Clear Sky Science · it
Un quadro di selezione dei fattori condizionanti che considera l’eterogeneità dei campioni nella mappatura della suscettibilità ai colate detritiche
Perché questo è importante per chi vive vicino alle montagne
Nei ripidi fondovalle montani, una corsa improvvisa di fango, massi e acqua può precipitare giù senza preavviso, spazzando via case, strade e vite. Questi fenomeni, noti come colate detritiche, potrebbero diventare più frequenti e dannosi man mano che l’urbanizzazione si espande in aree a rischio e gli eventi di pioggia estrema si intensificano. Lo studio qui riassunto pone una domanda apparentemente semplice ma con grandi implicazioni per la sicurezza: come possiamo realizzare mappe che indichino con maggiore precisione quali vallate saranno più probabilmente colpite, soprattutto quando i pendii vicini non si comportano tutti allo stesso modo?
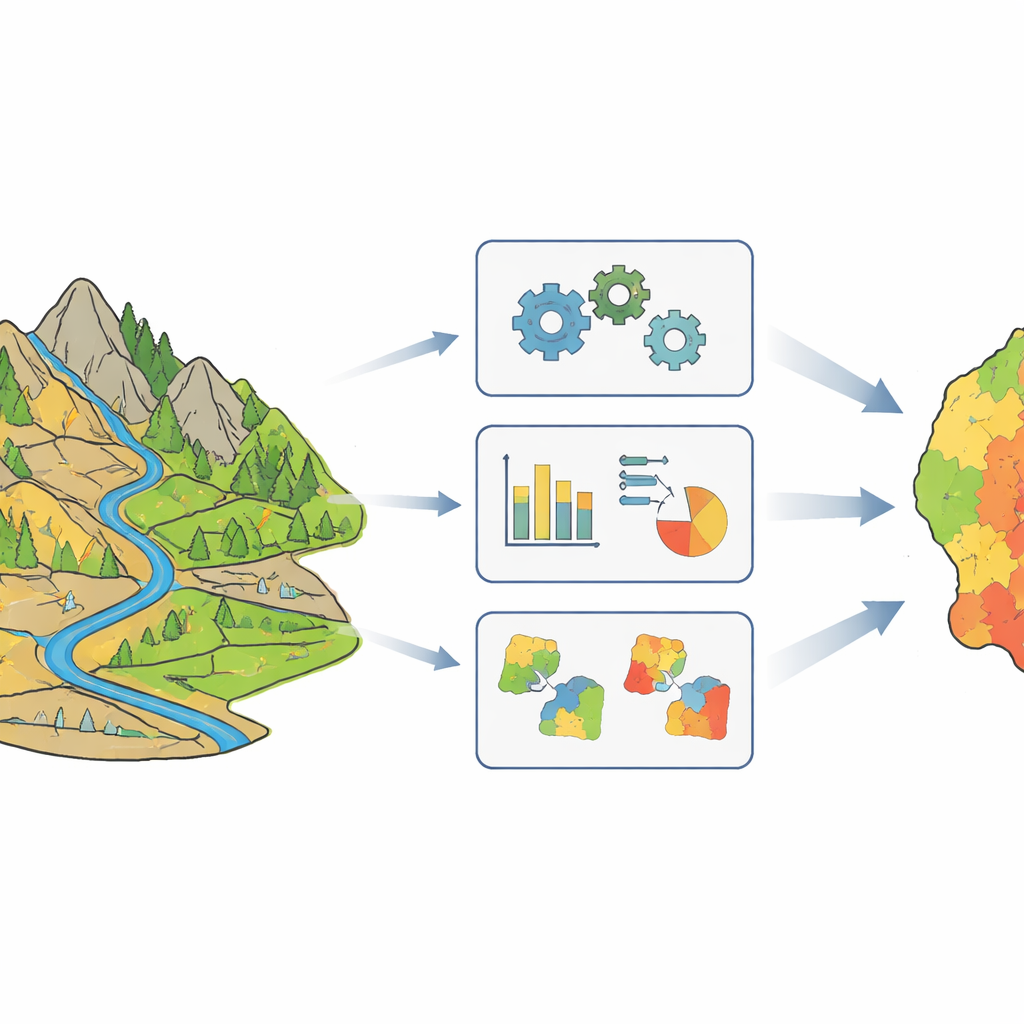
Capire che una mappa unica non va bene per tutto
La mappatura della suscettibilità alle colate detritiche consiste nel colorare il paesaggio secondo la probabilità che in diversi punti si verifichi una colata. Tradizionalmente, gli scienziati hanno trattato un’intera regione come se seguisse un unico schema uniforme: si assume che lo stesso insieme di ingredienti — come pendenza, precipitazioni, tipo di roccia, vegetazione e distanza da strade o faglie — abbia la stessa importanza ovunque. Gli autori sostengono che questo sia poco realistico per una contea vasta e accidentata come Beichuan, nel sudovest della Cina, dove i danni sismici, i tipi di roccia e le forme delle valli variano notevolmente da luogo a luogo. In questi contesti, affidarsi a una «ricetta» globale può offuscare importanti differenze locali e indebolire le previsioni proprio dove servono di più.
Suddividere il paesaggio in parti più omogenee
Per cogliere queste differenze, il gruppo ha prima diviso Beichuan in raggruppamenti di bacini di colata detritica che condividono condizioni ambientali simili. Hanno utilizzato una tecnica chiamata fuzzy C-means clustering, che non costringe ogni valle in una singola categoria rigida ma permette invece appartenenze parziali a più gruppi. Questa flessibilità rispecchia meglio la realtà rispetto a confini netti: due valli vicine possono essere per lo più simili ma differire ancora in alcuni aspetti chiave. Dopo aver testato diverse opzioni, i ricercatori hanno rilevato che suddividere l’area in quattro cluster forniva il miglior equilibrio tra catturare la diversità e mantenere un numero sufficiente di esempi in ogni gruppo per addestrare modelli affidabili.
Trovare quali «ingredienti» locali contano di più
All’interno di ciascuno dei quattro gruppi, gli autori hanno poi chiesto quali fattori ambientali fossero effettivamente più utili per prevedere dove si verificano le colate detritiche. Hanno fatto affidamento su un punteggio basato sull’informazione che misura quanto la conoscenza di un dato fattore — come pendenza, precipitazioni o vegetazione — riduce l’incertezza sulla comparsa di colate. Questo ha rivelato che cluster diversi sono controllati da driver principali differenti. In un gruppo le pendenze ripide erano l’elemento dominante; in un altro contava soprattutto l’esposizione della pendenza; in un terzo la chiave era l’umidità e la concentrazione d’acqua; e nell’ultimo le precipitazioni intense si distinguevano come il fattore scatenante principale. Eliminando i due fattori meno incisivi in ciascun gruppo, il team ha semplificato i modelli mantenendo i segnali più informativi.
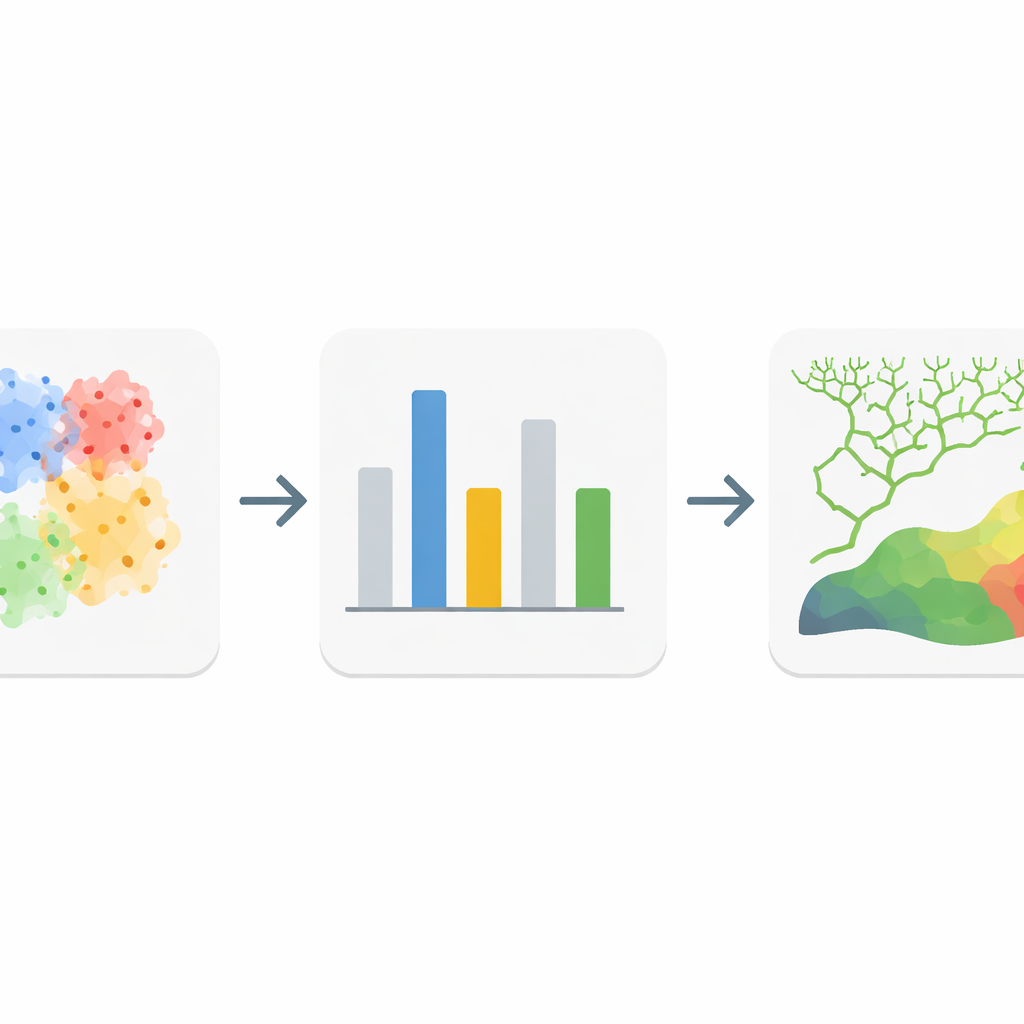
Costruire modelli di previsione più intelligenti per ogni area
Con questi insiemi di fattori personalizzati, i ricercatori hanno addestrato un noto metodo di apprendimento automatico, le foreste casuali (random forests), separatamente per l’intera contea e per ciascuna delle quattro sotto-regioni clusterizzate. Hanno confrontato versioni che usavano tutti i fattori con versioni che impiegavano solo quelli selezionati localmente. Le prestazioni sono state valutate con diverse misure standard di qualità della classificazione, incluso quanto bene i modelli distinguevano i bacini con e senza eventi di colata noti. I modelli addestrati sui cluster locali omogenei hanno costantemente sovraperformato il modello globale unico, e la rimozione dei fattori deboli ha migliorato ulteriormente l’accuratezza. Le mappe risultanti dai modelli personalizzati e snelliti hanno mostrato zone ad alto rischio più coerenti lungo le tracce di faglia e le valli profonde, e aree «molto basso» rischio più sicure dove le condizioni di innesco sono chiaramente assenti.
Cosa significano i risultati per una pianificazione più sicura
Per un pubblico non specialista, la conclusione chiave è che trattare un’intera regione montana come se si comportasse in modo uniforme può nascondere pattern importanti per la sicurezza. Questo studio dimostra che raggruppare prima le valli simili e poi scegliere i fattori più rilevanti per ciascun gruppo porta a mappe del rischio più pulite e realistiche. Queste mappe di suscettibilità alle colate detritiche affinata collocano più eventi noti in aree etichettate come rischiose (moderate o alte) e delimitano zone più ampie di reale basso rischio. Ciò le rende più utili per orientare dove costruire, quali strade o villaggi necessitano di protezioni aggiuntive e come prioritizzare gli investimenti in sistemi di allerta precoce e nella pianificazione delle emergenze nelle regioni soggette a frane.
Citazione: Gao, R., Wang, A. & Wu, D. A conditioning factor selection framework considering sample heterogeneity in debris flow susceptibility mapping. Sci Rep 16, 11933 (2026). https://doi.org/10.1038/s41598-026-42978-y
Parole chiave: suscettibilità alle colate detritiche, mappatura del rischio frane, machine learning nei georischi, eterogeneità spaziale, gestione del rischio montano