Clear Sky Science · pl
Efektywne pamięciowo uczenie sieci rejestracji obrazów 3D mózgu z użyciem PatchMorph
Rozumienie wielu skanów mózgu
Współczesne badania mózgu opierają się na porównywaniu trójwymiarowych skanów od wielu osób i zwierząt, ale każdy obraz mózgu różni się nieco rozmiarem, kształtem i rozdzielczością. Dokładne ich wyrównanie bez potrzeby korzystania z ogromnych zasobów obliczeniowych to duże wyzwanie. Artykuł przedstawia PatchMorph — nowy sposób dopasowywania dużych obrazów 3D mózgu, który radykalnie zmniejsza zużycie pamięci przy zachowaniu, a nawet poprawie dokładności, otwierając drogę do analiz większych i bogatszych zbiorów danych mózgowych.
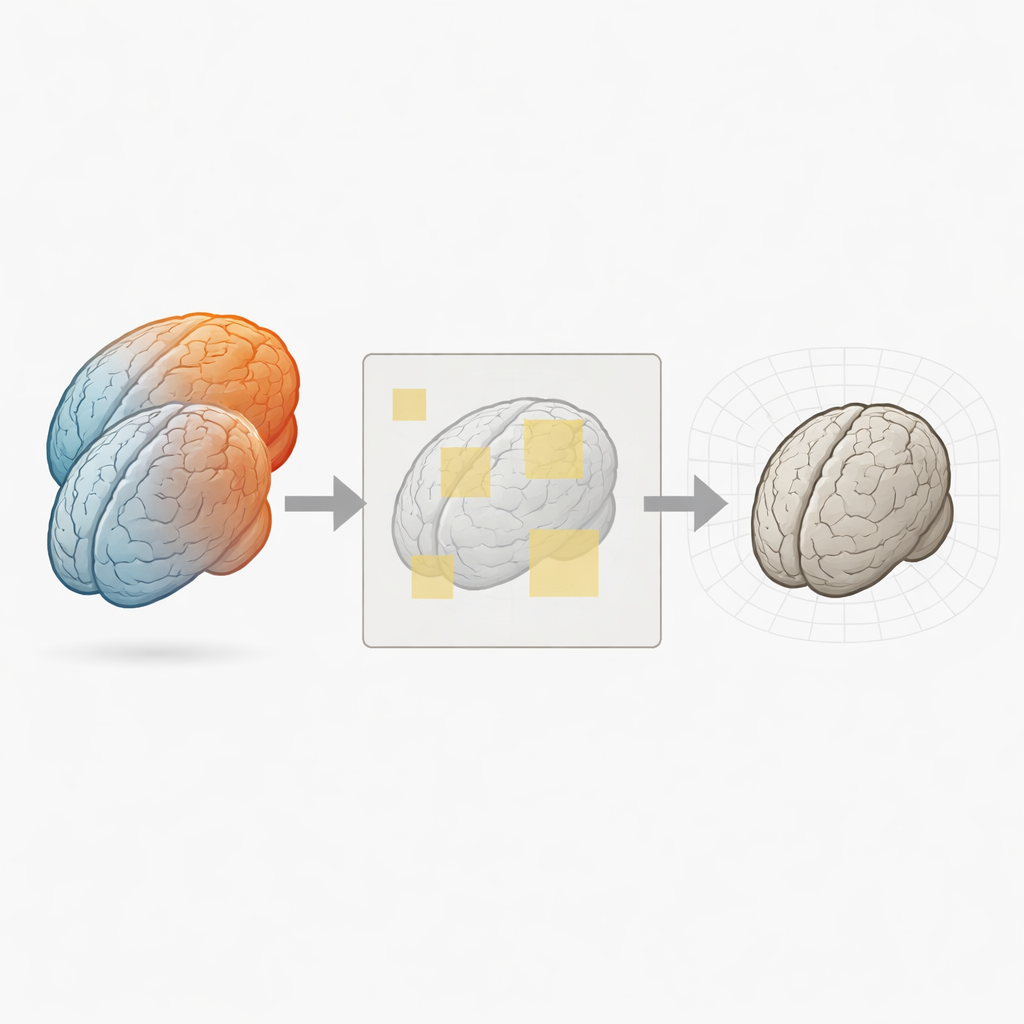
Dlaczego wyrównywanie mózgów jest takie trudne
Aby porównać mózgi, naukowcy najpierw „rejestrują” jeden obraz 3D względem drugiego, deformując jedną objętość tak, by odpowiadające sobie struktury się pokrywały. Klasyczne narzędzia robią to, stopniowo dopasowując pole deformacji aż do maksymalizacji miary podobieństwa między obrazami. Nowsze metody uczenia głębokiego, takie jak VoxelMorph, uczą się przewidywać tę deformację od razu, co znacznie przyspiesza rejestrację. Jednak większość tych sieci oczekuje, że oba obrazy wejściowe będą miały tę samą siatkę i rozdzielczość, a często trzeba przetwarzać całe wolumeny 3D naraz. W miarę wzrostu rozmiarów obrazów i złożoności modeli, zapotrzebowanie na pamięć graficzną szybko rośnie, zmuszając badaczy do zmniejszania, przycinania lub intensywnego wstępnego przetwarzania danych.
Przeglądanie mózgów kawałek po kawałku
PatchMorph rozwiązuje wąskie gardło przez to, że nigdy nie ładuje całych wolumenów 3D do sieci jednocześnie. Zamiast tego operuje na małych trójwymiarowych „łatkach” pobieranych w przestrzeni odniesienia obejmującej obraz statyczny. Na poziomie ogólnym metoda umieszcza stosunkowo duże łatki na całym mózgu, ekstrahuje odpowiadające im fragmenty z obrazu ruchomego przy użyciu precyzyjnych transformacji współrzędnych i podaje je do kompaktowej sieci rejestracyjnej. Sieć przewiduje, jak każda łatka ma się przesunąć i zdeformować, by jej lokalna zawartość pasowała. Wiele takich lokalnych przewidywań jest następnie rozrzucanych z powrotem do globalnego pola deformacji, z użyciem płynnej interpolacji, tak by cała deformacja mózgu pozostała ciągła.
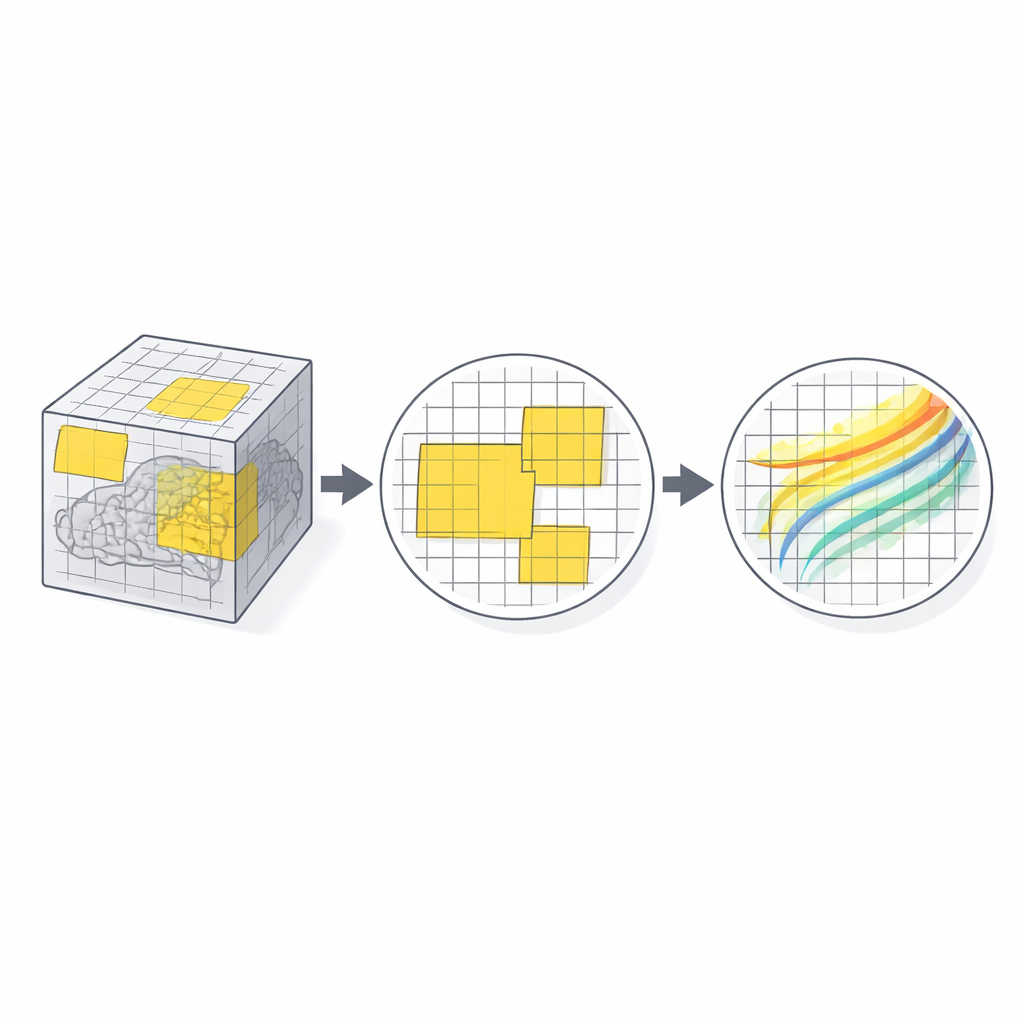
Od dużych łat do drobnych detali
PatchMorph działa wieloskalowo, od grubszych do drobniejszych poziomów. Na pierwszej skali łatka obejmuje duży obszar mózgu przy niskiej rozdzielczości, wychwytując szerokie niedopasowania jak ogólny rozmiar czy pozycja. Na kolejnych skalach nowe łatki „przybliżają” się do podregionów wcześniej pobranych łat, ale zawsze utrzymują tę samą liczbę wokseli na łatkę w pamięci. Oznacza to, że drobniejsze skale zwiększają fizyczną szczegółowość bez zwiększania zapotrzebowania pamięciowego. Pozycje łat na niższych poziomach są wybierane losowo w obrębie ich łat macierzystych, więc metoda nie koncentruje się jedynie na środkach łat, lecz stopniowo uczy się także wyrównywać struktury peryferyjne. Na kolejnych skalach oszacowane deformacje kumulowane są do jednego globalnego pola, udoskonalanego etapami, a jednocześnie zawsze spójnego przestrzennie.
Praca na rzeczywistych danych mózgowych
Autorzy przetestowali PatchMorph na dwóch wymagających zbiorach danych: skanach T1 MRI ludzkiego mózgu z projektu MindBoggle oraz obrazach mózgu koto-papuzek (marmoset) o wysokiej rozdzielczości uzyskanych metodą seryjnej mikroskopii dwufotonowej. Obrazy te różnią się rozmiarami tablic, orientacją, a czasem także odległością między wokselami — warunki, które obciążają konwencjonalne sieci. PatchMorph dorównał lub przewyższył zaawansowane metody rejestracji oparte na uczeniu głębokim pod względem pokrycia między oznaczonymi regionami mózgu, jednocześnie utrzymując bardzo niskie wskaźniki błędów topologicznych (nierealistycznych zagięć w polu deformacji). Co istotne, przy trenowaniu z wykorzystaniem bazowych architektur transformatorowych PatchMorph zmniejszył pamięć potrzebną dla obrazów 256³ wokseli z około 40 GB do poniżej 10 GB, bez utraty dokładności.
Szybkość, kompromisy i przyszłe zastosowania
Ponieważ PatchMorph musi ekstrahować i ponownie łączyć wiele łat, jest nieco wolniejszy podczas inferencji niż jednorazowe sieci przetwarzające pełne wolumeny, choć wciąż znacznie szybszy niż tradycyjne narzędzia iteracyjne. W zamian potrafi bezpośrednio obsługiwać duże, wysokorozdzielcze i nierówno próbkowane obrazy w ich natywnej przestrzeni oraz umożliwia stosowanie różnych architektur bazowych, od prostych sieci splotowych po zaawansowane transformatory. Dzięki temu łatwiej jest zastosować potężne modele uczenia głębokiego w rzeczywistych badaniach obrazowania mózgu, które wcześniej nie mieściły się w pamięci. W praktyce PatchMorph pokazuje, że myślenie w kategoriach łatek zamiast całych wolumenów pozwala dokładnie, wydajnie i na skalę wcześniej nieosiągalną wyrównywać złożone dane 3D mózgu.
Cytowanie: Skibbe, H., Byra, M., Watakabe, A. et al. Memory efficient training for 3D brain image registration networks using PatchMorph. Sci Rep 16, 14386 (2026). https://doi.org/10.1038/s41598-026-44858-x
Słowa kluczowe: rejestracja obrazów mózgu, uczenie głębokie, obrazowanie medyczne, 3D MRI, PatchMorph