Clear Sky Science · en
The GaMMA corpus of Danish polyadic conversations with gaze speech and motion data in quiet and noise
Why noisy conversations matter
If you have ever tried to chat with friends in a bustling café, you have experienced how hard it can be to follow the thread of conversation. Yet most of what scientists know about speech and hearing still comes from tidy lab experiments with one talker at a time. This article introduces the GaMMA corpus, a large, freely available collection of real-life–style group conversations in Danish, recorded with fine-grained measurements of what people say, where they look, how they move their heads, and how loud the surrounding babble is. It is designed as a playground for researchers who want to build better hearing aids, smarter communication devices, and more realistic models of how we talk in everyday noise.

Talking at the cocktail party
The researchers focus on “polyadic” conversations—four people chatting together, taking turns, interrupting, laughing, and sometimes talking over each other. These situations are a natural testbed for the classic “cocktail party problem”: how listeners manage to focus on one voice among many and against a noisy background. Existing datasets capture some aspects of this challenge, but they often rely on scripted tasks, fixed noise levels, or participants who do not know one another. GaMMA was built to feel closer to real life: all 44 participants were native Danish speakers talking with friends or family, with no assigned topics or roles, and with background noise that ranged from quiet room hum to lively restaurant-like babble and a condition where the noise level slowly rose and fell.
Seeing, hearing, and moving together
To capture the rich mix of signals that shape face-to-face conversation, each person wore three kinds of equipment: light eye-tracking glasses to record where they were looking, tiny in-ear microphones to capture what reached their ears, and a small head-worn microphone near the mouth to record their own speech clearly. Eight infrared cameras in the room tracked markers on the glasses so the team could reconstruct each talker’s head position and orientation in 3D. Four loudspeakers placed around the table played the background babble at carefully controlled levels, and the acoustics of the room were measured so that future users of the dataset know exactly how sound behaved in the space.
Making recordings that still feel natural
A major design goal was to avoid changing how people speak and listen. Standard in-ear microphones can block the ear canal and subtly alter how we hear our own voice, which may change our speaking style. The team therefore reconfigured commercial hearing-aid microphones to sit in the ear with minimal blockage. They used a mannequin head and precise test equipment to measure how much these microphones altered sound in the ear canal and designed filters so that the stored audio corresponds closely to what would reach a real eardrum. They also calibrated the head-worn microphones so that speech levels are comparable across participants. Questionnaire responses collected after the sessions suggest that, despite the gear and the lab setting, people generally felt their conversations were natural and that the setup was not overly intrusive.
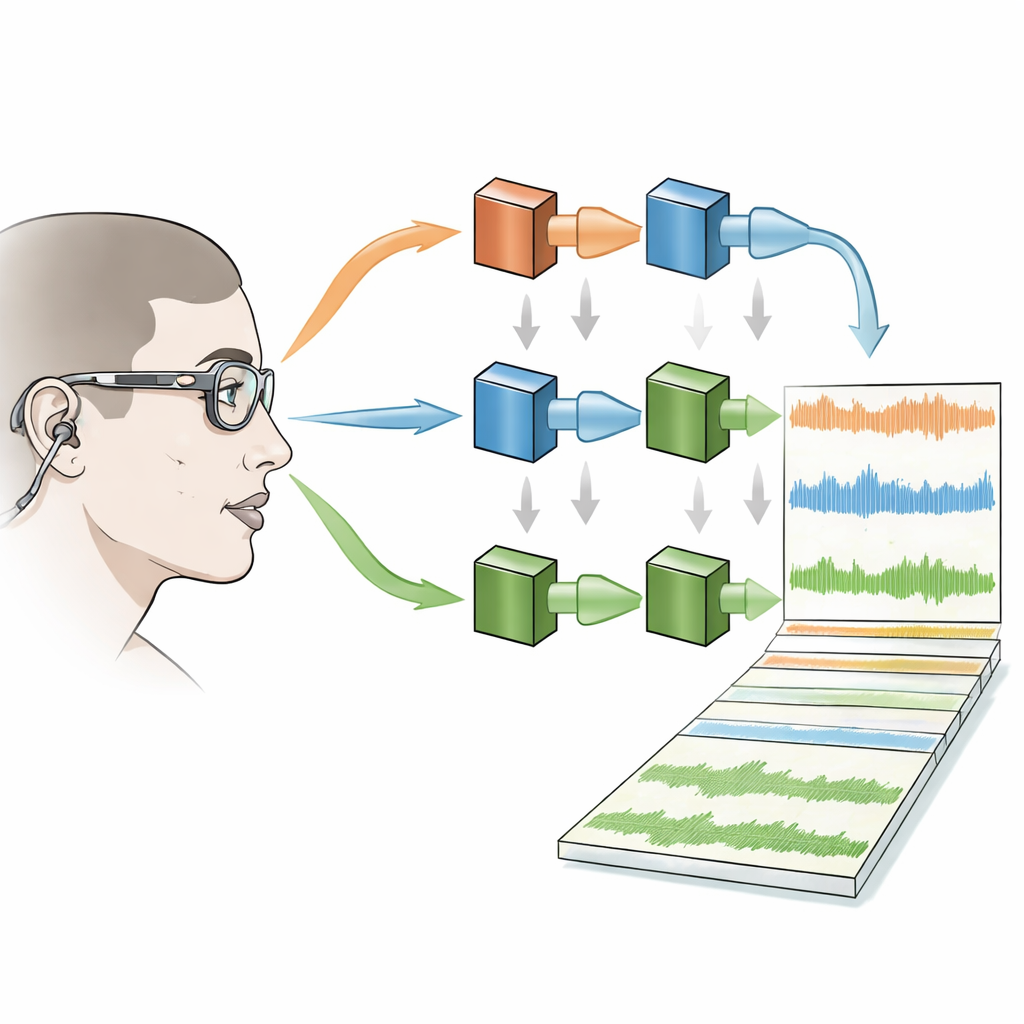
Cleaning up the chaos
Raw recordings from such busy scenes are messy: microphones pick up room noise, machine hum, and the voices of several people at once. To make the corpus more useful, the authors provide both unprocessed and “cleaned” versions of the audio. A modern deep-learning algorithm reduces background babble, and an adaptive filtering method suppresses bleeding of other talkers’ voices into each person’s microphone. A voice-activity detector then marks when each participant is speaking. The team systematically checked how these processing steps affected signal quality under different conditions—such as when only the wearer was talking, when only others were talking, or when several people overlapped in speech—and found that noise could be reduced substantially without noticeably harming the main voice.
A toolkit for studying real conversations
All data are time-aligned as closely as the hardware allows and distributed in standard formats, along with calibration files and documentation about known limitations such as tiny clock drift and occasional gaps in eye-tracking. The result is more than nine hours of four-person conversations, each recorded at four different noise settings, with synchronized speech, gaze, and motion. For scientists and engineers, GaMMA offers a rare chance to study how people shift their gaze, adjust their speech, and coordinate turn-taking in truly social settings. For lay readers, the takeaway is that understanding and improving communication in noisy places requires embracing the full complexity of how we talk, listen, look, and move together—and this dataset is a significant step toward that goal.
Citation: Dourado, M., Gert Hassager, H., Udesen, J. et al. The GaMMA corpus of Danish polyadic conversations with gaze speech and motion data in quiet and noise. Sci Data 13, 494 (2026). https://doi.org/10.1038/s41597-026-06851-x
Keywords: cocktail party effect, multimodal conversation, speech in noise, gaze tracking, hearing research dataset