Clear Sky Science · pt
O corpus GaMMA de conversas poliadicas dinamarquesas com dados de olhar, fala e movimento em silêncio e ruído
Por que conversas ruidosas importam
Se você já tentou conversar com amigos em um café movimentado, sabe o quão difícil pode ser acompanhar o fio da conversa. Ainda assim, a maior parte do que os cientistas sabem sobre fala e audição vem de experimentos de laboratório bem controlados com um falante por vez. Este artigo apresenta o corpus GaMMA, uma grande coleção de conversas em grupo em dinamarquês, disponível gratuitamente, gravada em estilo realista com medições detalhadas do que as pessoas dizem, para onde olham, como movimentam a cabeça e quão alto está o burburinho ao redor. O conjunto foi projetado como um campo de testes para pesquisadores que querem desenvolver aparelhos auditivos melhores, dispositivos de comunicação mais inteligentes e modelos mais realistas de como falamos no ruído do dia a dia.

Conversando na festa de coquetel
Os pesquisadores focam em conversas “poliádicas”—quatro pessoas conversando juntas, revezando-se, interrompendo-se, rindo e às vezes falando ao mesmo tempo. Essas situações são um campo natural para o clássico “problema da festa de coquetel”: como os ouvintes conseguem focar em uma voz entre muitas e contra um fundo ruidoso. Conjuntos de dados existentes capturam alguns aspectos desse desafio, mas frequentemente dependem de tarefas roteirizadas, níveis de ruído fixos ou participantes que não se conhecem. O GaMMA foi construído para se aproximar mais da vida real: os 44 participantes eram falantes nativos de dinamarquês conversando com amigos ou familiares, sem tópicos ou papéis atribuídos, e com ruído de fundo que variou desde um zumbido de sala discreto até um burburinho animado semelhante ao de um restaurante e uma condição em que o nível de ruído subia e descia lentamente.
Ver, ouvir e mover-se juntos
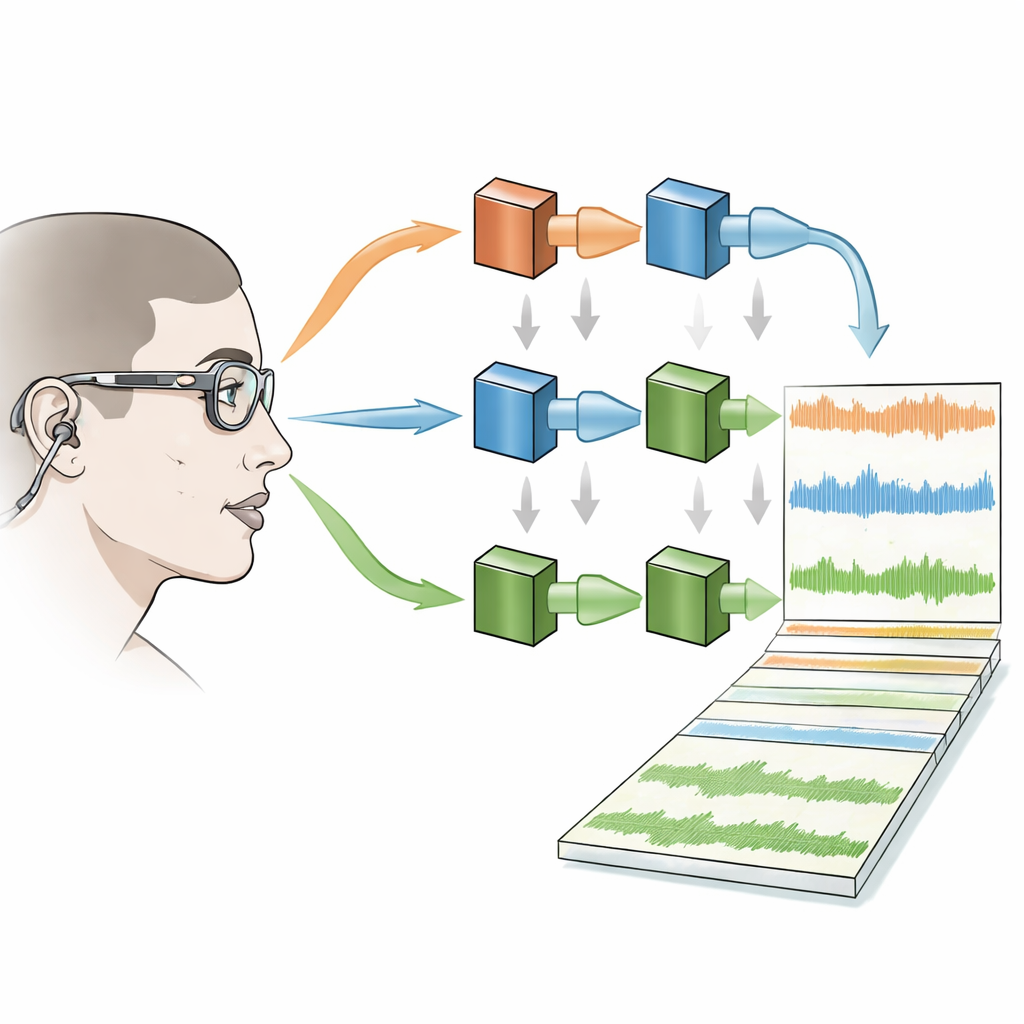
Para capturar a rica mistura de sinais que moldam a conversa face a face, cada pessoa usou três tipos de equipamento: óculos leves de rastreamento ocular para registrar para onde olhavam, microfones pequenos intra-auriculares para capturar o que alcançava seus ouvidos e um microfone pequeno preso à cabeça próximo à boca para gravar claramente a própria fala. Oito câmeras infravermelhas no ambiente rastrearam marcadores nos óculos para que a equipe pudesse reconstruir a posição e a orientação da cabeça de cada falante em 3D. Quatro alto-falantes colocados ao redor da mesa reproduziam o burburinho de fundo em níveis controlados, e a acústica da sala foi medida para que futuros usuários do conjunto de dados saibam exatamente como o som se comportou no espaço.
Fazendo gravações que ainda soam naturais
Um dos objetivos principais do desenho foi evitar alterar como as pessoas falam e escutam. Microfones intra-auriculares padrão podem bloquear o canal auditivo e alterar sutilmente como ouvimos nossa própria voz, o que pode modificar nosso estilo de fala. A equipe, portanto, reconfigurou microfones comerciais de aparelhos auditivos para ficarem no ouvido com obstrução mínima. Usaram uma cabeça de manequim e equipamentos de teste precisos para medir o quanto esses microfones alteravam o som no canal auditivo e projetaram filtros para que o áudio armazenado correspondesse de perto ao que atingiria um tímpano real. Também calibraram os microfones presos à cabeça para que os níveis de fala sejam comparáveis entre os participantes. Respostas a questionários coletadas após as sessões sugerem que, apesar dos equipamentos e do ambiente de laboratório, as pessoas em geral sentiram que suas conversas foram naturais e que o arranjo não foi excessivamente intrusivo.
Limpeza do caos
Gravações brutas de cenas tão movimentadas são bagunçadas: microfones captam ruído da sala, zumbidos de máquinas e as vozes de várias pessoas ao mesmo tempo. Para tornar o corpus mais útil, os autores fornecem tanto versões não processadas quanto “limpas” do áudio. Um algoritmo moderno de aprendizado profundo reduz o burburinho de fundo, e um método de filtragem adaptativa suprime o vazamento das vozes de outros falantes no microfone de cada pessoa. Um detector de atividade de voz então marca quando cada participante está falando. A equipe verificou sistematicamente como essas etapas de processamento afetavam a qualidade do sinal em diferentes condições—como quando apenas o usuário estava falando, quando apenas os outros falavam ou quando várias pessoas se sobrepunham na fala—e constatou que o ruído pôde ser reduzido substancialmente sem prejudicar perceptivelmente a voz principal.
Um kit de ferramentas para estudar conversas reais
Todos os dados estão alinhados no tempo tão precisamente quanto o hardware permite e distribuídos em formatos padrão, juntamente com arquivos de calibração e documentação sobre limitações conhecidas, como pequenas derivações de relógio e lacunas ocasionais no rastreamento ocular. O resultado são mais de nove horas de conversas entre quatro pessoas, cada uma gravada em quatro configurações de ruído diferentes, com fala, olhar e movimento sincronizados. Para cientistas e engenheiros, o GaMMA oferece uma oportunidade rara de estudar como as pessoas deslocam o olhar, ajustam a fala e coordenam a tomada de turno em contextos socialmente reais. Para leitores em geral, a conclusão é que entender e melhorar a comunicação em locais ruidosos requer abraçar a complexidade completa de como falamos, escutamos, olhamos e nos movemos juntos—e este conjunto de dados é um passo significativo nessa direção.
Citação: Dourado, M., Gert Hassager, H., Udesen, J. et al. The GaMMA corpus of Danish polyadic conversations with gaze speech and motion data in quiet and noise. Sci Data 13, 494 (2026). https://doi.org/10.1038/s41597-026-06851-x
Palavras-chave: efeito festa de coquetel, conversa multimodal, fala em ruído, rastreamento do olhar, conjunto de dados para pesquisa em audição