Clear Sky Science · it
Il corpus GaMMA di conversazioni politeiche danesi con dati di sguardo, parola e movimento in silenzio e rumore
Perché le conversazioni rumorose contano
Se avete mai cercato di parlare con amici in un caffè affollato, sapete quanto sia difficile seguire il filo della conversazione. Eppure la maggior parte di ciò che gli scienziati sanno su parola e udito deriva ancora da esperimenti di laboratorio ordinati con un solo oratore alla volta. Questo articolo presenta il corpus GaMMA, un’ampia raccolta liberamente disponibile di conversazioni di gruppo in stile reale in danese, registrate con misurazioni dettagliate di ciò che le persone dicono, dove guardano, come muovono la testa e quanto è forte il brusio circostante. È pensato come un campo di gioco per i ricercatori che vogliono costruire protesi acustiche migliori, dispositivi di comunicazione più intelligenti e modelli più realistici di come parliamo nel rumore quotidiano.

Parlare alla festa in casa
I ricercatori si concentrano sulle conversazioni “politeiche”—quattro persone che chiacchierano insieme, si alternano, si interrompono, ridono e talvolta parlano simultaneamente. Queste situazioni sono un banco di prova naturale per il classico “problema della festa in casa”: come gli ascoltatori riescono a concentrarsi su una voce tra molte e contro uno sfondo rumoroso. I dataset esistenti catturano alcuni aspetti di questa sfida, ma spesso si basano su compiti sceneggiati, livelli di rumore fissi o partecipanti che non si conoscono tra loro. GaMMA è stato costruito per avvicinarsi di più alla vita reale: tutti i 44 partecipanti erano madrelingua danesi che parlavano con amici o familiari, senza argomenti o ruoli assegnati, e con rumore di fondo che variava dal ronzio di una stanza tranquilla a un vivace brusio tipo ristorante e una condizione in cui il livello di rumore saliva e scendeva lentamente.
Vedere, udire e muoversi insieme
Per catturare il ricco insieme di segnali che plasmano la conversazione faccia a faccia, ogni persona indossava tre tipi di apparecchiatura: occhiali leggeri per il tracciamento oculare per registrare dove guardava, minuscoli microfoni intrauricolari per catturare ciò che raggiungeva le orecchie e un piccolo microfono posizionato sulla testa vicino alla bocca per registrare chiaramente il proprio parlato. Otto telecamere a infrarossi nella stanza tracciavano i marcatori sugli occhiali in modo che il team potesse ricostruire la posizione e l’orientamento della testa di ogni oratore in 3D. Quattro altoparlanti posizionati intorno al tavolo riproducevano il brusio di fondo a livelli controllati con cura, e l’acustica della stanza è stata misurata in modo che i futuri utilizzatori del dataset sappiano esattamente come si comportava il suono nello spazio.
Fare registrazioni che rimangano naturali
Un obiettivo di progettazione importante era evitare di cambiare il modo in cui le persone parlano e ascoltano. I microfoni intrauricolari standard possono ostruire il condotto uditivo e alterare leggermente come percepiamo la nostra voce, il che può modificare lo stile di parola. Il team ha quindi riconfigurato microfoni commerciali per apparecchi acustici in modo che stessero nell’orecchio con un’ostruzione minimale. Hanno usato una testa manichino e attrezzature di prova precise per misurare quanto questi microfoni alterassero il suono nel condotto uditivo e hanno progettato filtri in modo che l’audio archiviato corrispondesse strettamente a ciò che raggiungerebbe un vero timpano. Hanno inoltre calibrato i microfoni indossati in testa in modo che i livelli di parlato siano comparabili tra i partecipanti. Le risposte ai questionari raccolte dopo le sessioni suggeriscono che, nonostante l’attrezzatura e l’ambiente di laboratorio, le persone in generale percepivano le conversazioni come naturali e che l’allestimento non fosse eccessivamente invasivo.
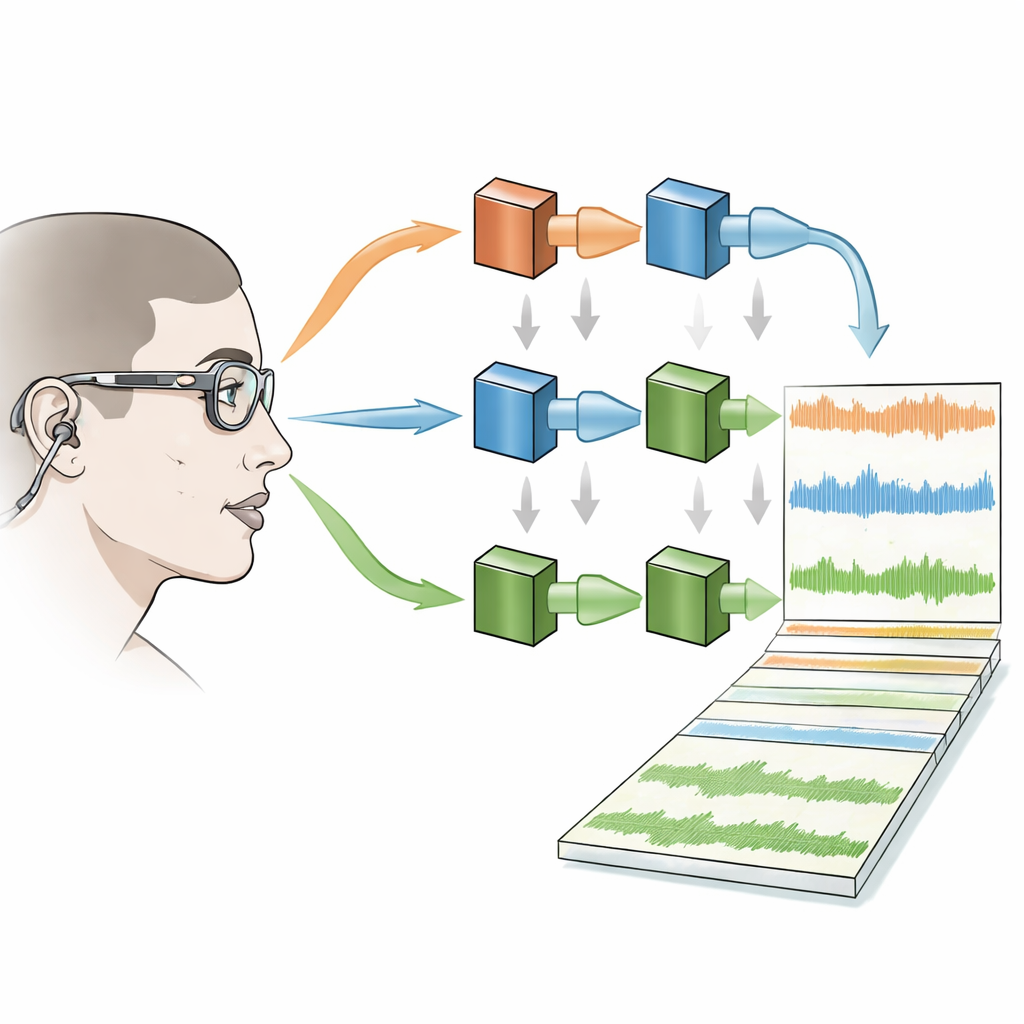
Ripulire il caos
Le registrazioni grezze di scene così affollate sono disordinate: i microfoni catturano il rumore della stanza, il ronzio delle macchine e le voci di più persone contemporaneamente. Per rendere il corpus più utile, gli autori forniscono versioni sia non elaborate sia “pulite” dell’audio. Un moderno algoritmo di deep learning riduce il brusio di fondo e un metodo di filtraggio adattivo sopprime la contaminazione delle voci di altri parlanti nel microfono di ciascuna persona. Un rivelatore di attività vocale poi marca quando ogni partecipante sta parlando. Il team ha controllato sistematicamente come questi passaggi di elaborazione influenzassero la qualità del segnale in diverse condizioni—come quando parlava solo il portatore, quando parlavano solo gli altri o quando più persone si sovrapponevano nel parlato—e ha rilevato che il rumore poteva essere ridotto sostanzialmente senza compromettere in modo evidente la voce principale.
Un kit di strumenti per studiare le conversazioni reali
Tutti i dati sono sincronizzati nel tempo quanto consentito dall’hardware e distribuiti in formati standard, insieme ai file di calibrazione e alla documentazione sulle limitazioni note come piccoli scostamenti di clock e occasionali gap nel tracciamento oculare. Il risultato è più di nove ore di conversazioni a quattro persone, ciascuna registrata in quattro diverse impostazioni di rumore, con parlato, sguardo e movimento sincronizzati. Per scienziati e ingegneri, GaMMA offre una rara opportunità di studiare come le persone spostano lo sguardo, adattano il parlato e coordinano i turni in contesti veramente sociali. Per i lettori non specialisti, la conclusione è che comprendere e migliorare la comunicazione nei luoghi rumorosi richiede l’abbraccio della piena complessità di come parliamo, ascoltiamo, guardiamo e ci muoviamo insieme—e questo dataset è un passo significativo verso quell’obiettivo.
Citazione: Dourado, M., Gert Hassager, H., Udesen, J. et al. The GaMMA corpus of Danish polyadic conversations with gaze speech and motion data in quiet and noise. Sci Data 13, 494 (2026). https://doi.org/10.1038/s41597-026-06851-x
Parole chiave: effetto festa in casa, conversazione multimodale, parlato nel rumore, tracciamento dello sguardo, dataset per la ricerca sull'udito