Clear Sky Science · es
El corpus GaMMA de conversaciones policádicas danesas con datos de mirada, habla y movimiento en silencio y ruido
Por qué importan las conversaciones ruidosas
Si alguna vez has intentado charlar con amigos en una cafetería ruidosa, sabes lo difícil que puede ser seguir el hilo de la conversación. Sin embargo, la mayor parte de lo que los científicos saben sobre el habla y la audición procede de experimentos de laboratorio ordenados con un solo hablante a la vez. Este artículo presenta el corpus GaMMA, una colección grande y de acceso libre de conversaciones grupales en danés con estilo de la vida real, grabadas con mediciones detalladas de lo que dicen las personas, a dónde miran, cómo mueven la cabeza y cuán alto es el murmullo ambiental. Está diseñado como un campo de pruebas para investigadores que quieren desarrollar mejores audífonos, dispositivos de comunicación más inteligentes y modelos más realistas de cómo hablamos en el ruido cotidiano.

Hablando en la fiesta del cóctel
Los investigadores se centran en conversaciones “policádicas”: cuatro personas conversando juntas, turnándose, interrumpiéndose, riendo y a veces hablando a la vez. Estas situaciones son un banco de pruebas natural para el clásico “problema del cóctel”: cómo los oyentes logran concentrarse en una voz entre muchas y frente a un fondo ruidoso. Los conjuntos de datos existentes capturan algunos aspectos de este desafío, pero a menudo se basan en tareas guionizadas, niveles de ruido fijos o participantes que no se conocen entre sí. GaMMA se construyó para parecerse más a la vida real: los 44 participantes eran hablantes nativos de danés hablando con amigos o familiares, sin temas ni roles asignados, y con ruido de fondo que iba desde el murmullo de una habitación tranquila hasta un bullicio tipo restaurante y una condición en la que el nivel de ruido subía y bajaba lentamente.
Ver, oír y moverse juntos
Para capturar la rica mezcla de señales que moldean la conversación cara a cara, cada persona llevaba tres tipos de equipos: gafas ligeras con seguimiento ocular para registrar a dónde miraban, pequeños micrófonos intraaurales para capturar lo que llegaba a sus oídos y un micrófono pequeño colocado en la cabeza, cerca de la boca, para grabar su propia voz con claridad. Ocho cámaras infrarrojas en la sala siguieron marcadores en las gafas para que el equipo pudiera reconstruir la posición y la orientación de la cabeza de cada hablante en 3D. Cuatro altavoces colocados alrededor de la mesa reproducían el murmullo de fondo a niveles cuidadosamente controlados, y se midieron las características acústicas de la sala para que los futuros usuarios del conjunto de datos sepan exactamente cómo se comportaba el sonido en el espacio.
Haciendo grabaciones que siguen pareciendo naturales
Un objetivo de diseño importante fue evitar cambiar la forma en que la gente habla y escucha. Los micrófonos intraaurales estándar pueden taponar el conducto auditivo y alterar sutilmente cómo oímos nuestra propia voz, lo que puede cambiar nuestro estilo de habla. Por ello, el equipo reconfiguró micrófonos comerciales de audífono para que se ajustaran en el oído con una obstrucción mínima. Utilizaron una cabeza maqueta y equipos de prueba precisos para medir cuánto alteraban estos micrófonos el sonido en el conducto auditivo y diseñaron filtros para que el audio almacenado corresponda estrechamente a lo que alcanzaría un tímpano real. También calibraron los micrófonos de cabeza para que los niveles de habla fueran comparables entre participantes. Las respuestas a cuestionarios recogidas tras las sesiones sugieren que, a pesar del equipo y del entorno de laboratorio, las personas en general sintieron que sus conversaciones eran naturales y que la configuración no resultó excesivamente intrusiva.
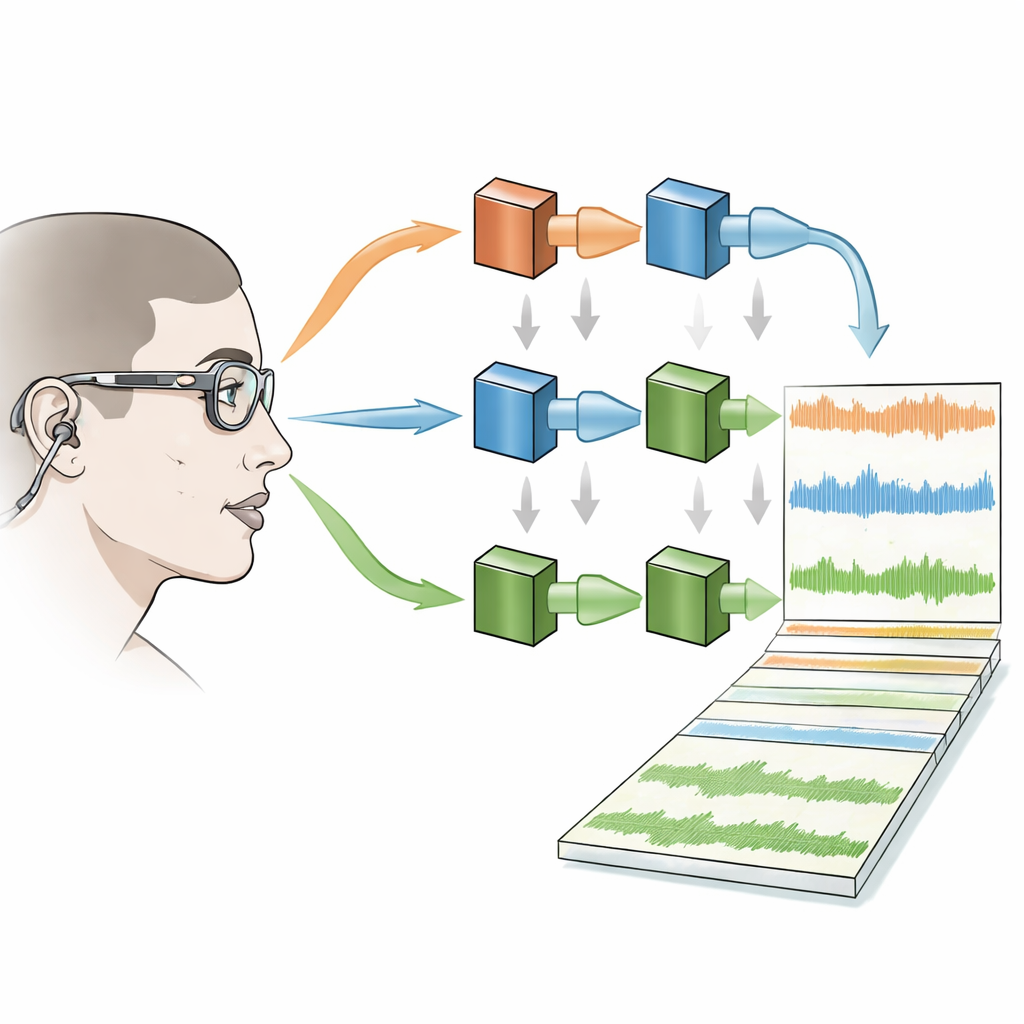
Limpieza del caos
Las grabaciones sin procesar de escenas tan concurridas son desordenadas: los micrófonos captan ruido de sala, zumbidos de máquinas y las voces de varias personas a la vez. Para hacer el corpus más útil, los autores proporcionan versiones tanto sin procesar como “limpiadas” del audio. Un algoritmo moderno de aprendizaje profundo reduce el murmullo de fondo y un método de filtrado adaptativo suprime la filtración de las voces de otros hablantes en el micrófono de cada persona. Un detector de actividad de voz marca entonces cuándo habla cada participante. El equipo comprobó sistemáticamente cómo estos pasos de procesamiento afectaban la calidad de la señal en diferentes condiciones —por ejemplo, cuando solo hablaba el usuario del micrófono, cuando hablaban solo los demás o cuando varias personas se solapaban en el habla— y encontró que el ruido podía reducirse sustancialmente sin perjudicar de forma apreciable la voz principal.
Un kit de herramientas para estudiar conversaciones reales
Todos los datos están sincronizados temporalmente con la máxima precisión que permite el hardware y se distribuyen en formatos estándar, junto con archivos de calibración y documentación sobre limitaciones conocidas, como pequeñas desviaciones de reloj y huecos ocasionales en el seguimiento ocular. El resultado son más de nueve horas de conversaciones de cuatro personas, cada una grabada en cuatro ajustes de ruido diferentes, con habla, mirada y movimiento sincronizados. Para científicos e ingenieros, GaMMA ofrece una oportunidad rara de estudiar cómo las personas cambian la mirada, ajustan el habla y coordinan el turno de palabra en entornos verdaderamente sociales. Para lectores no especializados, la conclusión es que entender y mejorar la comunicación en lugares ruidosos requiere abrazar la complejidad completa de cómo hablamos, escuchamos, miramos y nos movemos juntos, y este conjunto de datos es un paso significativo hacia ese objetivo.
Cita: Dourado, M., Gert Hassager, H., Udesen, J. et al. The GaMMA corpus of Danish polyadic conversations with gaze speech and motion data in quiet and noise. Sci Data 13, 494 (2026). https://doi.org/10.1038/s41597-026-06851-x
Palabras clave: efecto cóctel, conversación multimodal, habla en ruido, seguimiento de la mirada, conjunto de datos para investigación auditiva