Clear Sky Science · pl
Ramowy wybór czynników warunkujących uwzględniający heterogeniczność próbek w mapowaniu podatności na lawiny błotne
Dlaczego to ma znaczenie dla osób mieszkających przy górach
W stromych dolinach górskich nagły napływ błota, kamieni i wody może przetoczyć się bez ostrzeżenia, niszcząc domy, drogi i życie. Te zjawiska, zwane lawinami błotnymi, mogą się pojawiać częściej i powodować większe szkody w miarę rozrastania się zabudowy na obszarach ryzykownych i nasilania się ekstremalnych opadów. Badanie streszczone tutaj stawia pozornie proste, lecz istotne pytanie: jak tworzyć mapy, które dokładniej pokażą, które doliny mają największe prawdopodobieństwo wystąpienia kolejnej lawiny błotnej, szczególnie gdy sąsiednie zbocza nie zachowują się w ten sam sposób?
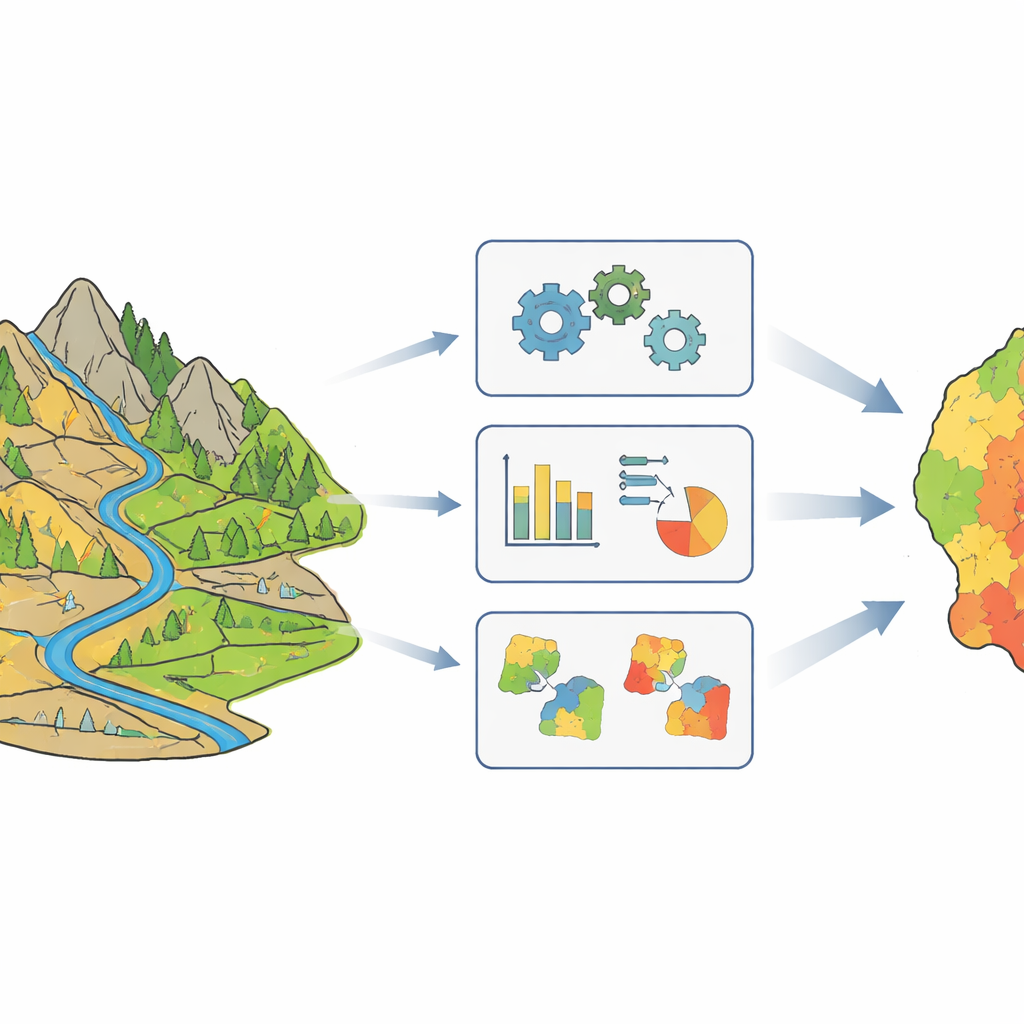
Widząc, że jedna mapa nie pasuje wszędzie
Mapowanie podatności na lawiny błotne polega na cieniowaniu terenu zgodnie z prawdopodobieństwem wystąpienia takiego zjawiska w poszczególnych miejscach. Tradycyjnie badacze traktowali cały region tak, jakby obowiązywał w nim jeden, jednorodny schemat: przyjmuje się, że ten sam zestaw składników — np. nachylenie, opady, rodzaj skał, roślinność czy odległość od dróg i uskoków — ma taką samą wagę wszędzie. Autorzy argumentują, że to nierealistyczne w dużym, zróżnicowanym terenie, takim jak powiat Beichuan na południowo-zachodnich Chinach, gdzie uszkodzenia po trzęsieniu ziemi, typy skał i kształty dolin bardzo się różnią. W takich warunkach poleganie na jednym „globalnym” przepisie może zacierać ważne lokalne różnice i osłabiać prognozy tam, gdzie są one najbardziej potrzebne.
Podział krajobrazu na bardziej jednorodne fragmenty
Aby uchwycić te różnice, zespół najpierw podzielił Beichuan na grupy zlewni lawin błotnych o podobnych warunkach środowiskowych. Wykorzystano technikę zwaną rozmytym grupowaniem C-średnich (fuzzy C-means), która nie przypisuje każdej dolinie sztywnej, pojedynczej kategorii, lecz pozwala na częściowe przynależności do kilku grup. Ta elastyczność lepiej odzwierciedla rzeczywistość niż ostre granice: dwie sąsiadujące doliny mogą być w dużej mierze podobne, ale różnić się w kilku kluczowych aspektach. Po przetestowaniu kilku wariantów badacze stwierdzili, że podział na cztery klastry daje najlepszy kompromis między uchwyceniem różnorodności a zachowaniem wystarczającej liczby przykładów w każdej grupie do wytrenowania wiarygodnych modeli.
Wyszukiwanie lokalnie najważniejszych składników
W każdej z czterech grup autorzy następnie badali, które czynniki środowiskowe naprawdę najlepiej predykowały występowanie lawin błotnych. Oparli się na miarze opartej na informacji, która mierzy, o ile znajomość danego czynnika — np. nachylenia, opadów czy roślinności — zmniejsza niepewność co do wystąpienia lawiny. Okazało się, że różne klastry kontrolowane są przez różne główne czynniki. W jednej grupie dominowały strome zbocza; w innej kluczowe było wystawienie zbocza; w trzeciej liczyła się wilgotność i koncentracja wody; a w ostatniej intensywne opady wyróżniały się jako podstawowy czynnik wyzwalający. Usuwając po dwa najsłabsze czynniki w każdej grupie, zespół uprościł modele, zachowując jednocześnie najbardziej informacyjne sygnały.
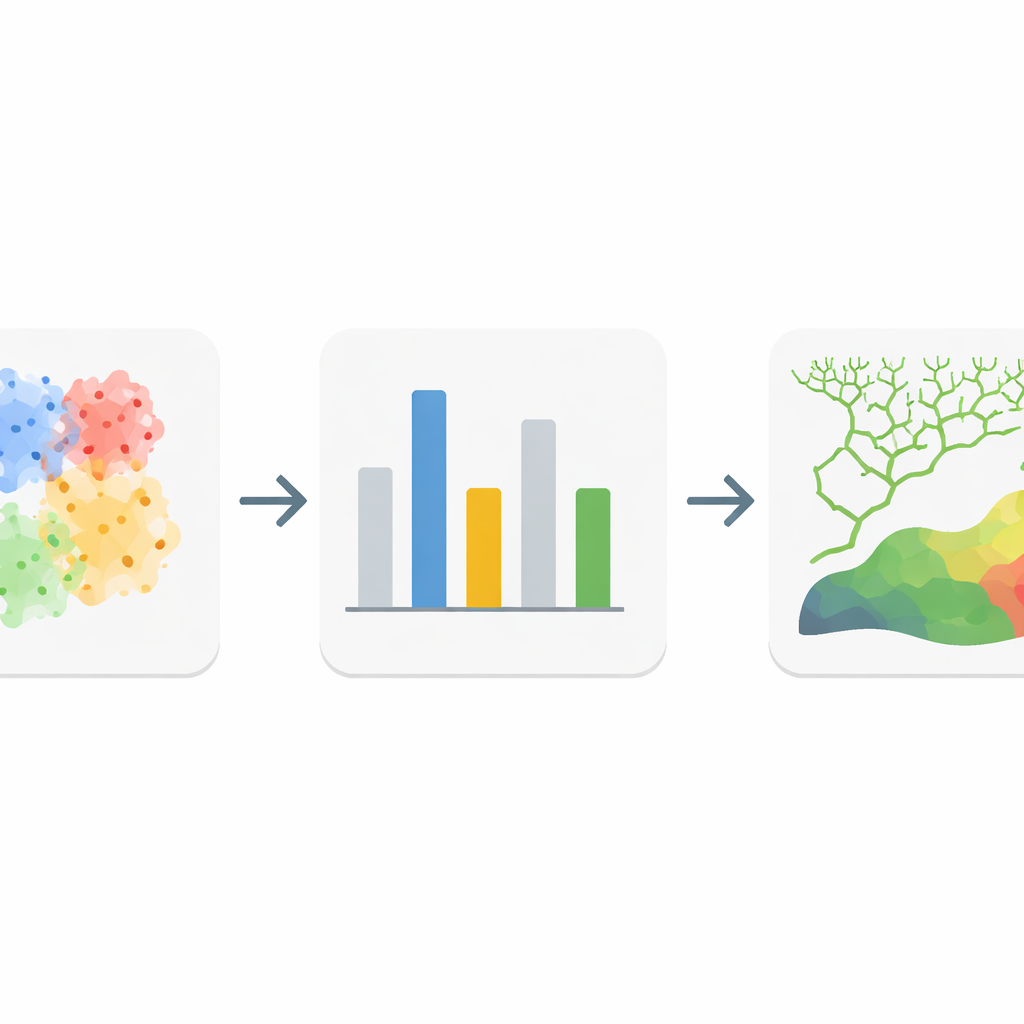
Budowanie bardziej inteligentnych modeli predykcyjnych dla każdego obszaru
Wykorzystując te dostosowane zestawy czynników, badacze wytrenowali popularną metodę uczenia maszynowego — lasy losowe (random forests) — oddzielnie dla całego powiatu i dla każdego z czterech sklastrowanych podregionów. Porównali wersje używające wszystkich czynników z wersjami bazującymi tylko na lokalnie wybranych zmiennych. Jakość oceniano za pomocą kilku standardowych miar klasyfikacji, w tym tego, jak dobrze modele rozróżniały zlewnie z udokumentowanymi lawinami i bez nich. Modele trenowane na lokalnie jednorodnych klastrach konsekwentnie przewyższały pojedynczy model globalny, a usunięcie słabych czynników dodatkowo podnosiło dokładność. Powstałe mapy z modelami spersonalizowanymi i uproszczonymi pokazywały bardziej spójne obszary wysokiego ryzyka wzdłuż uskoków i głębokich dolin oraz bardziej pewne strefy „bardzo niskiego” ryzyka tam, gdzie warunki wyzwalające wyraźnie nie występują.
Co oznaczają wyniki dla bezpieczniejszego planowania
Dla osoby niebędącej specjalistą kluczowa konkluzja jest taka, że traktowanie całego górskiego regionu, jakby zachowywał się jednorodnie, może ukrywać istotne wzorce wpływające na bezpieczeństwo. Badanie pokazuje, że najpierw grupując podobne doliny, a następnie wybierając dla każdej grupy najbardziej istotne czynniki, otrzymuje się czystsze, bardziej realistyczne mapy ryzyka. Takie ulepszone mapy podatności na lawiny błotne umieszczają więcej znanych zdarzeń w obszarach oznaczonych jako umiarkowane lub wysokie ryzyko i wyznaczają szersze strefy rzeczywistego niskiego ryzyka. Dzięki temu są bardziej przydatne przy decyzjach, gdzie budować, które drogi lub wsie wymagają dodatkowej ochrony oraz jak priorytetyzować inwestycje w systemy wczesnego ostrzegania i planowanie awaryjne w regionach zagrożonych osuwiskami.
Cytowanie: Gao, R., Wang, A. & Wu, D. A conditioning factor selection framework considering sample heterogeneity in debris flow susceptibility mapping. Sci Rep 16, 11933 (2026). https://doi.org/10.1038/s41598-026-42978-y
Słowa kluczowe: podatność na lawiny błotne, mapowanie zagrożeń osuwiskowych, uczenie maszynowe w geozagrożeniach, heterogeniczność przestrzenna, zarządzanie ryzykiem górskim