global único, e a remoção de fatores fracos aumentou ainda mais a acurácia. Os mapas resultantes dos modelos personalizados e simplificados mostraram zonas de alto risco mais coerentes alinhadas a traços de falhas e vales profundos, e áreas de "risco muito baixo" com maior confiança onde as condições de gatilho estão claramente ausentes.
O que os resultados significam para um planejamento mais seguro
Para um público não especialista, a conclusão principal é que tratar uma região montanhosa inteira como se se comportasse de maneira uniforme pode ocultar padrões importantes que têm impacto na segurança. Este estudo demonstra que primeiro agrupar vales semelhantes e depois escolher os fatores mais relevantes para cada grupo leva a mapas de risco mais limpos e realistas. Esses mapas refinados de suscetibilidade a fluxos de detritos colocam mais eventos conhecidos em áreas rotuladas como risco moderado ou alto e delimitam zonas mais amplas de baixo risco genuíno. Isso os torna mais úteis para orientar onde construir, quais estradas ou vilarejos precisam de proteção extra e como priorizar investimentos em alerta precoce e planejamento de emergência em regiões suscetíveis a deslizamentos.
Citação: Gao, R., Wang, A. & Wu, D. A conditioning factor selection framework considering sample heterogeneity in debris flow susceptibility mapping. Sci Rep 16, 11933 (2026). https://doi.org/10.1038/s41598-026-42978-y
Palavras-chave: suscetibilidade a fluxos de detritos, mapeamento de risco de deslizamentos, aprendizado de máquina em georiscos, heterogeneidade espacial, gestão de risco em áreas montanhosas